
Abstract
Fully-convolutional neural networks (FCN) were proven to be effective for predicting the instantaneous state of a fully-developed turbulent flow at different wall-normal locations using quantities measured at the wall. In Guastoni et al. (J Fluid Mech 928:A27, 2021. https://doi.org/10.1017/jfm.2021.812), we focused on wall-shear-stress distributions as input, which are difficult to measure in experiments. In order to overcome this limitation, we introduce a model that can take as input the heat-flux field at the wall from a passive scalar. Four different Prandtl numbers \(Pr = \nu /\alpha = (1,2,4,6)\) are considered (where \(\nu \) is the kinematic viscosity and \(\alpha \) is the thermal diffusivity of the scalar quantity). A turbulent boundary layer is simulated since accurate heat-flux measurements can be performed in experimental settings: first we train the network on aptly-modified DNS data and then we fine-tune it on the experimental data. Finally, we test our network on experimental data sampled in a water tunnel. These predictions represent the first application of transfer learning on experimental data of neural networks trained on simulations. This paves the way for the implementation of a non-intrusive sensing approach for the flow in practical applications.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Several approaches have been proposed over the years in order to perform a reliable non-local estimation of the velocity field in wall-bounded flows. When considering linear methods, an optimal solution can be obtained using extended proper orthogonal decomposition [EPOD, 7], which is equivalent to linear stochastic estimation (LSE, [10]). Recent works on transfer functions [35] have highlighted the benefits of using non-linear methods. In this regard, neural-network models have shown excellent results in monitoring the instantaneous state of the flow using quantities measured at the wall since the seminal work of Milano and Koumoutsakos [27] and as recently highlighted in our contributions (see,e.g. [13,14,15,16]). Fully-convolutional networks (FCNs) provide an accurate reconstruction of the flow field at a given wall-normal location, when highly-resolved wall-shear-stress fields are used as inputs [14]. Other architectures have been tested in the literature for the same task, e.g. super-resolution generative adversarial networks (SR-GANs, [16]). While it is straightforward to measure the wall-shear-stress components in direct numerical simulations (DNSs), sampling the same quantities in an experiment is much more difficult, in particular if a high resolution is required. This highlights the need of other input quantities, whose acquisition is more practical in experiments. In particular, [1] report significant similarities between the wall-normal heat flux fluctuations and the streamwise wall-shear-stress fluctuations. Several examples in the literature demonstrate the feasibility of time-resolved convective heat flux measurements [17, 19, 29, 32], hence this quantity is used by our neural-network model to reconstruct the flow field. Previously, [23] used convolutional neural networks (CNNs) to predict the instantaneous wall-normal heat flux from the two wall-shear-stress components. Their approach still relies on the knowledge of the shear stresses at the wall and both the measurements and the predictions are at the same location. In this work, on the other hand, we consider input measurements at the wall and target flow-state estimation above the wall.
In this work we aim to use FCNs to reconstruct the experimental data sampled in the water-tunnel facility at Universidad Carlos III de Madrid using InfraRed (IR) thermography for convective heat transfer [5] and Particle Image Velocimetry (PIV, [31]) for velocity-field measurements. Despite machine-learning-based control having been tested in experimental settings with promising results [12], it is difficult to acquire from experimental facilities the large datasets that are needed to train neural network models. Additionally, experimental uncertainty needs to be taken into account and the possibility to assess the effect of the spatial resolution of the samples is limited. For these reasons, in this study, we perform the training of the networks using the data obtained from numerical flow simulations. A zero-pressure-gradient turbulent boundary layer is simulated, matching the experimental values in terms of Prandtl and Reynolds numbers. First, we consider flow fields sampled from DNSs at full resolution, performing predictions of increasing difficulty depending on the inputs of the neural network. Second, we cut, filter and downsample the DNS data to match the characteristics of the experimental data. The neural-network models are optimized using these synthetic experimental data. Finally, the trained neural networks are tested on the data from the water tunnel.
After this introduction, the paper is organized as follows. In Sect. 2, the setup of the numerical simulation of a zero-pressure-gradient turbulent boundary layer is described, along with the number of fields that are sampled for training, validation and testing. The experimental setup is also described in this section. In Sect. 3, the neural-network architecture and training details are reported, as well as the preparation of DNS data to mimick the experimental ones. In Sect. 4, the performance of several neural networks with varying numbers of convolutional layers is compared for predictions with different inputs. The capability of the neural networks to reconstruct the synthetic and real experimental data is also analyzed. Finally, concluding remarks and future research directions can be found in Sect. 5.
2 Dataset
2.1 Numerical dataset
The direct numerical simulation (DNS) from which the measurements and the target output fields are sampled is performed using the pseudo-spectral code SIMSON [8]. While our previous work [14] focused on a fully-developed flow, namely a turbulent open-channel flow, in this work we simulate a zero-pressure-gradient (ZPG) turbulent boundary layer (TBL). The inflow condition for the velocity is a laminar profile. A random trip forcing is applied to trigger the transition to a turbulent boundary layer. A fringe forcing is applied at the outflow in order to achieve periodicity at the boundary, as requested by the solution method. Four passive scalars representing the temperature of the fluid are also simulated. We consider Prandtl number \(Pr=(1,2,4,6)\), indicating them with \((\theta _1,\theta _2,\theta _3,\theta _4)\), respectively. For all the passive scalar we impose an isothermal wall boundary condition \(\theta _i |_{y=0} = 0\), for \(i=1,2,3,4\). The highest Prandtl number \(Pr=6\) is the result of a trade-off between the value that can be measured in our experimental setting and the computational cost of simulating such a flow with a DNS. The higher the Prandtl number, the smaller the thermal boundary layer, increasing the simulation resolution required to resolve all the relevant turbulent scales. The use of the same model for different Prandtl numbers allows us to investigate how the different thermal diffusivity influences the reconstruction performance. The choice of a spatially-developing flow implies an additional degree of complexity in the predictions with respect to the previously-studied channel flow, since the friction Reynolds number \(Re_{\tau }\) (based on the boundary-layer thickness and the friction velocity \(u_{\tau }=\sqrt{\tau _w/\rho }\), where \(\tau _w\) is the wall-shear stress and \(\rho \) is the fluid density) increases with the streamwise location x within the sampled fields. The highest considered \(Re_{\tau }\) is 396, which is similar to the \(Re_\tau \) of our experimental setting. Few numerical simulation results are reported in the literature with a similar highest Prandtl number Pr and friction Reynolds number \(Re_{\tau }\). [2] simulated a channel flow resolving all the turbulent scales with \(Pr=6\) and \(Re_{\tau }=500\). [25] performed a DNS of a turbulent channel flow at lower Reynolds number \(Re_{\tau }=395\), however, the maximum considered Prandtl number was \(Pr=7\). A statistical characterization of the scalars and the comparison with the results from the previously-cited works are available in the work by [6].
In our simulations, we sample the wall-shear-stress components, as well as the wall pressure. Note that we considered a reference friction velocity at the middle of the computational domain, which implies that the actual inner-scaled location that is actually sampled slightly varies along the streamwise direction. However, the variation is within \(\pm 0.1y^{+}\). Here the ‘+’ denotes viscous scaling, i.e. in terms of the friction velocity \(u_{\tau }\) or the viscous length \(\ell ^{*}=\nu / u_{\tau }\) (where \(\nu \) is the fluid kinematic viscosity). Furthermore, the flux of a passive scalars \(\partial \theta _i/\partial y\) is sampled at the wall. The velocity-fluctuation fields (whose streamwise, wall-normal and spanwise components are denoted as u, v and w, respectively) are sampled at four wall-normal locations: \(y^{+}=15,30,50\) and 100.
Note that the sampled fields also include both the initial, transitional part of the flow and the final region affected by the fringe forcing. On the other hand, the neural-network models predict only a portion of the field. Depending on the size, we can identify two different types of samples, as shown in Fig. 1: full domain (FD) samples have streamwise and spanwise lengths of \(x_s/\delta ^*_0=600\) and \(z_s/\delta ^*_0=50\), respectively. Here \(\delta ^*_0\) is the displacement thickness of the laminar boundary layer at the inflow, defined as:
with U indicating the free-stream velocity. The samples do not include the initial (\(x/\delta ^*_0<200\)) and the final region (\(800<x/\delta ^*_0<1000\)). When the streamwise length of the samples is reduced to \(x_s/\delta ^*_0=300\), we refer to them as half-domain (HD) samples. The grid points considered in the FD case are \(N_{\textrm{x,s}} \times N_{\textrm{z,s}} = 1960 \times 320\), while for HD they are \(980 \times 320\).

Representation of full domain (FD) and half domain (HD) in a sampled streamwise velocity-fluctuation field at \(y^{+}=30\)
In order to obtain a sufficiently large number of fields, five different realizations of the simulation are performed using five trip-forcing at the same location, but with different random seeds. The training dataset includes 7474 samples obtained from three of the five simulations. The validation dataset consists of 2195 samples, taken from a separate DNS to avoid unwanted correlations with the training dataset. The test dataset is obtained from the remaining simulation, it includes 1973 samples and the overall sampled time for testing is sufficient to obtain converged turbulence statistics.
2.2 Experimental dataset
This section describes the experimental setup designed to obtain a ZPG turbulent boundary layer, as well as the measurement techniques employed to provide simultaneous measurements of the flow field and wall heat transfer maps. The heat-transfer model and measurement uncertainties are also discussed briefly. Figure 2 shows a schematic of the experimental setup.
The experiments were conducted in the water tunnel facility of the Department of Aerospace Engineering at the Universidad Carlos III de Madrid, with a rectangular test section of \(0.5\times 0.55\) m\(^2\), a length of 2.5 m, a speed ranged from 0.1 to 2 m/s, and the free-stream turbulence intensity below \(1\%\). For the experiments, the tunnel was operated in an open channel configuration, with a free-stream velocity, \(U_\infty \), set at 0.24 m/s. The turbulent boundary layer developes on a vertically-mounted flat plate spanning the full length of the test section. Turbulent-flow transition is induced by a zigzag-trip turbulator of 10 mm width and 2 mm thickness, which is mounted 120 mm downstream of the leading edge, thus 1080 mm upstream of the heat transfer sensor. The tripping is followed by a V-shape embossed tape. A full description of the characteristics of the flat plate is reported in the work by [11].
Convective heat transfer measurements were carried out using a flush-mounted heated-thin-foil sensor embedded in the wall and an IR camera used as a temperature transducer. The IR images are recorded at 59 Hz with a FLIR SC4000 camera. The noise equivalent temperature difference (NETD) of the sensor is 18 mK. The spatial resolution is approximately 1.1 pixels per mm. The heat transfer sensor was installed on the flat plate at approximately 1.2 m from the leading edge. The TBL parameters, estimated with Ensemble Particle Tracking Velocimetry as in [34], are reported in Table 1.
The sensor, made of a thin constantan foil of \(28\mu \)m thickness, was heated by Joule effect, providing a constant heat flux. For a detailed description of this sensor the reader is referred to the work by [11]. Measuring the input heat flux along with the foil temperature allows us to estimate the convective heat transfer coefficient (h) between the foil and the flow from the unsteady energy balance on the foil as in the work by [28] and [32]. Taking into account tangential conduction and the foil thermal inertia, the instantaneous convective heat transfer coefficient h was recovered. This can be reported later in terms of Nusselt number (\(Nu = h\delta _{99}/k\)), where \(\delta _{99}\) is the local boundary layer thickness, and k is the thermal conductivity of water at wall temperature.
Figure 3 reports an example of an instantaneous wall Nu field in the streamwise/spanwise plane obtained using IR thermography. The white cross corresponds to a masked region due to the presence of the foil-support structure to minimize its bending and deformation on the foil due to water pressure. Using this sensor, the Nusselt-number uncertainty was estimated to be lower than \(6\%\), accounting for measurement uncertainties, following the same uncertainty-characterization process described by [11].
Velocity fields were measured with wall-parallel planar PIV, in the logarithmic layer of the TBL profile centred at \(y^+\approx 25\). The laser sheet thickness is approximately 1 mm, i.e. 11 wall units. The PIV images have been captured at a frequency equal to 1/4 of the IR acquisition one. The PIV images have been captured with a resolution of 26.4 pixels per mm employing an Andor Zyla sCMOS camera (with a sensor of \(2160 \times 2560\) pixels). The raw images were pre-processed to remove background reflections [26], and the velocity fields were evaluated using custom-made software developed at the University of Naples Federico II [3, 4]. The PIV code applies digital correlation [39] with an iterative multi-grid/multi-pass algorithm [37] and image deformation [36] as the interrogation strategy, with final interrogation windows of \(40 \times 40\) pixels and \(75\%\) overlap.
Overall, we have about 5600 samples for training and 1300 for validation. The test dataset includes approximately 1100 samples.

Sketch of the experimental setup in lateral view (adapted from Foroozan et al. [11]). The flat plate is indicated in yellow, the water-tunnel walls in magenta, and the periscope box in grey. PIV and IR measurement planes are shown in green and red, respectively

Heat-flux and flow-field visualizations, as sampled from the water tunnel. Note the foil support, which limits the possibility of measuring the heat-flux field
3 Methodology
3.1 Neural-network model
In this work, we consider several network architectures for different types of predictions. Based on the quantities sampled at the wall that are provided as input to the neural network, three types of predictions are investigated, as summarized in Table 2.
In the first problem, a neural-network model is trained to predict the velocity-fluctuation fields farther from the wall using the streamwise and spanwise wall-shear-stress components, as well as the wall-pressure fields. The predictions of the first problem are denoted as type I. These predictions use the same inputs and outputs as those of our previous work [14]. In the second problem, the streamwise wall-shear stress is substituted with the heat flux field corresponding to a passive scalar. We refer to these predictions as type-II predictions. Finally, a third problem is considered, using only the heat-flux field as input (type III). The latter two types of predictions are performed using all four Prandtl numbers sampled from the DNSs. Type III predictions aim to reproduce our experimental setting, in which we will be able to measure only the wall heat-flux field.
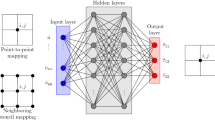
All the trained models are fully-convolutional neural networks (FCNs), meaning that the input information is processed by a sequence of convolutional layers, but there are no fully-connected layers at the end, as it is typical of convolutional neural networks that are employed for classification tasks on the entire input. The inputs of the FCN model are normalized with the mean and standard deviation computed on the training samples. The velocity-fluctuation fields predicted by the FCN are scaled with the ratio of the corresponding root-mean-squared (RMS) values and the streamwise RMS value, following [14]. The scaled output quantities are indicated with \(\widehat{\bullet }\).
FCNs allow an accurate reconstruction of the flow fields thanks to their capability to identify simple features and to combine them into progressively more complex ones. The FCN used as reference [14] is relatively shallow (i.e. few convolutional layers), with a high number of kernels per layer. On the other hand, the network architectures tested in this work have a higher number of layers with fewer kernels per layer. These modifications are designed to enhance the compositional capabilities of the model without increasing its GPU-memory footprint and computational-training cost. Note that deeper networks can be harder to train, since they are more evidently subjected to vanishing-gradient problems. Several solutions have been proposed in the literature, including but not limited to batch normalization [22] and dropout [20]. We include the former in our architecture but not the latter, since dropout has been mostly used after fully-connected layers in the literature, which are not present in our models. Additionally, it should be noted that the output of each convolutional layer is slightly smaller than the input, depending on the size of the convolutional kernel [9]. When a very high number of layers is used, the output can become significantly smaller than the input. In our work, the size of the output is kept constant by modifying the size of the input field according to the architecture. This is realized by sampling a larger area in the streamwise direction and by padding periodically the field in the spanwise direction. Different models with a varying number of layers and parameters are trained in order to identify the best combination of these network architecture parameters. Such comparison is performed using HD DNS data, on type-III predictions at \(y^{+}=30\) with \(\theta _4\) heat flux as input. The objective is to optimize the network performance for its experimental use, as further detailed in Sect. 4.1. Unless stated otherwise, all the considered neural-network models are trained using the hyperparameters described in Table 3. Note that the number of samples per batch is limited only by the memory of the GPU used for training. On the same GPU, we are able to use a larger batch-size when HD samples are used.
The FCN is trained using the Adam [24] optimization algorithm to minimize the mean-squared error (MSE) of the predictions with respect to the turbulent fields sampled from the DNS:
where boldface indicates the vectors containing the three velocity components and \(|\bullet |\) represents the \(L_2\) norm. We refer to the error in the individual components using \({\mathcal {L}}(\bullet )\) for brevity.
For type-III predictions, an additional auxiliary loss function is considered: streamwise and spanwise wall-shear stress as well as wall-pressure field are predicted by the network as an intermediate output, in an effort to drive the internal flow representation of the FCN towards physically-meaningful and interpretable quantities. Also in this case, the network parameters are updated based on the gradient with respect to the MSE between the reference DNS quantities and the FCN predictions.
3.2 Transfer learning from synthetic experimental data
Our objective is to perform the predictions on the experimental data with the highest possible accuracy. Our dataset only includes few thousands of samples, as reported in Sect. 2.2 and the limited availability of data may hinder the prediction performance of the FCNs. To address this issue, we modify the DNS data in order to obtain a dataset of synthetic experimental samples. Using this data, we can optimized a neural network model and then use transfer learning [30]. With this approach, we fine-tune the trained model on the experimental data.
In order to improve the transfer effectiveness, the synthetic data need to match the size and resolution of the experimental samples as much as possible. The experimental data have a lower resolution than their DNS counterpart, they are obtained in a relatively small region and they encompass a very limited range of Reynolds numbers. The sensor field of view is approximately equal to \(0.04\,\textrm{m}\cdot 0.04\,\textrm{m}\), which approximately translates to \(24\delta ^*_0 \cdot 24\delta ^*_0\). We take a subset of the DNS fields of size \(30\delta ^*_0 \cdot 30\delta ^*_0\), with \(x/\delta _0^* \in [760,790]\). The Reynolds number at the center of the samples is \(Re_{\tau }\approx 390\), similar to the value measured in the experiments. The resulting input and output fields have a resolution of \(96\times 96\). Taking DNS fields of this size would result in a limited number of points per sample for the neural network training. In order to address this issue, we increased the number of samples by considering a wider streamwise range (\(x/\delta _0^* \in [745,805]\)), from which we take three samples of size \(30\delta ^*_0 \cdot 30\delta ^*_0\), with \(15\delta ^*_0\) overlap in the streamwise direction. Since our simulation domain has a spanwise size \(L_z = 50\delta ^*_0\), it is possible to take two rows of samples with overlap \(10\delta ^*_0\). Overall, we obtain six samples from each DNS field.
While in the DNS we have heat-flux information in every point at the wall, in the experiment we need to take into account the limitations of the measurement system. The support used to limit the heat-transfer sensor deformation prevents the heat flux measurements at that location. In our synthetic data, we remove information from the input in the same way, setting to zero the heat-flux value at the points corresponding to the support.
Since the wall-normal component of the velocity fluctuations is not measured in the experiments, we train the FCN to predict only the streamwise and spanwise components.
4 Results and discussion
4.1 Network-architecture choice and predictions on DNS data
The quality of the network predictions is assessed on the test dataset, which consists of samples that are uncorrelated to the data used for training. The comparison is performed using the MSE with respect to the corresponding DNS fields and the turbulence statistics accuracy. The pre-multiplied two-dimensional power-spectral densities are also computed, to assess the amount of energy reconstructed for the different scales. We compare different FCN architectures with varying number of layers and trainable parameters by analyzing the performance in terms of MSE and root-mean-squared (RMS) error in the streamwise velocity fluctuations. All the models are trained to perform type-III predictions. The number of layers in the network appears to be the most impacting factor on the accuracy of the predictions, as highlighted in Fig. 4a, c. The MSE decreases as the number of layers is increased. The error in the statistics also follows a similar trend, however, it should be noted that the deepest network considered shows a slightly higher error than the one immediately shallower. Increasing the number of trainable parameters in the network does not have a clear effect on the MSE (Fig. 4b) and on the RMS error (Fig. 4d).

MSE and RMS error in the predictions as a function of the number of layers of the network or the number of trainable parameters, for type-III predictions. \(\partial \theta _4/\partial y |_{\textrm{wall}}\) is used as input. The numbers are indexes to identify the different architectures, sorted by the number of layers. The filled square marker represents the network model used in [14], while the filled circle is the model proposed in this work. These two latter models are compared in all the subsequent analysis
The network architecture trained in [14] and the deepest network in this work have roughly the same number of trainable parameters, however, the latter network shows a prediction error that is about 50% lower than the former. This result suggests higher importance of the compositional capabilities of the network over its capacity. Despite achieving the best performance in the comparison, our deepest network was not selected for the subsequent analysis primarily because of the low ratio between the output and input field size. In particular, in an experimental setting, we would not be able to increase the size of the input fields as done in this numerical investigation, hence a deeper network would inevitably result in a smaller output field in which fewer turbulent features are represented. In the remainder of this work, we present the results obtained with the second best architecture, which has about half of the layers as our deepest one, allowing us to maintain a more acceptable output/input size ratio, while providing a comparable performance in terms of MSE. This architecture also provides a slightly smaller error in the RMS error for the streamwise fluctuations, as shown in Fig. 4c. Note that this network has a higher number of trainable parameters, having a higher number of kernels per layer than the deepest network trained.

MSE in the predictions as a function of the streamwise location for type-III predictions at \(y^+=30\). The curve represents the average over the spanwise direction and the samples in the test dataset
Given the network architecture, the predictions on the full-domain and on the half-domain datasets are compared. One of the advantages of the FCN is that the architecture does not depend on the size of the input. Either datasets can then be used to train the neural-network model. Despite providing more information per sample during training, the predictions of the model optimized on the full-domain dataset are less accurate than the ones on the half-domain dataset. This can be explained by considering that the boundary layer is a spatially-developing flow. This means that each sample contains a range of Reynolds numbers that need to be predicted. If we consider the error in the predictions along the streamwise direction shown in Fig. 5, the trend exhibits a minimum at the center of the sample. This is a result of the use of MSE as training objective function. Furthermore, the larger the sample, the lower the Reynolds number at which we can achieve the highest accuracy. If we consider a smaller range encompassing only the higher Reynolds numbers (i.e. we use HD samples), more accurate predictions can be obtained at high Re. This result is encouraging for experimental applications, since the input data that can be obtained are limited to a small interrogation window (e.g. obtained from particle-image velocimetry), with a small Reynolds-number range. It should be noted, however, that training the models on a smaller portion of the domain reduces the overall amount of data available for optimization for a given size of the training dataset. Further shrinking of the domain size will eventually yield a performance reduction because of this trade-off Because of these observations, the prediction results in the subsequent part of the paper will be only related to the half-domain dataset.

MSE (left) and turbulence-statistics error (right) obtained in type-I predictions with respect to target fields at different wall-normal locations. The error for each velocity component is normalized with the square of the corresponding fluctuation intensity

Pre-multiplied two-dimensional power-spectral densities for type I predictions at \(y^+=30\). The three columns represent \(k_{z}k_{x}\phi _{uu}\) (left), \(k_{z}k_{x}\phi _{vv}\) (center), \(k_{z}k_{x}\phi _{ww}\) (right). The contour levels contain 10%, 50% and 90% of the maximum DNS power-spectral density. Shaded contours refer to the reference data, while contour lines refer to the FCN proposed here (solid) and the network by [14] (dashed), respectively
Once the network architecture and the dataset are chosen, the model is trained three times, unless noted otherwise. Each training run is performed with different random initialization in order to verify the consistency of the stochastic optimizations. The reported results show the average performance of the three models. When three inputs are considered (type-I and type-II predictions), the present network is able to reconstruct the non-linear relation between input and output fields with higher accuracy than the FCN proposed in [14], as shown in Fig. 6 (type-I predictions). The improvement is consistent across the entire range of investigated wall-normal locations. On the other hand, the performance degrades in a similar way as we move farther away from the wall. The accuracy of the present network at \(y^{+}=50\) is comparable to that of the FCN in [14] at \(y^{+}=30\). At \(y^{+}=100\), the MSE in the wall-normal and spanwise directions is similar for both architectures. The accuracy improvement is even more pronounced when considering the predicted turbulent statistics. In short, the error is lower at all \(y^{+}\) locations and even at \(y^{+}=100\), the current FCN performs substantially better than its predecessor. The difference in the compositional capability is evident when comparing the pre-multiplied power-spectral densities of the predictions of the two networks in Fig. 7. The small-scale features at \(y^+=30\) are well predicted by both networks, however, the deeper FCN can better reproduce the larger-scale features, especially in the spanwise direction.
Type-II predictions represent an intermediate step toward the flow estimation using only the heat flux. When passing from type I to type II, the error is higher for all the velocity components, however, the streamwise component is the most affected, as shown in Table 4. The heat flux at the wall is less correlated to the velocity-fluctuations away from the wall than the streamwise wall-shear stress. Despite neural networks provide a non-linear mapping between input and output, a performance reduction can be anticipated by observing the linear-correlation measures in Appendix A. A higher Prandtl number for the scalar determines a higher error in the predictions, especially close to the wall. As shown in Fig. 8, the difference between the different scalars is less pronounced farther away from the wall. Including the spanwise wall-shear stress and the pressure as inputs makes the Prandtl dependence less evident in this type of predictions. The bottom row of Fig. 8 highlights an apparent inconsistency in the relation between the statistical error and the Prandtl number. Since we do not train the model for statistical accuracy directly, the error has a higher variance between models than the MSE on the individual predictions. Furthermore, only one model per Prandtl number and wall-normal location has been trained in this case. Averaging the results from different models helps retrieving the relation between the error and the Prandtl number that can be observed in the MSE. The percentual increment of the MSE due to the added difficulty of the predictions is similar for both the network proposed in this work and the one in [14]; note however that the predictions from the former are significantly more accurate than those of the latter. For this reason, the current FCN is found to perform better across the entire range of wall-normal locations, even for type-II predictions.

MSE (top) and turbulence-statistics error (bottom) obtained in type-II predictions with respect to target fields at different wall-normal locations, using different scalar fields as inputs. The error for each velocity component is normalized with the square of the corresponding fluctuation intensity
When Type-III predictions are performed, the resulting MSE is about three times higher when compared to type-II predictions, confirming that information in the spanwise wall-shear stress and wall pressure has an important role in the reconstruction of the fields away from the wall. Figure 9 shows how the use of a different scalar does affect the prediction quality. Close to the wall, the predictions become progressively more challenging as the Prandtl number increases. Interestingly, the difference is negligible at \(y^+=50\) and the models trained at \(y^+=100\) with \(Pr=4\) and \(Pr=6\) perform better than the models trained with lower-Prandtl-number inputs. Note, however, that the error in all these reconstructions is quite significant and only the largest structures are predicted. The degradation in the prediction quality with respect to the wall-normal distance was already reported in [14].

MSE obtained in type-III predictions with respect to target fields at different wall-normal locations, using different scalar fields as inputs. The error for each velocity component is normalized with the square of the corresponding fluctuation intensity
Note that, closer to the wall, the predictions become more and more difficult as the Prandtl number increases. This can be linked with the change of the heat-flux features that can be observed by the neural network as the Prandtl number changes. When the mean-squared error is used to optimize the neural network, the predicted fields tend to span a smaller range of values than the corresponding DNS fields. The correct localization and estimation of the strongest fluctuations becomes very relevant to obtain accurate predictions. Figure 10 compares the highest and lowest fluctuations of the input and output fields at \(y^+=30\) for two different Prandtl numbers. At \(Pr=1\), the features in the output have a spatial correspondence with the features in the input, and this is particularly evident for the lowest fluctuations. Since the neural network provides a localized relation between input and output, an accurate reconstruction is possible. The spacing between the higher and lower values in the input becomes smaller in the spanwise direction as the Prandtl number increases. In this case, the prediction becomes more challenging because a larger number of high/low-value streaks are present in the receptive field of the network and the spatial location of the output features is more difficult to identify.

Comparison of the regions of highest and lowest fluctuations in the input fields (top row), and the output fields at \(y^+=30\) from DNS and FCN prediction. The second and third rows show the highest fluctuations in the DNS and FCN prediction, respectively. The fourth and fifth rows show the lowest fluctuations. The grey contours represent the corresponding positive or negative fluctuations in the input field. The left column shows a sample type-III prediction using the heat flux at \(Pr=1\). The right column shows the predictions with input at \(Pr=6\). Blue and red indicate the regions where the fluctuations are smaller than \(-1.1\sigma \) and larger than \(1.1\sigma \), respectively
In order to obtain a more quantitative perspective on the previous observations, we compute the spectra of the filtered input and output fields, as shown in Fig. 11a. We identify the regions of the flow with high (resp. low) fluctuations by considering only the points where the value is above (resp. below) a threshold of \(1.1\sigma \) (resp. \(-1.1\sigma \)), where \(\sigma \) is the standard deviation of the considered quantity, as computed from the training dataset. Indeed, the strongest fluctuations at the higher Prandtl number exhibit a shift towards shorter spanwise wavelengths, with a reduced superposition to the output frequency content, when compared to lower Prandtl numbers. Note that these observations are aligned with the power-spectral-density analysis reported in [6]. In Fig. 11b, we compare the region match as the percentage of points of high/low fluctuations that are present in both the fields considered. The region match between the heat-flux field and the DNS velocity field is higher for the lowest fluctuations than the highest, as observed in Fig. 10. The percentage match reduces as we move farther away from the wall: this is expected as the flow features close to the wall are similar to their wall footprint. Note, however, that the match does not go below 15% even at \(y^+=100\). The effect of the Prandtl number is very evident close to the wall, the higher the Prandtl number, the smaller is the region match: for instance, we can observe a match reduction of about 20% between \(Pr=1\) and \(Pr=6\) at \(y^+=15\). The region match between the heat flux field and the FCN predictions is similar close to the wall but as we move farther away, the match is smaller. This is particularly evident in the highest-fluctuation region. Differently from the DNS fields, the match farther away from the wall gets progressively smaller, reaching near-zero value at \(y^+=100\). The increase in the Pr number is associated with a reduction of the region match. Finally, the match between the DNS fields and the corresponding predictions quantifies the error in the predictions at different wall-normal locations and Prandtl numbers, separating the contributions of the highest and lowest fluctuations. The regions of lowest fluctuations are better predicted at all wall-normal locations, so the high-fluctuation regions have a larger contribution to the error in the FCN predictions.

a) Pre-multiplied two-dimensional power-spectral densities of wall-heat flux and streamwise velocity fluctuation at \(y^+=30\) (shaded contours), for the data-points that have \(\Vert q\Vert >1.1\sigma \), where \(q = \{\partial \theta _1 / \partial y,~\partial \theta _4 / \partial y,~u\}\). The contour levels contain 10%, 50% and 90% of the maximum DNS power-spectral density. b) Percentage match in the highest (blue) and lowest (orange) fluctutations between input and DNS fields (left), input and FCN predictions (center), DNS fields and FCN predictions (right). The comparison is performed for all the sampled Pr numbers
The statistical error for type III predictions can be further improved with the use of the auxiliary loss. We tested it for the predictions using \(\partial \theta _4/\partial y |_{\textrm{wall}}\) as input: while the MSE is only about \(5\%\) lower, the predicted turbulence statistics are up to \(20\%\) better than when the auxiliary loss function is not used, as shown in Table 5. The use of an auxiliary loss function also reduces the variance between models in the statistical of all the velocity components. The error comparison with [14] shows how a deeper FCN is necessary to achieve satisfactory predictions of this type. A sample type-III prediction at \(y^{+} = 30\) using the auxiliary loss function is shown in Fig. 12, when \(\partial \theta _4/\partial y |_{\textrm{wall}}\) is used as input. From this figure, it is possible to observe that the FCN is able to reconstruct the large-scale features of the flow in all three velocity components starting from the heat-flux field only. The smaller-features reconstruction is less accurate, in particular, the maximum positive and negative fluctuations are typically underestimated. This is related to the use of the mean-squared error as loss function for the optimization.

Sample result for type-III prediction at \(y^{+} = 30\), obtained using the proposed FCN with auxiliary loss functions. The first row corresponds to the DNS input heat flux for \(Pr = 6\), normalized with the mean and standard deviation computed on the training samples. The second and third rows show the streamwise DNS velocity-fluctuation field and the corresponding prediction obtained from FCN, respectively. Similarly, the fourth and fifth rows represent the wall-normal velocity fluctuation of the target and predicted fields. Finally, the sixth and seventh rows show the spanwise velocity fluctuation component of the target and predicted fields, respectively. The velocity-fluctuation fields are scaled by the respective RMS quantities
We now focus on the predictions whose setup is similar to the experimental setting. For this, we analyze more in depth type III predictions using the heat flux at \(Pr = 6\). A more comprehensive overview of the predicted energy at the different scales is provided by the spectra, shown in Fig. 13. We compare the spectra of type-II and type-III predictions at \(y^+=30\). The amount of reconstructed energy is lower in type-III predictions than in type-II. Furthermore, it is possible to observe that eliminating the spanwise wall-shear stress and wall pressure has a higher impact on the prediction of the shorter wavelengths, both in the streamwise and spanwise direction. The accuracy reduction is more evident in the pre-multiplied wall-normal and spanwise spectra. This is expected, as the wall-pressure is well correlated with the wall-normal component of the velocity and the spanwise wall-shear stress helps to improve the prediction of the corresponding velocity-fluctuation component.

Pre-multiplied two-dimensional power-spectral densities of different prediction types using \(\partial \theta _4/\partial y |_{\textrm{wall}}\) as input. The three columns represent \(k_{z}k_{x}\phi _{uu}\) (left), \(k_{z}k_{x}\phi _{vv}\) (center), \(k_{z}k_{x}\phi _{ww}\) (right). The contour levels contain 10%, 50% and 90% of the maximum DNS power-spectral density. Shaded contours refer to the reference data, while contour lines refer to type-II (blue) and type-III (orange) predictions, respectively
4.2 Predictions on experimental data

Sample result of predictions obtained using the FCN with auxiliary loss functions, trained on (a) DNS data and (b) experimental data. In both panels, the top row represents the input, i.e. the wall heat flux field at \(Pr\approx 6\), the second represents the ground truth from the simulation and the experiment, respectively. Finally, the third row shows the corresponding network predictions
In order to train a network on the experimental data, we first need to optimize a copy of the same neural network on the DNS data and then perform transfer learning, as described in Sect. 3.2. In the previous section we selected the network architecture based on trade-off between the model performance and the input/output ratio. Note, however, that the fields sampled from the experiment are relatively small (\(82 \times 82\)) and they cannot be extended. For this, we have to resort to zero-padding the fields, even if this comes at the cost of a larger error close to the edges. Also for these predictions, the performance is assessed using the mean-squared error with respect to the ground truth velocity-fluctuations fields. The use of the synthetic experimental data for training determines an increase of the MSE in the predictions with respect to the FCN models trained with the full-fields from DNS, as reported in Table 6. The error in the wall-parallel velocity-fluctuation components is more than two times larger with respect to the values reported in Table 5. Figure 14a allows a qualitative comparison of the DNS fields and the corresponding predictions. Only the larger scales of the turbulent motions are reconstructed and we can observe the prediction of regions of large positive fluctuations that are not present in the DNS field. These regions are typically located close to the foil support, where the lack of information makes the predictions harder. The streamwise component is predicted with higher accuracy than the spanwise component.
Once the FCN is fine-tuned on the experimental dataset, it is possible to assess its performance on the experimental test data. In this case, the error is about 50% higher than the predictions on the synthetic data from DNS, as reported in Table 6. The input fields show a much smoother variation of the heat flux, as shown in Fig. 14b. This is to be addressed to the spatial modulation of the heat flux sensor. The resulting predictions are less detailed than all the previous ones: in the streamwise component, a general reconstruction of the larger scales of the flow is provided. By contrast, the spanwise component reconstruction is lacking. After gradually increasing the difficulty of the prediction, first by reducing the number of inputs and then using less and less informative ones, we are now testing the FCN network on a very challenging task.
The fine-tuning on the experimental training dataset can only partially compensate for the small amount of data available: the fact that the error in the prediction is higher than the DNS synthetic fields, reported in Table 6, is expected. In these conditions, the reconstruction performance of the neural network is relatively limited. These results partially depend on the reduced amount of data, but it can also be explained by the discrepancies between simulation settings and experimental conditions. In Fig. 15, we compare the power-spectral densities of the inputs: because of the inherent limitations of the experimental procedures, the energy content at the higher frequencies is reduced. Furthermore, the choice of the loss function plays a role also in this context: the minimization of the MSE tends to smooth out the peaks in the predictions. For zero-mean fields, this translates to an effective reduction of the value range in the predictions. Despite the limitations, this study represents the first attempt to perform these type of predictions using experimental data. As such, it represents an important step towards the implementation of non-intrusive sensing in experiments. Our analyses describe most of the important challenges related to the deployment of a neural network model in an engineering context, especially when the training is performed on synthetic data rather than real ones, which are often very expensive or difficult to obtain.

Comparison of the pre-multiplied one-dimensional power-spectral densities of the wall-heat flux in the synthetic DNS fields and the experimental ones
5 Conclusions
In this work, we assessed the prediction capabilities of a fully-convolutional network (FCN) using DNS data sampled from a turbulent boundary layer flow, with a maximum Reynolds number of \(Re_{\tau }=396\). We optimize the architecture of the FCN in order to minimize the MSE in the predictions, while maintaining a satisfactory output/input ratio of the field size. For type II and type III predictions, we describe the effect of using as input heat flux fields at progressively higher Prandtl number. Closer to the wall, the predictions become more challenging as the Prandtl number is increased. With the highest Prandtl number tested (\(Pr=6\)), the resulting network yields type-III predictions at \(y^{+} = 30\) with an error that is 50% lower than that of the previously-studied architectures [14]. A higher number of layers determines a larger receptive field for the network, and it enhances its compositional capabilities. The prediction accuracy is proven to be more sensitive to this parameter than the network capacity (i.e. the number of trainable parameters). The use of alternative, yet similar network architectures, e.g. ResNet by [18] or UNet by [33] was only partially explored and for this reason not reported, preventing a more comprehensive analysis of the available network architectures. The performance of completely different models, such as transformers [38] and diffusion models [21] could also be compared with our FCN, once they have been adapted for the described prediction task. The architectural improvements described here are essential to achieve a satisfactory velocity field reconstruction, given the additional difficulties related to the choice of a spatially-evolving flow, and the use of input quantities that are less informative than the ones used in the previous studies. In this study we limit ourselves to the a-posteriori analysis of the results of several trained networks, highlighting the need for deeper networks in order to obtain a satisfactory accuracy in the reconstruction. The number of layers in a network, as well as the number of trainable parameters per layer (e.g. the number of kernels per convolutional layer) are hyperparameters that need to be tuned to obtain the best performance of a neural network model. Automated hyperparameter searches can be conducted using evolutionary algorithms or Bayesian optimization, however, several networks still need to be trained depending on the number of hyperparameters that need to be adjusted. It should be noted that we focus our attention on improving the network performance when the heat flux is chosen as input instead of the wall-shear stress components and the wall pressure, but we have not explored possible solutions to maintain the prediction accuracy as the Prandtl number increases. In this regard, the design of a Pr-invariant neural network model represents an appealing research direction, in order to perform accurate predictions at even higher Prandtl numbers.
After assessing the prediction capabilities of the FCN using full DNS data, we trained the selected architecture with synthetic experimental data, obtained by modifying the samples from the numerical simulation to resemble the measurements from a water tunnel. The FCN is then further optimized using samples from the experiments through transfer learning. These predictions represent the first attempt towards non-intrusive-sensing applications in experimental settings through deep learning. Despite the limitations of the experimental measurements, the neural-network model is able to provide acceptable predictions for the streamwise fluctuations. It is important to highlight that the receptive field of the FCN is large compared to the size of the experimental samples. This, combined with the use of zero-padding, may have a detrimental effect on the model performance, as shown in Appendix B. The network architecture can be further optimized by taking these elements into account. The predicted fields exhibit an error with respect to the original fields that is 50% larger than the model trained and tested only on synthetic experimental data. Future work will be devoted to improving the training procedure to reduce the performance gap between the two models.
Code availability
The data that support the findings of this study are openly available in https://github.com/KTH-FlowAI upon publication.
References
Abe, H., Kawamura, H., Matsuo, Y.: Surface heat-flux fluctuations in a turbulent channel flow up to \({R}e_{\tau } = 1020\) with \({P}r=0.025\) and 0.71. Int. J. Heat Fluid Flow 25(3), 404–419 (2004). https://doi.org/10.1016/j.ijheatfluidflow.2004.02.010
Alcántara-Ávila, F., Hoyas, S., Pérez-Quiles, M.J.: Direct numerical simulation of thermal channel flow for \({R}e_{\tau } = 5000\) and \({P}r=0.71\). J Fluid Mech 916 (2021)
Astarita, T.: Analysis of weighting windows for image deformation methods in PIV. Exp. Fluids 43(6), 859–872 (2007)
Astarita, T., Cardone, G.: Analysis of interpolation schemes for image deformation methods in PIV. Exp. Fluids 38(2), 233–243 (2004)
Astarita, T., Carlomagno, G.M.: Infrared Thermography for Thermo-Fluid-Dynamics. Springer (2012)
Balasubramanian, A.G., Guastoni, L., Schlatter, P., et al.: Direct numerical simulation of a zero-pressure-gradient turbulent boundary layer with passive scalars up to Prandtl number pr=6. J. Fluid Mech. 974, A49 (2023). https://doi.org/10.1017/jfm.2023.803
Borée, J.: Extended proper orthogonal decomposition: a tool to analyse correlated events in turbulent flows. Exp. Fluids 35(2), 188–192 (2003)
Chevalier, M., Schlatter, P., Lundbladh, A., et al.: SIMSON: a pseudo-spectral solver for incompressible boundary layer flows. Tech. rep, KTH Royal Institute of Technology, Stockholm (2007)
Dumoulin, V., Visin, F.: A guide to convolution arithmetic for deep learning. Preprint at arXiv:1603.07285 (2016)
Encinar, M.P., Jiménez, J.: Logarithmic-layer turbulence: a view from the wall. Phys Rev Fluids 4, 114603 (2019). https://doi.org/10.1103/PhysRevFluids.4.114603
Foroozan, F., Guemes, A., Raiola, M., et al.: Synchronized measurement of instantaneous convective heat flux and velocity fields in wall-bounded flows. Meas. Sci. Technol. 34(12), 125301 (2023). (in press)
Gautier, N., Aider, J.L., Duriez, T., et al.: Closed-loop separation control using machine learning. J. Fluid Mech. 770, 442–457 (2015). https://doi.org/10.1017/jfm.2015.95
Guastoni, L., Encinar, M.P., Schlatter, P., et al.: Prediction of wall-bounded turbulence from wall quantities using convolutional neural networks. J. Phys. Conf. Ser. 1522(1), 012022 (2020)
Guastoni, L., Güemes, A., Ianiro, A., et al.: Convolutional-network models to predict wall-bounded turbulence from wall quantities. J. Fluid Mech. 928, A27 (2021). https://doi.org/10.1017/jfm.2021.812
Güemes, A., Discetti, S., Ianiro, A.: Sensing the turbulent large-scale motions with their wall signature. Phys. Fluids 31(12) (2019)
Güemes, A., Discetti, S., Ianiro, A., et al.: From coarse wall measurements to turbulent velocity fields through deep learning. Phys. Fluids 33(7), 075121 (2021). https://doi.org/10.1063/5.0058346
Gurka, R., Liberzon, A., Hetsroni, G.: Detecting coherent patterns in a flume by using PIV and IR imaging techniques. Exp. Fluids 37(2), 230–236 (2004). https://doi.org/10.1007/s00348-004-0805-3
He, K., Zhang, X., Ren, S., et al .: Deep residual learning for image recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp 770–778. https://doi.org/10.1109/CVPR.2016.90 (2016)
Hetsroni, G., Rozenblit, R.: Heat transfer to a liquid-solid mixture in a flume. Int. J. Multiph. Flow 20(4), 671–689 (1994)
Hinton, G.E., Srivastava, N., Krizhevsky, A., et al.: Improving neural networks by preventing co-adaptation of feature detectors. Preprint at arXiv:1207.0580 (2012)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Preprint at arXiv:2006.11239 (2020)
Ioffe, S., Szegedy, C.: Batch normalization: Accelerating deep network training by reducing internal covariate shift. Preprint at arXiv:1502.03167 (2015)
Kim, J., Lee, C.: Prediction of turbulent heat transfer using convolutional neural networks. J. Fluid Mech. 882, A18 (2020). https://doi.org/10.1017/jfm.2019.814
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. In: 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7–9, 2015 (2015)
Kozuka, M., Seki, Y., Kawamura, H.: DNS of turbulent heat transfer in a channel flow with a high spatial resolution. Int. J. Heat Fluid Fl 30(3), 514–524 (2009)
Mendez, M.A., Raiola, M., Masullo, A., et al.: Pod-based background removal for particle image velocimetry. Exp. Therm. Fluid Sci. 80, 181–192 (2017)
Milano, M., Koumoutsakos, P.: Neural network modeling for near wall turbulent flow. J. Comput. Phys. 182(1), 1–26 (2002)
Nakamura, H.: Frequency response and spatial resolution of a thin foil for heat transfer measurements using infrared thermography. Int. J. Heat Mass Transf. 52(21–22), 5040–5045 (2009)
Nakamura, H., Yamada, S.: Quantitative evaluation of spatio-temporal heat transfer to a turbulent air flow using a heated thin-foil. Int. J. Heat Mass Transf. 64, 892–902 (2013)
Pan, S.J., Yang, Q.: A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 22(10), 1345–1359 (2009)
Raffel, M., Willert, C.E., Scarano, F., et al.: Particle Image Velocimetry: A Practical Guide. Springer (2018)
Raiola, M., Greco, C.S., Contino, M., et al.: Towards enabling time-resolved measurements of turbulent convective heat transfer maps with IR thermography and a heated thin foil. Int. J. Heat Mass Trans. 108, 199–209 (2017)
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional Networks for Biomedical Image Segmentation, pp. 234–241. Springer (2015)
Sanmiguel Vila, C., Örlü, R., Vinuesa, R., et al.: Adverse-pressure-gradient effects on turbulent boundary layers: statistics and flow-field organization. Flow Turbul. Combust. 99, 589–612 (2017)
Sasaki, K., Vinuesa, R., Cavalieri, A.V.G., et al.: Transfer functions for flow predictions in wall-bounded turbulence. J. Fluid Mech. 864, 708–745 (2019). https://doi.org/10.1017/jfm.2019.27
Scarano, F.: Iterative image deformation methods in PIV. Meas. Sci. Technol. 13(1), R1 (2001)
Soria, J.: An investigation of the near wake of a circular cylinder using a video-based digital cross-correlation particle image velocimetry technique. Exp. Therm. Fluid Sci. 12(2), 221–233 (1996)
Vaswani, A., Shazeer, N., Parmar, N., et al.: Attention is all you need. arXiv:1706.03762. https://doi.org/10.48550/ARXIV.1706.03762 (2017)
Willert, C.E., Gharib, M.: Digital particle image velocimetry. Exp. Fluids 10(4), 181–193 (1991)
Acknowledgements
The authors acknowledge the Swedish National Infrastructure for Computing (SNIC) for providing the computational resources by PDC, used to carry out the numerical simulations.
Funding
Open access funding provided by Royal Institute of Technology. This work is supported by the founding provided by the Swedish e-Science Research Centre (SeRC), ERC grant no. “2021-CoG-101043998, DEEPCONTROL” and the Knut and Alice Wallenberg (KAW) Foundation. S.D., A.I. and F.F. acknowledge funding by the project ARTURO, ref. PID2019-109717RB-I00/AEI/10.13039/501100011033, funded by the Spanish State Research Agency and the project EXCALIBUR (Grant No PID2022-138314NB-I00), funded by MCIU/AEI/10.13039/501100011033 and by ‘ERDF A way of making Europe’.
Author information
Authors and Affiliations
Contributions
The study was conceptualized and planned by AI, SD, and RV. The dataset was generated by AGB, with input from LG, PS and RV. The network model was implemented and trained by AGB, starting from the previous code implementation by LG. LG, RV and HA provided feedback on the network design. The post-processing of the results was performed by AGB, with input from LG, RV and HA. The paper was written by LG and AGB. FF, AG, SD and AI designed the experiment. FF performed the experimental campaign with support of SD and AI. FF and AG processed the experimental data with input from SD and AI. All authors revised the manuscript and agree with its content.
Corresponding author
Ethics declarations
Conflict of interest
The authors report no Conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Linear correlation of inputs and outputs
Neural-network models such as FCNs are optimized to approximate the relation between input and output using a non-linear function. This capability provides a fundamental advantage with respect to techniques such as extended proper orthogonal decomposition [7], allowing for a better reconstruction, in particular when the output plane is far from the wall [14]. Nonetheless, the analysis of the linear correlation between different input–output pairs can provide a quantitative perspective on the difficulty of the individual prediction tasks. We compute the linear correlation between two variables r and s as:
where \(\langle \bullet \rangle \) indicates the average over the samples and in the homogeneous directions. Table 7 lists the correlation of the inputs–streamwise wall-shear stress and the heat fluxes at different Pr numbers–and the outputs, i.e. the velocity fluctuations in the three components. The streamwise shear stress and the heat flux at \(Pr=1\) show a similar linear correlation with the velocity components. These quantities are the most correlated among all the possible inputs considered. The linear correlation decreases when the Prandtl number is higher, highlighting how predicting the velocity field based on the heat flux information at the wall represents a more and more challenging task as the Pr number increases.
Appendix B: Effect on the prediction accuracy of the padding in the convolutional layers

MSE in the prediction of the synthetic DNS fields as a function of the streamwise (left) and spanwise (right) location
The region close to the boundaries of the input samples deserve special attention, since the lack of information outside the domain can negatively impact the prediction quality. Since FCNs perform predictions based on local information, [14] showed that periodic boundary conditions can be enforced analytically by periodically padding the input fields. This approach can improve the results also for other boundary conditions, however, it requires information outside the boundaries of the individual samples. Here, we seek to quantify the effect of the boundary treatment on the prediction performance. We consider predictions using the synthetic DNS fields, using three different boundary treatments:
-
Case I: Small zero-padding in all layers. In this case the filtered fields after each convolution maintain the same size. Input and output have the same size (\(82 \times 82\))
-
Case II: large zero-padding of the input. The filtered fields after each convolution are progressively smaller after the application of a convolution operation. The padding of the initial field depends on the receptive field of the FCN and it is computed to obtain an output field of the desired size. In this case the input has size \(120 \times 120\).
-
Case III: large informative padding of the input. Similar to the previous case, but the padding is performed by considering additional points from the original input fields along the streamwise and spanwise direction. The input size is \(120 \times 120\) also in this case.
The first two cases provide the same amount of information, in different forms. The resulting error in both the streamwise and spanwise direction follows a similar trend, as shown in Fig. 16. The additional information at the boundaries significantly improves the predictions close to the edges in both homogeneous directions and velocity components. Table 8 reports the average error on the training dataset. Case I and II provide very similar error values, highlighting how the two procedures are essentially equivalent. By contrast, case III reduces the MSE by about 10% with respect to Case I and II, allowing for a better reconstruction if the additional information is available. It should also be noted that the first two approaches yield similar results also after the fine-tuning on the experimental fields.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Guastoni, L., Balasubramanian, A.G., Foroozan, F. et al. Fully convolutional networks for velocity-field predictions based on the wall heat flux in turbulent boundary layers. Theor. Comput. Fluid Dyn. 39, 13 (2025). https://doi.org/10.1007/s00162-024-00732-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00162-024-00732-y