
Abstract
Patents, which encapsulate crucial technical and legal information in text form and referenced drawings, present a rich domain for natural language processing (NLP). As NLP technologies evolve, large language models (LLMs) have demonstrated outstanding capabilities in general text processing and generation tasks. However, the application of LLMs in the patent domain remains under-explored and under-developed due to the complexity of patents, particularly their language and legal framework. Understanding the unique characteristics of patent documents and related research in the patent domain becomes essential for researchers to apply these tools effectively. Therefore, this paper aims to equip NLP researchers with the essential knowledge to navigate this complex domain efficiently. We introduce the relevant fundamental aspects of patents to provide solid background information. In addition, we systematically break down the structural and linguistic characteristics unique to patents and map out how NLP can be leveraged for patent analysis and generation. Moreover, we demonstrate the spectrum of text-based and multimodal patent-related tasks, including nine patent analysis and four patent generation tasks.
Similar content being viewed by others


Explore related subjects
Discover the latest articles and news from researchers in related subjects, suggested using machine learning.Avoid common mistakes on your manuscript.
1 Introduction
Patents, a form of intellectual property (IP), grant the holder temporary rights to suppress competing use of an invention in exchange for a complete disclosure of the invention. The concept was once established to promote and/or control technical innovation and progress (Frumkin 1947). The surge in global patent applications and the rapid technological progress pose formidable challenges to patent offices and related practitioners (Krestel et al. 2021). These challenges overwhelm traditional manual methods of patent drafting and analysis. Consequently, there is a significant need for advanced computational techniques to automate patent-related tasks. Such automation not only enhances the efficiency of patent and IP management but also facilitates the extraction of valuable information from this extensive knowledge base (Abbas et al. 2014).
Researchers have investigated machine learning (ML) and natural language processing (NLP) methods for the patent field with highly technical and legal texts (Krestel et al. 2021). In addition, the recent large language models (LLMs) have demonstrated outstanding capabilities across a wide range of general domain tasks (Zhao et al. 2023; Min et al. 2023). Moreover, the expansion of the latest general LLMs with a graphical component to form multimodal models (Huang et al. 2024) may further enhance the capabilities in processing patents, which include text and drawings. These models are promising to become valuable tools in managing and drafting patent literature, the crucial resource that documents technological advances.
However, compared to the significant success of LLMs in the general domain, the application of LLMs in patent-related tasks remains under-explored due to the texts’ and the field’s complexity. NLP and multimodal model researchers need to deeply understand the unique characteristics of patent documents to develop useful models for the patent field. Therefore, we aim to equip researchers with the essential knowledge by presenting this highly auspicious but widely neglected field to the NLP community.
Previous surveys reported the early stages of smart and automated methods for patent analysis (Abbas et al. 2014), first deep learning methods, which opened a wider range of still simpler patent tasks (Krestel et al. 2021), or specific individual patent tasks, such as patent retrieval (Shalaby and Zadrozny 2019). The recent advancements in language and multimodal models were unforeseen, particularly the performance boost when models are massively scaled up (Kaplan et al. 2020). Accordingly, we specifically delineate a survey of popular methodologies for patent documents with a special focus on the most recent and evolving techniques. We have included the two applications of patent analysis and generative patent tasks (Fig. 1). Whereas analysis focuses on understanding and usage of individual patent documents or a group of patents, generation tasks aim at automatically generating patent texts.

Patent-related tasks
We provide a systematic survey of NLP applications in the patent domain, including fundamental concepts, insights on patent texts, development trends, datasets, tasks, and future research directions to serve as a reference for both novices and experts. Specifically, we cover the following topics:
-
1.
We provide an introduction to the fundamental aspects of patents in Sect. 2, including the composition of patents and the patent life cycle. This section is particularly for those readers still unfamiliar with it and a refresher for others.
-
2.
We analyze the unique structural and linguistic characteristics of patent texts with language processing and multimodal techniques to process these texts in Sect. 3. Readers will readily understand the challenges of automated patent processing and the development trends of NLP in the patent field.
-
3.
We present a detailed synthesis of patent data sources, alongside tailored datasets specifically designed for different patent tasks, in Sect. 4. With the collection of these ready-to-use datasets, we aim to eliminate the extensive time and effort for data preparation in the patent domain.
-
4.
We evaluate nine patent analysis tasks (subject classification, patent retrieval, information extraction, novelty prediction, granting prediction, litigation prediction, valuation, technology forecasting, and innovation recommendation) in Sect. 5 and four generation tasks (summarization, translation, simplification, and patent writing) in Sect. 6. Specifically, we systematically demonstrate task definitions and relevant methodologies in detail. We show a comprehensive yet accessible insight into this area, which should enable readers to grasp the nuances of the field more effectively.
-
5.
We identify current challenges and point out potential future research directions in Sect. 7. By highlighting these areas, we hope to encourage further research and development in automated patent tasks to stimulate more efficient and effective methods in the future.
2 Brief background
2.1 Patent document
Patent documents are central elements for the protection of intellectual property and also document inventions. Patents require applicants and/or inventors to publicly disclose their inventions in detail to secure exclusive rights and obtain benefits in return. Patent documents describe new inventions and delineate the scope of patent rights granted to patent holders. These documents are key parts of the patenting process and are publicly accessible typically 18 months after the application or the first filing date. The format and content can vary by jurisdiction but normally include the following elements. Figure 2 displays an example patent document.

Example of granted patent document (US Patent 11,824,732 B2). This is a US patent, and other countries have their own patent systems with largely similar requirements
Publication information includes the file number and date of patent (application) publication.
Title is the concise description of the invention.
Bibliometric information includes details about applicants, inventors, assignees, examiners, attorneys, etc.
Patent classification code defines the category of the patent. We introduce detailed information on patent classification schemes in Sect. 5.1.2.
Citations are lists of prior art and other patents referenced in the document or by examiners.
Abstract is a brief summary of the invention and its purpose.
Background contains basic information on the field of the invention and is supposed to list and appreciate the prior art, particularly in the patent literature.
Detailed description provides comprehensive details about the invention and specific embodiments, typically discussing the drawings.
Claims define the legal scope of the patent. Each claim is a single sentence, which describes the invention in specific features that make the invention novel and not easily derivable (obvious) from the state of the art (described by any source, not only patent documents).
Drawings are visual representations of the invention, disclosing important aspects of the invention as well as embodiments to support the textual description. Figure 3 shows an example patent drawing. Apart from patent texts, researchers also use patent drawings for patent analysis, which is introduced in Appendix A.

Example drawing from patent US 10,854,933. Many figures in patents are generic without the corresponding description. Drawings tend to be less generic in patents on pharmaceuticals or mechanics, often consisting of graphs, images, or models. Some drawings are also of poor resolution, pixelation, or low quality. The reference numbers indicate specific elements introduced in the patent description. The reference numbers have to be named by the same term consistently throughout the patent application, which can also substantially deviate from language conventions in the field. The reference numbers are typically used for invention features and listed in the claims
2.2 Patent life cycle
The patent life cycle encompasses several stages, from the initial conception of an invention to its eventual expiration. It can be broadly divided into pre-grant and post-grant phases (Fig. 4).

Patent life-cycle from the pre-grant to the post-grant stage
Pre-grant stage. In the beginning, inventors conceptualize, design, and develop their invention. If inventors hope to obtain patent protection for their invention, they need to apply to the patent office. To ensure novelty and inventiveness (non-obviousness), inventors may preventively search for existing patents and public disclosures to avoid unnecessary cost and effort in case of prior disclosures. Additionally, patent documents need drafting to describe the invention in detail, including its specifications, claims, abstract, and accompanying drawings. The drafting process typically requires the expertise of a patent professional, such as a patent engineer, attorney, or agent. After the patent application is submitted to the patent office, examiners at the office will screen and evaluate the application for compliance with formal, legal, and technical requirements. This examination typically involves correspondence of the examiner with the inventor or their representation, where clarifications, amendments, or arguments are submitted.Footnote 1 Notably, an assessment will determine if the invention meets the criteria for patentability, including novelty, inventiveness (non-obviousness), and typically less strictly commercial utility. The requirement of utility may be less strict as offices may see that as the applicant’s problem, except for certain cases. The substantive examination compares the invention with similar documents from the patent literature or any other public source dated earlier, which were found in an initial search by the office. Upon examination and potential resolution of any objections, the patent is either granted—rarely in its original, more frequently in a restricted form based on the identified prior art—or rejected. If the original priority date should be maintained, the invention must not be extended during the examination.Footnote 2
Post-grant stage. The granted patent is published, disclosing the details of the invention to the public potentially accompanying a previous application publication. As a remnant of previous pre-computer and pre-AI-search times, the offices classify patents by field of technology for easier search and management. Maintenance fees need to be paid regularly to keep the patent in force. The patent owner can enforce patent rights through legal action when infringement occurs. In addition, third parties can question the validity of patents, and patent owners would need to defend the challenges. Furthermore, companies can analyze patents for technology insights and derive strategies. Finally, the invention enters the public domain after the expiration of the related patents, allowing anyone to use it without infringement if no other rights cover those aspects.
2.3 Related surveys
Patent analysis. Various surveys in the past summarized certain aspects of patent analysis from a knowledge or procedural perspective. The work of Abbas et al. (2014) represents early research on patent analysis. These early methods included text mining and visualization approaches, which paved the way for future research. Deep learning for knowledge and patent management started more recently. Krestel et al. (2021) identified eight types of sub-tasks attractive for deep learning methods, specifically supporting tasks, patent classification, patent retrieval, patent valuation, technology forecasting, patent text generation, litigation analysis, and computer vision tasks. Some surveys reviewed specific topics of patent analysis. For example, Shalaby and Zadrozny (2019) surveyed patent retrieval, i.e., the search for relevant patent documents, which may appear similar to a web search but has substantially different objectives as well as constraints and has a legally-defined formal character. A concurrent survey introduced the latest development of patent retrieval and posed some challenges for future work (Ali et al. 2024). In addition, Balsmeier et al. (2018) highlighted how machine learning and NLP tools could be applied to patent data for tasks such as innovation assessment. It focused more on methodological advancement in patent data analysis that complements the broader survey of tools and models used in NLP for patent processing.
Patent usage. The patent literature records major technological progress and constitutes a knowledge database. It is well known that the translation of methods from one domain to another or the combination of technology from various fields can lead to major innovation. Thus, the contents of the patent literature appear highly attractive for systematic analysis and innovation design. However, the language of modern patents has substantially evolved and diverged from normal technical writing. Recent patent documents are typically hardly digestible for the normal reader and also contain deceptive elements added for increasing the scope or to camouflage important aspects. Appropriate data science techniques need to consider such aspects to mine patent databases for engineering design (Jiang et al. 2022). Data science applied to this body of codified technical knowledge cannot only inform design theory and methodology but also form design tools and strategies. Particularly in early stages of innovation, language processing can help with ideation, trend forecasting, or problem–solution matching (Just 2024).
Patent-related language generation. Whereas the above-listed techniques harvest the existing patent literature for external needs, the strong text-based patent field suggests the use of language models in a generative way. Language processing techniques can, for instance, translate the peculiar patent language to more understandable technical texts, summarize texts, or generate patent texts based on prompts (Casola and Lavelli 2022). The recent rapid development of generative language models, especially large language models (LLMs) (Zhao et al. 2023) may stimulate more patent-related generation tasks.
Related topics. A variety of other tasks and applications also have close ties to the patent domain. For example, intellectual property (IP) includes copyrights, trademarks, designs, and a number of more special rights beyond patents. The combined intellectual property literature allows concordant knowledge management, technology management, economic value estimation, and information extraction (Aristodemou and Tietze 2018). The patent field is closely related to the general legal domain, because they share procedural aspects and the precision of language. Likewise, most patent professionals have substantial legal training or a law degree, and their work often involves legal aspects. Accordingly, NLP techniques in the more general field of law may influence patent-related techniques in the future (Katz et al. 2023).
3 Insights into patent texts
Patent language can differ from normal text in multiple aspects, which stimulates a variety of research and entails challenges for the field.
3.1 Long context
Most research so far has focused on short texts, such as patent abstracts and claims. However, titles and abstracts of patents can be surprisingly generic. Therefore, using patent descriptions that provide comprehensive details and specific embodiment of the invention for patent analysis is highly important, which is neglected by most of the current research. A possible reason is that previous language models cannot handle such long inputs. According to a recently proposed patent dataset (Suzgun et al. 2023), the average number of tokens of a patent description exceeds 11,000, which is longer than the context limit of many previous language models. For example, Llama-2 supports the context length of 4,000 tokens (Touvron et al. 2023). The reason for the limited context length of many language models is the rapid growth of computational complexity associated with self-attention. It grows because the number of attention relationships increases with the context length. As self-attention often considers every pair of tokens, the computational complexity can grow with the context length squared (\({\mathcal {O}}(n^2)\)). The long context of patent descriptions causes critical challenges for patent analysis.
Notably, researchers have investigated increasing or otherwise handling the context length of LLMs (Chen et al. 2023; Jiang et al. 2023; Xiong et al. 2023). Xiong et al. (2023), for example, introduced a series of long-context LLMs, which can support context windows up to 32,768 tokens. A mix of reduced short-range and long-range attention instead of exhaustive attention can reduce the computational and memory burden (Kovaleva et al. 2019; Beltagy et al. 2020). Moreover, the latest very large models, such as GPT-4Footnote 3 (OpenAI 2023) and Llama-3.1Footnote 4 (Dubey et al. 2024) even naturally support a context length of 128,000 tokens, which appears promising to process long patent descriptions. Other LLMs also indicate a trend towards long context capabilities, such as Falcon-180B (Almazrouei et al. 2023), Gemini 1.5Footnote 5 (Reid et al. 2024) and Claude 3.5Footnote 6 (Anthropic 2024).
3.2 Technical language
The patent language is highly technical and artificial, including specialized terminology, legal phrases, and sometimes newly coined terms to describe new concepts that may not yet have been widely recognized. Patents regularly define their own terms. As those terms are often coined by an attorney who needs to name an element, they can substantially deviate from everyday language usage and also the specific technical field. Such self-defined terms are often highly artificial and not likely to occur in other relevant documents or even in any dictionary.
Hence, the technical language causes significant challenges for general LLMs for patent analysis, which are trained on normal texts and a large share of more colloquial language. Thus, LLMs may not capture the patent context information effectively, because the important technical terms can be completely new to the LLMs or have different meanings from its pre-training corpora. Embeddings based on distance metrics for synonymity or semantic relationships of terms may not work if terms are defined contrary to their normal use or are entirely new.
3.3 Precision requirement
The precision requirement and information density of patent texts are higher than in everyday language.Footnote 7 The patent language focuses more on precision and accuracy than on readability. Patent texts must be precise and meticulously described to ensure the patent is both defensible and enforceable. Such precision requirement typically leads to high repetitiveness in both terminology and structure of sentences, paragraphs, and sections. Furthermore, sentences are often overburdened because they use relative or adverbial clauses to include specifications for precision or add examples for a wider scope. Additionally, each terminology must be used consistently throughout the document. That means a technical term must not be replaced by other words unless the patent explicitly states that both are identical. In contrast, everyday texts and academic literature tend to vary and paraphrase the wording for better readability. In addition, the patent claim is carefully crafted to define the precise scope and boundaries of the invention’s protection, ensuring that the patent can withstand legal scrutiny.
The precision requirement of patent texts complicates the patent generation tasks because LLMs are likely to generate slightly different words or phrases. Due to the requirement for large quantities of data, most pre-training corpora for LLMs tend to be colloquial and relatively informal. Another smaller portion comes from literary texts, which may be of higher quality but typically prioritize style and linguistic originality over precision and accuracy.
3.4 LLMs for patent processing
Patent texts are distinct from everyday texts with respect to long context length, in-depth technical complexity, and high precision to ensure the patent can be granted, defended, and enforced. This type of language often necessitates specific training and experience in patents for accurate reading and interpretation. However, human readers usually struggle with certain aspects of patent texts, such as ambiguous names, phrases that conflict with the readers’ prior understanding, or numerous terms that the description redefines within the context of the specific patent itself. The dense, specialized terminology and unconventional syntactic structures common in patents often pose significant barriers to comprehension, even for those with experience in technical fields. In contrast, LLMs trained on datasets specifically tailored to patent language are theoretically well-equipped to handle these challenges. They are designed to process complex syntactic structures, manage long-range dependencies, and incorporate newly coined terms or domain-specific jargon that diverges from everyday language. By leveraging the specialized vocabulary of experts in the field, these models can navigate the nuanced requirements of patent texts with a level of consistency and scope that may exceed human capabilities. Therefore, the recent advancements in LLMs (Zhao et al. 2023) for generative tasks and language processing appear ideally suited for the unique characteristics of patent literature. They promise large benefits in areas such as patent drafting, prior art search, and examination.
Despite the apparent fundamental compatibility of LLMs for knowledge extraction and language processing, the application of LLMs in the patent domain remains underdeveloped and not yet highly prominent. Previous studies used word embeddings (e.g., Word2Vec (Mikolov et al. 2013)) and deep learning models (e.g., LSTM (Hochreiter and Schmidhuber 1997)) for patent analysis tasks. As transformers (Vaswani et al. 2017) showed significant potential in text processing, researchers started to develop transformer-based language models, such as BERT (Devlin et al. 2018) and GPT (Radford et al. 2018). The recent large-sized models with outstanding capabilities have not been extensively investigated in the patent field. Some representative general LLMs that are worth exploring include the Llama-3 family (Dubey et al. 2024), Mistral (Jiang et al. 2023), Mixtral (Jiang et al. 2024), GPT-4 (OpenAI 2023), Claude 3 (Anthropic 2024), DeepSeek-V3 (Liu et al. 2024), and Gemini 1.5 (Reid et al. 2024). Researchers have also developed patent-specific LLMs, such as PatentGPT-J (Lee 2023) and PatentGPT (Bai et al. 2024). However, PatentGPT-J has shown limited performance in patent text generation tasks (Jiang et al. 2024), and PatentGPT, though promising, is a recent development that is not yet publicly available. Significant work related to patent-specific LLMs remains to be done. Moreover, since patents represent a type of legal document, law-specific LLMs are also worth investigating, such as SaulLM (Colombo et al. 2024).
Previous research efforts have included patent analysis, data extraction, and automation of procedures. However, the lack of benchmark tests, such as reference datasets and established metrics, hinders performance evaluation and comparison across different methods. The effectiveness of LLMs depends on the quality of training data. To this end, we have compiled sources and databases of patents with curated datasets tailored for various patent-related tasks in Sect. 4. Although patent offices have released raw documents for years, publicly available datasets for specific tasks remain scarce. Numerous studies continue to use closed-source data for training and evaluation. Furthermore, patent offices do not provide pre-processed data or broad access to well-structured documents from the process around patents. Although in many countries, patent documents as the disclosure of inventions are considered public domain, they offer only the manual review of individual documents.Footnote 8 The pre-processing steps to formulate structured patent datasets generally involve: segmenting patent documents into clearly defined sections to enhance downstream tasks, such as abstract, claims, description, etc., and rectifying irregularity issues, such as missing fields, erroneous characters, or formatting issues.
Previous research prominently focuses on short text parts of patents, such as titles and abstracts. However, these texts are typically highly generic and include the least specific texts with little information about the actual invention. These texts also take little time during drafting, which renders the automated creation of these parts less helpful. By contrast, patent descriptions need to include all details of an invention, and patent claims clearly define the legal boundaries of the invention’s protection, the so-called scope. Since these texts are longer and contain much more useful information, they are worth more attention for both patent analysis and generation.
3.5 Multimodal techniques
A patent is not merely a text document but can include drawings, i.e., visual components. Thus, multimodal methods such as CLIP (Radford et al. 2021) and vision transformers (Dosovitskiy 2020) may unlock this potential. Multimodal methods in patent processing integrate diverse data types, such as text, images, and quantitative information, to enhance tasks such as classification and retrieval. The combination of their complementary strengths of different modalities may lead to more comprehensive and accurate results. Lee et al. (2022) for instance introduced a multimodal deep-learning model that combined textual content with quantitative patent information, which resulted in improved performance for patent classification tasks. Additionally, multimodal approaches that integrate textual descriptions with visual content have shown promise in enhancing patent retrieval (Lo et al. 2024). Furthermore, Lin et al. (2023) proposed multimodal methods to extract structural and visual features to effectively measure patent similarity. Such multimodal similarity detection may improve the efficiency of patent examination. However, as illustrated in Fig. 3, many drawings in patents are generic without the corresponding description, and some drawings suffer from poor resolution, pixelation, or low quality. This may be one of the reasons why current multimodal methods in patent processing are scarce. Moreover, textual elements, especially the claims and descriptions, are the primary carriers of legally binding information in patents, particularly features. While drawings provide valuable support and document embodiments, the text is essential for defining the scope, novelty, and context of each invention. Consequently, the survey particularly examines NLP approaches and includes representative multimodal methods where available.
4 Data
4.1 Data sources
Patent applications are submitted to and granted by patent offices. To stimulate innovation and serve the society, patent offices provide detailed information about existing patents, patent applications, and the legal status of patents—previously on paper, nowadays online. Large patent offices include the United States Patent and Trademark Office (USPTO) and the European Patent Office (EPO). These offices also provide access to download bulk datasets or tools to explore and analyze patent data. For example, PatentsView is a platform developed by the USPTO, which provide accessible and user-friendly interfaces to explore US patent data, with various tools for visualization and analysis. Apart from patent offices, there are searchable databases that contain patents from multiple countries and offices, such as Google Patents. We list a broad range of patent offices and databases in Table 1.
4.2 Curated data collections
Datasets. Patent offices provide large-scale raw data in the patent domain. Developers and researchers rely on well-curated datasets for development and research. We summarize representative publicly available curated patent datasets in Table 2. We aim to reduce the time and effort for data searching in the patent domain by presenting these ready-to-use datasets.
The number of curated datasets for patent classification and patent retrieval is typically larger than others because the data collection process is simple. Each granted patent is assigned classification codes and contains referenced patents. Hence, researchers can formulate the datasets by collecting and filtering patents without further labeling. For patent novelty quantification and prediction, Arts et al. (2021) considered patents connected to awards such as a Nobel Prize as novel because they radically impacted technological progress and patenting. In contrast, patents were considered lacking novelty if they were granted by the United States Patent and Trademark Office but simultaneously rejected by both the European Patent Office and Japan Patent Office. However, this collection may deviate from the formal definition of novelty introduced in Sect. 5.4.1. For patent simplification, there is only a silver standard dataset (Casola et al. 2023). In text generation tasks, texts written by humans are usually considered the gold standard. Since patent simplification requires extensive expertise and effort, it is expensive and time-consuming to obtain a gold standard for patent simplification. Thus, Casola et al. (2023) adopted automated tools to generate simpler texts for patents and named it the silver standard.
Notably, the Harvard USPTO Patent Dataset (HUPD) (Suzgun et al. 2023) is a recently presented large-scale multi-purpose dataset. It contains more than 4.5 million patent documents with 34 data fields, providing opportunities for various tasks. The corresponding paper demonstrates four types of usages of this dataset, including granting prediction, subject classification, language modeling, and summarization.
Shared tasks. Some organizations proposed shared tasks and workshops in the patent domain to facilitate related research. Every participant worked on the same task with the same dataset to enable comparisons between different approaches.
The intellectual property arm of the Conference and Labs of the Evaluation Forum (CLEF-IP)Footnote 9 focuses on evaluation tasks related to intellectual property, particularly in patent retrieval and analysis. Each task usually contains a curated patent dataset for desired aims, including various information such as text, images, and metadata (Piroi and Hanbury 2017).
The Japanese National Institute of Informatics Testbeds and Community for Information access Research (NTCIR)Footnote 10 provides datasets and organizes shared tasks to facilitate research in information retrieval, natural language processing, and related areas. Patent-related tasks at the NTCIR range from patent retrieval and classification to text mining and machine translation (Utiyama and Isahara 2007; Lupu et al. 2017).
TREC-CHEMFootnote 11 is a part of the Text REtrieval Conference (TREC) series, specializing in chemical information retrieval. It contains patent datasets that are rich in chemical information. For example, the dataset from TREC-CHEM 2009 contains 2.6 million patent files registered at the European Patent Office, United States Patent and Trademark Office, and World Intellectual Property Organization (Lupu et al. 2009).
5 Patent analysis tasks
Patent analysis tasks focus on understanding and usage of patents. We divide patent analysis tasks into four main types, subject classification, information retrieval, quality assessment, and technology insights. Patent subject classification (Sect. 5.1) is one of the most widely studied topics in the patent domain, where the categories of patents are predicted based on their content. Information retrieval tasks consist of two sub-tasks, specifically patent retrieval (Sect. 5.2) and information extraction (Sect. 5.3). While patent retrieval aims at retrieving target documents from databases, information extraction focuses on extracting desired information from patent texts for further applications. Quality assessment refers to evaluating the quality of patents, which includes novelty prediction (Sect. 5.4), granting prediction (Sect. 5.5), litigation prediction (Sect. 5.6), and patent valuation (Sect. 5.7). As novelty is essential for patents, early prediction of novelty and auxiliary methods for novelty assessments could ensure patent quality before filing and improve efficiency. Granting prediction forecasts whether the patent office will grant a patent application. The process involves further aspects beyond novelty and inventiveness, such as formal requirements of the language, figures, and documents. A low-quality patent is likely to be rejected by the examiner. Litigation prediction measures the odds that the file may at some point become the subject of litigation. For example, patents with unclear or ambiguous claims or very scarce descriptions tend to be more likely to cause litigation cases. Patent valuation refers to measuring the value of the patents, which is a reflection of patent quality and scope. Technology insights are the usage of patents, consisting of technology forecasting (Sect. 5.8) and innovation recommendation (Sect. 5.9). Since patents contain extensive emerging technology information, researchers can analyze patents to predict future technological development trends or suggest new ideas for technological innovation.
5.1 Automated subject classification
5.1.1 Task definition of subject classification
The automated subject classification task is a multi-label classification task. The aim is to predict patents’ specific categories or classes based on patent content, including title, abstract, and claims. Given a sequence of inputs \(x=[w_1, w_2, \ldots, w_n]\), the objective is to predict the label \(y \in \{y_1, y_2, \ldots, y_m\}\). Since patents may belong to multiple classes, sometimes more than one label needs predicting. This classification is crucial for organizing patent databases, facilitating patent searches, and assisting patent examiners in evaluating the novelty.
5.1.2 Classification scheme
Two of the most popular classification schemes are the International Patent Classification (IPC) and Cooperative Patent Classification (CPC) systems. These IPC/CPC codes are hierarchical and divided into sections, classes, sub-classes, main groups, and sub-groups. For example, we list the breakdown of the F02D 41/02 label using the IPC scheme in Table 3.
5.1.3 Evaluation
Most research uses one or more evaluation measures originated from Fall et al. (2003). As Fig. 5 illustrates, there are three different evaluation methods, namely top prediction, top N guesses, and all categories. Top prediction only checks whether the top-1 prediction is the same as the main class. In top N guesses, the result is successful if one of the top-n predictions matches the main class, which is more flexible compared to the top-1 prediction. On the other hand, the all-categories method checks whether the top-1 prediction is included in the set of the main class and all incidental classes.

Illustration of three evaluation methods for patent classification, where 1, 2,..., n are the top-n predictions, MC stands for main class, and IC is incidental class (Fall et al. 2003)
5.1.4 Methodologies for automated subject classification
We summarize the mainstream techniques for patent classification and categorize them into three types, including feature extraction and classification, fine-tuning transformer-based language models, and hybrid methods (Fig. 6).

Three mainstream methods for patent classification
Feature extraction and classifier. Researchers extract various features from patent documents and adopted a classifier for prediction based on the features (Shalaby et al. 2018; Hu et al. 2018; Abdelgawad et al. 2019; Zhu et al. 2020).
Most of the research used text content for prediction. Before the prevalence of deep learning, researchers explored text representations, such as unigrams, bigrams, and syntactic phrases, for automated patent classification (D’hondt et al. 2013), but the performance was limited. Nowadays, the commonly used text representation is word embedding, a deep learning-based pre-trained model that establishes a quantitative space and paradigmatic relationships between words. Roudsari et al. (2021) compared five different text embedding approaches, including bag-of-words, GloVe, Skip-gram, FastText, and GPT-2. Bag-of-words is based on word frequency and ignores semantic information. GloVe, Skip-gram, and FastText are deep learning methods that capture word meaning but not word contexts. In contrast, GPT-2 is based on transformer architecture and is capable of capturing complex contextual information. The results demonstrated that GPT-2 performed the best with a precision of 80.52%, indicating that transformer-based embedding approaches may perform better than other traditional or deep-learning embeddings. In addition, word embeddings are typically pre-trained on heterogeneous corpora, such as Wikipedia, which lets them lack domain awareness. Therefore, Risch and Krestel (2019) trained a domain-specific word embedding for patents and incorporated recurrent neural networks for patent classification. This method improved the precision by 4% compared to normal word embedding, demonstrating the effectiveness of domain adaptation. Apart from word embeddings, researchers also adopted sentence embedding for feature extraction (Bekamiri et al. 2021). Other research calculated the semantic similarity between patent embeddings obtained from Sentence-BERT (Reimers and Gurevych 2019) and used the k-nearest neighbors (KNN) method for classification with a precision of 74%. Although the performance was not strong enough, the use of similarity and KNN provided a different view of the classification approach.
In addition, some research studied variations of network architecture and optimization methods. Shalaby et al. (2018) improved original paragraph vectors (Le and Mikolov 2014) to represent patent documents. The authors used the inherent structure to derive a hierarchical description of the document, which was more suitable for capturing patent content. In addition, Abdelgawad et al. (2019) analyzed hyper-parameter optimization methods for different neural networks, such as CNN, RNN, and BERT. The results illustrate that optimized networks could sometimes yield 6% accuracy improvement. Similarly, Zhu et al. (2020) used a symmetric hierarchical convolutional neural network and improved the F1 score by approximately 2% on the Chinese short text patent classification task compared to a conventional convolutional neural network.
Alternatively, images can also serve for automated patent classification, which is introduced in Appendix A.1.
Fine-tuning transformer-based language models. Fine-tuning tailors the pre-trained model to the patent classification task. Lee et al. fine-tuned the BERT model for the patent classification task and achieved 81.75% precision (Lee and Hsiang 2020b), which was more than 7% higher than traditional machine learning under the same setting, using word embedding and classifiers (Li et al. 2018). Moreover, Haghighian et al. (2022) compared multiple transformer-based models, including BERT, XLNet, RoBERTa, and ELECTRA, where XLNet performed the best regarding precision, recall, and F1 score. Furthermore, research found that incorporating further training approaches can optimize the fine-tuning process. For example, Christofidellis et al. (2023) integrated domain-adaptive pre-training and used adapters during fine-tuning, which improved the final classification results by about 2% of F1 score. Transformer-based language models have demonstrated better effectiveness than traditional text embedding and become the mainstream method for text-based problems.
Another study treated this hierarchical classification task as a sequence generation task. Risch et al. (2020) implemented transformer-based models to follow the sequence-to-sequence paradigm, where the input was patent texts and the output was the class, such as F02D 41/02. However, the highest accuracy tested on their datasets reached only 56.7%, which demonstrated that the sequence-to-sequence paradigm for patent classification was mediocre.
Hybrid methods. Hybrid methods refer to combining different approaches to infer predictions. TechDoc (Jiang et al. 2022) is a multimodal deep learning architecture, which synthesizes convolutional, recurrent, and graph neural networks through an integrated training process. Convolutional and recurrent neural networks served to process image and text information respectively, while graph neural networks served for the relational information among documents. This multimodal approach was able to reach greater classification accuracy than previous unimodal methods. The advantage of multimodal models is to leverage different modalities for a comprehensive prediction.
Additionally, Zhang et al. (2022) used a multi-view learning method (Zhao et al. 2017) for patent classification. Multi-view learning integrates and learns from multiple distinct feature sets or views of the same data, aiming to improve model performance by leveraging the complementary information available in different views. In a general multi-view learning pipeline, developers specify a model in each view. They aggregate and train all models collaboratively based on multi-view learning algorithms. Zhang et al. (2022) used the two views of patent titles as well as patent abstracts and tested multi-view learning on a Chinese patent dataset to demonstrate its effectiveness and reliability.
Moreover, a recent study investigated ensemble models that can combine multiple classifiers (Kamateri et al. 2023). While multi-view learning exploits diverse information from different data sources for a more comprehensive understanding, ensemble methods focus on combining predictions from multiple models to improve prediction accuracy and robustness by reducing the models’ variance and bias, which may all use the same data view. The authors experimented with different ensemble methods and finally achieved 70.71% accuracy, which was higher than using only one classifier.
For a synopsis, we list some representative papers in Table 4, including data sources, dataset size, parts used for training, number of classes, methods, and results. The table shows that researchers use different datasets and metrics to test their models, which complicates the comparison of various methods. Hence, we call for standard benchmarks for patent classification to facilitate the development. In addition, LLMs demonstrate more promising results compared to traditional ML models. However, most research is still based on outdated models, such as GPT-2. The application of recent large-sized LLMs to this task would enhance the effectiveness. Additionally, most research has focused on short texts for patent classification, such as abstracts and claims. Nonetheless, titles and abstracts of patents are generic and do not disclose much relevant information. We recommend that future research focuses more on detailed patent descriptions that contain detailed and specific information about an invention. Furthermore, domain-adaptive methods that adapt standard LLMs to the patent domain are worth investigating to optimize the performance.
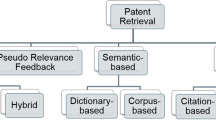
5.2 Patent retrieval
There are three types of retrieval tasks, prior-art search, patent landscaping, and freedom to operate search. Since previous research mainly focused on prior-art search, we introduce this task first in Sect. 5.2.1 with its corresponding methods in Sect. 5.2.2, followed by patent landscaping in Sect. 5.2.3 and freedom to operate search in Sect. 5.2.4.
5.2.1 Task definition of prior-art search
Prior-art search refers to, given a target patent document X, automatically retrieving K documents that are the most relevant to X from a patent database.Footnote 12 This process is crucial for patent examiners to assess the patentability of a new patent application. Prior-art search is not trivial, due to the intricate patent language and the different terms used in various patent descriptions. In principle, documents from distant fields, including both patent literature and other sources, can compromise the novelty of a new application if they disclose the same combination of patent features. However, these different fields often use distinct nomenclature across all word classes, including nouns, verbs, and adjectives. Additionally, many patents and patent applications create their own terms, which can significantly differ from everyday language and even from the terminology used in the technical field. This creation of terms is not always intentional. Attorneys and patent professionals, who may not be deeply familiar with a specific field, might need precise terms for their descriptions and claims and thus decide to invent names spontaneously. These self-defined terms are often highly artificial and may not appear in any other relevant documents. Such terms do not need to be listed in any dictionary.
5.2.2 Methodologies for prior-art search
Researchers have intensively invested in patent retrieval tasks and achieved some encouraging accomplishments. We summarize the general retrieval process in Fig. 7. Data types for further pre-processing include text, metadata, and images. Multiple methods can transform patent data into numerical features, such as the statistical method term frequency-inverse document frequency (TF-IDF), which is widely known from text-based search systems, and deep-learning-based word embedding. Relevance ranking algorithms to retrieve the most relevant documents include best-matching BM25, which is a bag-of-word-type method, and cosine similarity derived from the inner vector product.

Illustration of the patent retrieval process
We focus on text-based patent retrieval in this section and introduce other methods in Appendix A.2. Traditional methods are keyword-based search and statistical approaches that can rank document relevance, such as the BM25 algorithm (Robertson et al. 2009). Keyword-based methods refer to a search for exact matches in the target corpus according to the input query. A previous survey summarized all keyword-based methods into three categories, namely query expansion, query reduction, and hybrid methods (Shalaby and Zadrozny 2019). On the other hand, statistical methods exploit a document’s statistics, such as the frequency of specific terms, to calculate a relevance score based on the inputs. For example, the BM25 algorithm calculates the sore using the occurrence of the query terms in each document. These methods are straightforward but the significant semantic and context information has not been explored. Furthermore, each patent document may use its own nomenclature, which may be defined in the description counter-intuitively to daily use.
Researchers proposed two types of improvement to enhance the patent retrieving performance, from keyword-based to full-text-based and from statistical methods to deep-learning methods. Errors occur inherently in keyword-based methods because different keywords can represent the same technical concepts across various disciplines. Hence, Helmers et al. (2019) adopted entire patent texts for similarity comparison and evaluated various feature extraction methods, such as bag-of-words, Word2Vec, and Doc2Vec. The results demonstrated that full-text similarity search could bring better retrieval quality. Moreover, a large body of research studied different deep learning-based embeddings that transfer texts to numerical values for similarity calculation (Sarica et al. 2019; Hain et al. 2022; Hofstätter et al. 2019; Deerwester et al. 1990; Althammer et al. 2021; Trappey et al. 2021; Vowinckel and Hähnke 2023). Since word embeddings cannot capture contextual information at a higher level, Hofstätter et al. (2019) improved the Word2Vec model by incorporating global context, which yielded up to 5% increase in mean average precision (MAP). At the paragraph level, Althammer et al. (2021) evaluated the BERT-PLI (paragraph-level interactions), which is specifically designed for legal case retrieval (Shao et al. 2020), in both patent retrieval and cross-domain retrieval tasks. However, the authors observed that the performance did not surpass the BM25 baseline and indicated that BERT-PLI was not beneficial for patent document retrieval. In another work, Trappey et al. (2021) trained the Doc2Vec model, an embedding that can capture document-level semantic information, based on patent texts for patent recommendation. Patent recommendation aims to retrieve target patent documents from the database. The results showed that Doc2Vec led to more than 10% improvement compared to bag-of-words methods or word embeddings. This research suggests that document-level embeddings are more promising for document retrieval because they can effectively capture context information.
LLMs have demonstrated effectiveness in text retrieval tasks (Ma et al. 2023). Thus, LLMs for patent prior-art search are a promising research direction. In addition, studies have shown that integrating retrieval into LLMs can improve factual accuracy (Nakano et al. 2021), downstream task performance (Izacard et al. 2023), and in-context learning capabilities (Huang et al. 2023). These retrieval-augmented LLMs are well-established for handling question-answering tasks (Xu et al. 2024). The application of retrieval-augmented generation in the patent domain is another interesting research direction.
5.2.3 Patent landscaping
Patent landscaping aims to retrieve patent documents related to a particular topic. Landscaping might have a larger overall strategic value for companies and be more related to the machine-learning topic. However, patent landscaping is much less investigated compared to prior-art search.
It is straightforward to relate landscaping to prior-art search in two ways. First, we can consider the target topic as a keyword for patent retrieval and use keyword-based methods to retrieve documents from the database. Alternatively, we can find seed patents to represent the topic and retrieve documents that are related to the seed patents as the result (Abood and Feltenberger 2018).
Furthermore, researchers developed classification models for patent landscaping, which classify whether a patent belongs to a given topic (Choi et al. 2022; Pujari et al. 2022). Choi et al. (2022) concatenated text embedding of abstracts and graph embedding of subject categories for patent representations. Subsequently, the authors added a simple output layer to conduct the necessary binary classification task. To stimulate the research on patent-landscaping-oriented classification, Pujari et al. (2022) released three labeled datasets with qualitative statistics.
5.2.4 Freedom-to-operate search
The freedom-to-operate (FTO) search, also known as the clearance search, is a specific type of patent-related research. The aim is to determine if a particular technology or product would be covered by any active intellectual property rights of another party. This search is critical for companies before launching a new product or service in the market and may be requested by investors as part of a due-diligence process.
This task shares similarities with a prior-art search but entails an important difference: The search for prior art takes the technology in question and checks if any prior record (not limited to patent documents or active patents) alone (novelty) or in combination (inventiveness/obviousness) contains all the features of the technology. Thus, the search analyzes if the technology is entirely part of the prior art. The documents or other records of the prior art anticipating the technology may also contain more features in their claims. In contrast, the search for freedom to operate checks if there is any active patent (or application still in examination), where an independent claim has fewer features (constituting a more general invention) than the technology in question requires. Thus, individual claims of relevant prior-art documents are practically in their entirety included in the technology. Accordingly, although a technology might be patentable as well as granted due to its novelty and inventiveness, it could still be covered by an earlier patent or pending application if it incorporates the features of the prior art alongside some additional nonobvious features. Therefore, the new invention would be classified as a more specific dependent invention. Owners of such overlapping earlier patents could therefore interfer with the use of such dependent IP.
Following the task definition, a freedom-to-operate search needs to analyze the claims of potentially relevant patents (applications) in detail and break down the technology in question. Hence, the automated retrieval of targeted patent claims is the core of this task. Few studies have investigated this type of retrieval task. Freunek and Bodmer (2021) trained BERT for the freedom-to-operate search process. They cut patent descriptions into pieces and use BERT to retrieve relevant claims from a constructed dataset. Their report demonstrated that BERT was able to identify relevant claims in small-scale experiments. As this task is important but widely neglected by the community, we introduce it here and suggest it for future research.
5.3 Information extraction
5.3.1 Task definition of information extraction
The process of extracting specific information from a text corpus is called information extraction. The goal of information extraction is to transform textual data into a more structured format that can be easily processed for various applications, such as data analysis. Hence, researchers usually use information extraction as a support task for patent analysis. Figure 8 demonstrates how information extraction is applied in the patent domain. Rule-based and deep-learning-based methods are two main streams of information extraction. The extracted information can be entities, relations, or knowledge graphs, which are constructed based on entities and relations. This information can serve for further tasks, such as patent analysis and patent recommendations for companies.

Demonstration of information extraction process in patent domain
5.3.2 Methodologies for information extraction
Rule-based methods. Traditional extraction methods are rule-based. Researchers manually pre-define a set of rules and extract desired information based on the rules. Chiarello et al. (2019) designed a rule-based system to extract affordances from patents. For example, one of the rules was “The term user followed by can and adverbs, such as readily efficiently, quickly and easily.” The authors used the extracted results to evaluate the quality of engineering design. Another study devised rules according to the syntactic and lexical features of claims to extract facts (Siddharth et al. 2022). The authors integrated and aggregated these facts to obtain an engineering knowledge graph, which could support inference and reasoning in various engineering tasks.
Well-defined rules can lead to precise extraction so that this process is transparent and interpretable. However, creating and maintaining rules can be time-consuming, difficult, and biased. Moreover, rule-based methods may struggle with the variability and complexity of natural language.
Deep-learning-based methods. Deep learning methods require labeled datasets that include entities or relations for training. There are different network architectures for model training, such as long short-term memory (LSTM) (Chen et al. 2020) and transformers (Son et al. 2022; Puccetti et al. 2023; Giordano et al. 2022). Notably, Son et al. (2022) stated that most patent analysis research focused on claims and abstracts but neglected description parts that contain essential technical information. The reason may be the notably larger length of the description, which requires appropriate models that can load such text length. Thus, the authors proposed a framework for information extraction through patent descriptions based on the T5 model.
Deep-learning methods can handle a wide variety of language expressions and are easily scalable with more data and computational power. Moreover, deep learning can capture complex patterns and dependencies in language. Nonetheless, deep learning requires large quantities of high-quality annotated data and computation resources for training.
5.3.3 Applications of information extraction
Patent analysis. Patent analysis involves the analysis of patents with respect to multiple aspects, such as evaluating patent novelty or quality, and forecasting technology trends. For example, Chiarello et al. (2019) extracted sentences with a high likelihood of containing affordance from patents to evaluate the quality of engineering design, for example: “The user can easily navigate a set of visual representations of the earlier views.” Puccetti et al. (2023) identified technologies mentioned in patents to anticipate trends for an accurate forecast and effective foresight.
Patent recommendation. Patent recommendation refers to suggesting relevant patents to users based on their interests, research, or portfolio. Deng and Ma (2021) extracted the semantic information between keywords in the patent domain and constructed weighted graphs of companies and patents. The authors compared the distance based on weighted graphs to generate recommendations. Chen and Deng (2023) extracted connectivity and quality attributes for pairs of patents and companies. Based on knowledge graphs and deep neural networks, the authors designed an interpretable recommendation model that improved the mean average precision of best baselines by 8.6%.
Engineering design. Engineering design is a creative process that involves defining a problem, conceptualizing ideas, and implementing solutions. The goal is to develop functional, efficient, and innovative solutions to meet specific requirements. Designers can gain insight by analyzing problems and principal solutions extracted from patent documents. Giordano et al. (2022) adopted transformer-based models to extract technical problems, solutions, and advantageous effects from patent documents and achieved an F1 score of 90%. The extracted information helps reveal valuable information hidden in patent documents and generate novel engineering ideas. Similarly, Jiang et al. (2023) used pre-trained models to identify the motivation, specification, and structure of inventions with the accuracy of 63%, 56%, 44% respectively compared to expert analysis. From design intent to specific solutions, designers can review patents from a systematic perspective to gain better design insights.
The recent LLMs have shown outstanding capabilities in information extraction, such as in complex scientific texts (Dunn et al. 2022) and medical domain (Goel et al. 2023). Therefore, we anticipate the application of LLMs in the patent field to improve the quality of information extraction.
5.4 Novelty and inventiveness prediction
5.4.1 Definition of patent feature, novelty, and inventiveness
Novelty and inventiveness have a clear legal definition in most jurisdictions,Footnote 13 which may strongly deviate from common associations (European Patent Office 2000; United States Patent and Trademark Office 2022). An invention is conceived as a combination of features. It is novel if there is no older document or other form of disclosureFootnote 14 that alone includes and/or describes all essential features of the invention. In contrast, an invention may be considered inventive for two reasons: (1) All prior disclosures combined do not reveal each of its essential features. (2) Experts in the field would not find it obvious to integrate any missing features, for instance, according to their standard practice within the field.
Thus, the assessment of novelty critically relies on the concept of features. The features are the elements the invention needs to comprise to be the invention and are outlined in the patent claims. The independent claims list the essential features. For example, features can be physical elements and objects (typically nouns together with further specifiers), properties (often adjectives), or processing steps in a method.
Importantly, features in many jurisdictions cannot be implicitly negative, i.e., a missing property. Some offices allow the exclusion of a specific technology from the prior art through explicit negative limitations, but only if the description clearly states the absence of the feature as a property of the invention. Later exclusion of features in the claims based on merely an absence of the feature in the description is not possible. For example, a claim could specify “not using cloud storage” to clarify that the claimed invention operates solely on local servers. This limitation would be valid if the description explicitly states an advantage or purpose for not allowing cloud storage. The false negative rate (FPR) is particularly useful to measure the model’s performance in handling negative limitations, as it tracks instances where the model incorrectly interprets negative limitations. A low FPR is ideal and would indicate that the model rarely misinterprets positive statements as negative limitations.
The same feature can have very different names in different documents or even be denoted by a neologism well-defined in corresponding invention descriptions. The high variability of terminology between different documents is a major challenge for the examination and also for LLMs. Therefore, novelty prediction is a well-specified task by law and exhibits a high level of mathematical precision atypical of other language-related tasks. In contrast, inventiveness, determining whether the addition of certain features to existing technology is obvious to an expert, can often be ambiguous.
5.4.2 Task definition of novelty and inventiveness prediction
Novelty and inventiveness prediction is a binary classification task, aiming to determine whether a new patent is novel, given the existing patent database.Footnote 15 Novelty is one of the essential requirements of patent applications and takes a vast of resources and time for human assessment. In addition, the process of reviewing patents is complex and detail-oriented. Even experienced examiners can overlook critical information or fail in judgment. Automated patent novelty evaluation systems can be used as an auxiliary tool for novelty examination. Therefore, this system is critical, because it can not only improve the quality of patents but also enhance the efficiency of patent examination. Since novelty prediction is substantially based on text analysis, the recent LLMs appear well-suited for this complex task.
5.4.3 Methodologies for novelty and inventiveness prediction
Figure 9 illustrates key strategies for novelty prediction, which particularly include indicator-based methods, outlier detection, similarity measurement, and supervised learning.

Methods for patent novelty prediction
Indicator-based methods. Indicator-based approaches rely on pre-defined indicators to measure patent novelty compared to prior art (Verhoeven et al. 2016; Plantec et al. 2021; Sun et al. 2022; Wei et al. 2024; Schmitt and Denter 2024). Researchers define indicators from various aspects, such as the citations, and assign each indicator a score or weight based on its importance to calculate novelty scores.
For example, Verhoeven et al. (2016) proposed three dimensions to evaluate technological novelty, including novelty in recombination, novelty in technological origins, and novelty in scientific origins. They involved patent classification codes as well as citation information to analyze each indicator and demonstrated that technological novelty in each dimension was interrelated but conveyed different information. Additionally, Plantec et al. (2021) investigated technological originality, which was defined as the degree of divergence between underlying knowledge couplings embedded in the invention and the predominant design. The authors used proximity indicators of direct citations, co-citation, cosine similarity, co-occurrence, and co-classification, with normalization methods to balance different indicators.
Notably, most research focused on evaluating technological novelty and originality, which was different from the formal definition of patent novelty. While patent novelty is assessed based on prior art and disclosures in a legal context, technological novelty and originality are analyzed in a technical context, focusing on the advancement and uniqueness of the technological contribution. In addition, indicator-based methods also pose some limitations. The selection and weighting of indicators can be subjective, and the indicator may not fully capture the nuanced aspects of inventions.
Outlier detection. Outlier detection is based on the assumption that novel inventions can be seen as outliers within the landscape of existing patents (Wang and Chen 2019; Zanella et al. 2021; Jeon et al. 2022). Researchers used text embeddings to represent patents and applied outlier detection algorithms to identify patents that are different from the majority.
Researchers used the local outlier factor (LOF) for novelty outlier detection, which measured how isolated the object is with respect to the surrounding neighborhood (Breunig et al. 2000). For example, Zanella et al. (2021) used Word2Vec (Mikolov et al. 2013) to obtain text embedding based on patent titles and abstracts. Wang and Chen (2019) extracted semantic information by using latent semantic analysis (LSA) (Deerwester et al. 1990) based on patent titles, abstracts, and claims. These embeddings served as the input for LOF to measure the novelty of patents. However, this method deviates from the definition of patent novelty, because it does not measure outliers strictly by the features as suggested by the legal definition. Thus, these methods may correlate with the formal patent novelty but are not equivalent and therefore not necessarily useful for an automated examination process.
Furthermore, Jeon et al. (2022) used Doc2Vec (Le and Mikolov 2014) to process patent claims as input for LOF. Since patent claims describe features of inventions, this method seems plausible according to the legal definition of novelty. Nonetheless, there are still some questions that are not explained. For instance, the difference between text embeddings may not stand for a feature difference of inventions. Therefore, using LLMs to explicitly extract and compare features between the target patent and the prior art is a more sensible approach for novelty prediction.
Another limitation of LOF is that it sometimes flags patents that are unusual but not necessarily novel or original in a meaningful way. For example, a patent combining existing technologies in a statistically rare way may be classified as an outlier. However, such an outlier for statistical reasons without actual technical novelty does not represent a significant technological advancement.
Similarity measurements. Researchers calculate similarities between the target patent and existing patents for novelty assessment (Siddharth et al. 2020; Beaty and Johnson 2021; Arts et al. 2021; Shibayama et al. 2021). They used word embeddings based on the patent text, such as abstracts, and adopted various metrics to calculate the similarities, for example, cosine similarity and Euclidean distance. A patent with a low similarity score is considered more novel.
Previous studies have investigated different text representation methods for similarity calculation. For example, Arts et al. (2021) extracted keywords that related to the technical content of patents from titles, abstracts, and claims. Each patent is represented in a 1,362,971-dimensional vector, where each dimension was the frequency of a keyword. However, the authors considered patents with major impacts on technological progress as novel, which is different from the legal definition.
Additionally, Shibayama et al. (2021) compared Word2Vec (Mikolov et al. 2013) embeddings between the target patent and its cited patents based on abstracts, keywords, and titles. Nonetheless, patent titles and abstracts are generic and do not disclose patent features, thereby failing to assess patent novelty in the legal sense. It is worth noting that Lin et al. (2023) proposed multimodal methods that combine text and image analysis to leverage both structural and visual features to measure patent similarity, which enhanced performance.
Supervised learning. Supervised learning refers to training models to classify whether a given patent is novel, based on target patent texts and the prior art (Chikkamath et al. 2020; Jang et al. 2023).
Chikkamath et al. (2020) investigated a series of machine learning models for novelty detection. The authors conducted comprehensive empirical studies to evaluate the performance, including various text embeddings (e.g., Word2Vec (Mikolov et al. 2013), GloVe (Pennington et al. 2014)), different classifiers (e.g., support vector machine, naive Bayes), and multiple network architectures (e.g., LSTM (Hochreiter and Schmidhuber 1997), GRU (Chung et al. 2014)). The inputs are target patent claims and cited paragraph texts from prior art that are related to the target patent. This process makes sense because cited paragraphs possibly include features relevant to target patent claims, providing an implicit ground check for novelty. However, it is questionable whether the model detects novelty by comparing features rather than other aspects as deep learning models are typically black-box methods and lack explainability.
To address the problem, Jang et al. (2023) proposed an explainable model based on BERT (Devlin et al. 2018) to evaluate novelty. The authors aimed to follow the legal definition by comparing the claims of a target patent with its prior art. The model could output the novelty prediction result, along with claim sets with high relevance as an explanation, which achieved 79% accuracy under the experimental settings. This paper presented a great idea, but BERT is nowadays outdated and outperformed by larger and more powerful LLMs.
Suggestions for future work. Based on the review of previous studies, we provide three suggestions for future research. (1) Researchers should differentiate between patent novelty and other similar terms, such as technology originality. Patent novelty focuses on the invention’s features compared to the prior art in a legal context, whereas technological originality refers to the advancement and uniqueness of the technological contribution in the technical context. (2) Researchers should concentrate on specific patent content for assessing novelty. Using patent claims for prediction is a sensible approach as they include essential features for comparison. In contrast, studies that leverage titles and/or abstracts are not necessarily useful for an automated examination process, because they are usually generic and vain. (3) Researchers should explore the effectiveness of powerful LLMs, such as GPT-4, in this field. While LLMs have revolutionized the field of NLP, current studies on novelty prediction are still largely based on old-fashioned methods, such as word embeddings. Using LLM-based methods may significantly stimulate the automation of novelty prediction.
5.4.4 Patentability assessment
Patentability refers to a set of criteria that an invention must meet to be eligible for a patent. The key criteria typically include novelty, inventiveness/non-obviousness, and utility. Novelty that has been discussed above means the invention has not been known or used in the prior art. Non-obviousness indicates that a patent should include a sufficient inventive step beyond what is already known, and should not be obvious to an expert in the field. Utility means the invention is useful and has some practical applications. Therefore, patentability assessment is a more comprehensive and challenging task compared to novelty prediction.
While most works focused on novelty prediction, Schmitt et al. (2023) investigated patentability assessment by examining both novelty and non-obviousness following the legal definition. The authors used a mathematical-logical approach to decompose patent claims into features and formulate a feature combination. They compared the target patent feature combination with its prior art to evaluate novelty and non-obviousness based on the legal definition. The authors tested their approach on patent application US 2009/0134108. The independent claim was parsed into different features. The model compared each feature to text fragments in prior-art patents and calculated a similarity score for each comparison, which measures how closely the wording, context, and technical concepts in the feature match with those in prior patents. If a single prior patent includes all features with high similarity scores, it could mean the new patent lacks novelty. For non-obviousness, the model examined combinations of features across multiple prior documents. This example demonstrated this method’s efficacy in identifying critical overlaps between claimed and prior features. Since the authors only processed one example patent for a proof of concept, the effectiveness and efficiency of this method on large-scale patent applications are unknown. They pointed out another limitation, specifically that this method could not detect homonyms or synonyms. The recent LLMs with outstanding capability would undoubtedly contribute to this task both effectively and efficiently.
5.5 Granting prediction
5.5.1 Task definition of granting prediction
Patent granting prediction refers to predicting whether a patent application will be granted or terminally rejected by examiners (Fig. 10).Footnote 16 Previous works named this task patent acceptance prediction (Suzgun et al. 2023), but we correct it to granting prediction in this paper because patents are granted at best but not accepted. Such an automated method could support patent examiners, patent applicants, and external investors. Due to the complexity of patent examination, this process typically requires a long time. Some cases have still not achieved the final decision after two decades, when they typically expire at last. Thus, the automation of this process can help patent offices manage their workload more efficiently. If automated examination procedures achieve to be bias-free, artificial intelligence could reduce the existing examiner dependence and also likely speed up the procedure. Furthermore, such automated examination promises to increase the quality of examination, particularly its existing bias and variability. The quality of examination has been and is such a severe issue that it, for instance, led to the America Invents Act of 2011. In addition, patent applicants can gain valuable insight, be less exposed to bias and individuality of patent examiners, and improve the invention based on the prediction of the outcome. NLP may reduce the excessive cost, particularly for small companies, to participate in the intellectual property system. Currently, drafting applications and sending them for examination can generate overwhelming costs of thousands of dollars every round for small businesses without internal resources. Such bills further increase if an examiner shows little support and a hearing needs to be arranged in the process. Thus, automation of the intellectual property process has the chance to stimulate technology development and increase the overall technological competitiveness of a society. Similarly, investors can make better-informed decisions and create strategic plans according to the predicted outcome of patent applications.

Pipeline of patent granting prediction and litigation prediction
5.5.2 Methodologies for granting prediction
Only few studies have investigated granting prediction, probably because of the difficulty of the task. Yao and Ni (2023) applied machine-learning models to predict patent grant outcomes based on early-stage application data and aimed to identify key factors that influence patent approval. The XGBoost model achieved an AUC-ROC score of 0.854 and an overall accuracy of 77%. The study found that variables such as prior applicant experience, backward citations, patent family size, and document length were significant predictors of patent grant likelihood. Suzgun et al. (2023) provided baselines for patent granting prediction by training various models on patent abstracts and claims, such as convolutional neural networks (CNNs) and BERT. None of the accuracy levels was higher than 64%, which indicates a clear need for improvement. In addition, Jiang et al. (2023) proposed the PARCEL framework, which combines text data and metadata for patent granting prediction. PARCEL learns text representations from patent abstracts and claims by using the contextual bidirectional long short-term memory (LSTM) method and captures context information based on active heterogeneous network embedding (ActiveHNE) (Chen et al. 2019). The authors incorporated attention mechanisms when combining text and network attributes for final prediction. The results indicated that this method could achieve approximately 75% accuracy, which exceeds many previous models, such as PatentBERT (Lee and Hsiang 2020b). It is important to note that the datasets used in the above studies are different, so the results are not comparable directly. In summary, the prediction performance in any of the reported settings is far from satisfactory. Due to the high formality, intensive future research on this complex topic promises improvement.
5.6 Litigation prediction
5.6.1 Task definition of litigation prediction
Litigation prediction aims to predict whether a patent will cause litigation, typically between two companies. Patent litigation involves various types. For example, one of the most common scenarios in patent litigation is infringement, where patent holders claim that their patent rights are infringed. Additionally, third parties can question the patent validity, such as pointing out prior art that can prove the patent’s claims were not novel and/or inventive at the time of filing or the priority date.Footnote 17 An early identification of whether a patent might become the subject of litigation can help companies manage the quality of their patent portfolio (Wu et al. 2023).
5.6.2 Methodologies for litigation prediction
Manual litigation prediction is an expensive and time-consuming task for companies. It requires intensive reading and experience, and typically does still not exceed mere speculation. Hence, researchers developed different methods to automate the process, avoid personal bias with solid statistics, and reduce costs. Campbell et al. (2016) adopted multiple pieces of patent information to predict litigation with machine learning models. The authors combined metadata (e.g., number of claims, patent type), claim texts, and graph features that summarized patent citations to inform their predictions. In their results, the metadata had the highest impact on litigation prediction. Apart from patent contents, such as metadata and texts, Liu et al. (2018) incorporated lawsuit records of companies to collaboratively predict litigation between companies. The authors trained deep-learning models that integrated patent content feature vectors and tensors for lawsuit records. This method brought more than 10% gain in precision compared to text inputs only. Moreover, Wu et al. (2023) improved the numerical representations of patents and companies to capture the complex relations between plaintiffs, defendants, and patents more effectively. The authors demonstrated that this method could increase the performance by up to 10% compared to the previous approach and achieve robustness under various data-sparse situations. LLMs with sufficient context length to include also the description may provide further potential for litigation prediction. Pre-training LLMs on litigation and prosecution history data might be able to grasp some kind of understanding of patent language, reasoning patterns, and procedures. Additionally, GNNs, well-suited for relational data, could model interconnected events to infer causal relationships, which helps stakeholders assess how past prosecution actions influence future litigation.
5.7 Patent valuation
5.7.1 Task definition of patent valuation
The value of a single patent, patent applications, or an entire portfolio is highly important for young companies, where investment relies. However, the value of patents is not obvious and can reflect expectations as most immaterial assets do. Firstly, the single patents of a portfolio can have a lower value than the portfolio. Thus, patents owned by a third party may influence the value of a patent, e.g., if one depends on the other or if they solve the same problem with alternative solutions, i.e., feature sets. Furthermore, the value may depend on the function the specific patent(s) are supposed to fulfill and therefore also be different depending on the (potential) owner.
For blocking competitors or enforcing licensing deals, a single patent of a portfolio can be highly valuable if all the features of an independent claim are unavoidable. A single patent can thus turn into a road block for others. If, however, a patent application for the same purpose is significantly tattered during the examination that the independent claim requires substantial avoidable features, the patent is granted but without much value.
However, for the freedom-to-operate, patents should not contain dependencies, which means that active patents owned by others would need to be used to exploit the invention. Thus, in this case, the patent has only value in combination with rights to previous patents. Furthermore, the portfolio should ideally not leave too many gaps where others could establish themselves. In all those cases, however, the scope of the patent, i.e., how wide of a range the independent claims in the granted state after examination can cover, is an essential factor determining the value, although not the only one.
Early identification of high-value patents can help various industries and stakeholders establish optimal strategies. This task can be either a regression or classification problem (Fig. 11). The regression task aims to predict the actual number of the value. For example, Lin et al. (2018) used the number of citations as a measure of patent quality, because previous works have indicated that the number of citations is closely related to the patent value (Albert et al. 1991; Harhoff et al. 1999). However, the globally existing correlation between citations and patent value appears to include large variability; so it may not be the best individual predictor. More importantly, the citations typically trickle in after years, often when an assessment of the value of a patent is no longer needed. Other simpler and more accurate indicators may be already available, such as assigned revenue share in actual products, licensing fees, or sale of the patents.

Specifics of patent valuation tasks
In the context of binary classification, the purpose is to predict whether a patent is of high quality (Hu et al. 2023). Additionally, researchers classify the value of patents into different levels. For example, Zhang et al. (2024) graded the quality of patents into four classes based on expert consultation and questionnaire surveys.
5.7.2 Methodologies for patent valuation
Previous studies usually adopted pre-defined indicators for patent valuation. Hu et al. (2023) designed four dimensions to evaluate patent quality, including legal value, technological value, competitiveness value, and scientific value. The authors extracted and transformed the indicators into numerical values for training machine learning models. Additionally, Du et al. (2021) incorporated the patent inventors’ reputation as a new indicator and proved the effectiveness for patent quality evaluation.
Text data are also important for patent valuation. Researchers applied NLP to extract semantic features of patent texts for quality assessment, which contained detailed contextual information (Lin et al. 2018; Chung and Sohn 2020). Lin et al. (2018) used attention-based CNNs to extract semantic representation from patent texts, and adopted GNNs to represent patent citation networks and attributes. These feature vectors were concatenated to predict the quality of new patents. This method outperformed baseline approaches, such as using CNNs alone. Chung and Sohn (2020), on the other hand, used both CNNs and bidirectional LSTM for patent valuation classification based on abstracts and claims. The authors transformed texts into word embeddings as inputs and classified patents into three quality levels for prediction. The model achieved over 75% precision and recall in identifying high-value semiconductor patents.
Moreover, Liu et al. (2023) proposed a multi-task learning method that jointly trained classification models for the identification of high-value patents and standard-essential patents, i.e., patents that are required to implement a specific industry standard. These two tasks were related, which made the collaborative training effective. The average performance improvement was around 1–2% compared to single-task learning.
Linking patent texts with external product data can significantly streamline valuation and help organizations prioritize high-impact patents. Trappey et al. (2019), for example, developed deep-learning models to analyze over 6,000 internet-of-things (IoT) patents to evaluate their market value. The model could automatically select the most influential patents based on real-world product relevance. This approach enabled companies to focus on patents directly tied to essential IoT technologies, which would facilitate better IP management and informed investment decisions. However, it could also suppress groundbreaking technology disruptions in favor of more conformity with existing products.
5.8 Technology forecasting
Technology forecasting refers to the prediction of future technological developments based on existing patent data. Many businesses, researchers, and policymakers consider it important to understand the direction of technological innovation as well as design strategies, and adjust their investment. As technology forecasting is a broad concept, we summarize and categorize existing studies into three sub-types, specifically emerging technology forecasting, technology life-cycle prediction, and patent-application trend prediction (Fig. 12).

Specifics of technology forecasting tasks
5.8.1 Emerging technology forecasting
Emerging technology forecasting is primarily a binary classification task, which predicts whether a patent contains emerging technologies. This task may share similarities with some forms of patent valuation because high-value patents are more likely to become emerging. Due to the similarity with valuation, previous work identified emerging technologies by assessing the quality of patents (Lee et al. 2018). In addition, studies developed more elaborate machine-learning models for this task. Kyebambe et al. (2017) labeled a cluster of patents as emerging technology if it demonstrated evidence of possessing features that could introduce a new technological class shortly. The authors extracted patent information, such as patent class as well as number of citations, and trained various models (e.g., support vector machine, naive Bayes) that achieved approximately 70% precision.
As machine learning methods usually require large datasets for training, Zhou et al. (2020) aimed to evade this issue with a generative adversarial network (GAN). The authors labeled emerging technologies based on Gartner’s emerging technology hype cycles (GETHC), which aims to describe a specific stage of development of an emerging technology. They selected and extracted some patent attributes, such as the number of backward citations, to train machine learning models for prediction. Importantly, they incorporated a GAN to generate synthetic samples in the form of feature vectors for training. The synthetic data finally improved the prediction precision to 77% on the real test set.
While the above studies investigated emerging technologies from a technological perspective, researchers also evaluated social impacts based on related website articles (Zhou et al. 2021). The authors measure social impact through the frequency of patent-related keywords found in website articles, where website articles encompass all articles on emerging technology-related websites, and patent keywords are non-virtual words present in patent titles. They collected a multi-source dataset, including 129,694 patents and 35,940 website articles. They selected 11 patent indicators as inputs and classified social impacts into three levels as labels. Subsequently, they trained a deep-learning model that achieved 74% accuracy.
5.8.2 Technology life cycle prediction
The aim of technology life cycle prediction is to estimate the stages of a particular technology from its inception to the eventual decline. In established classifications, the typical stages of a technology life cycle include introduction, growth, maturity, and saturation (Mansouri and Mohammadpour 2023). The technology life cycle and the related technology adoption (as well as the hype cycle) are important aspects of innovation and product management.
The first stage involves the conception and initial development of the technology. If the technology proves viable, it will be adopted and developed rapidly, with an increase in market acceptance. As the technology becomes widely adopted, it enters a maturity stage. Finally, in the saturation stage, the previous technology will be replaced by a new one soon. Understanding and predicting the life cycle of a technology is a key part of strategic planning and market analysis, especially in fast-evolving fields like artificial intelligence. The phase of a technology affects the types of problems for a manufacturer (e.g., maturity, field experience, not established design rules as well as design optima, and reliability in early stages vs. mere cost focus later on), the type of customers (smaller customer segment of high-tech enthusiasts and soon early adopters vs. the later mass market), and also the company strategy (low-volume, high-profit high-tech companies vs. mass-market).
Previous studies used a hidden Markov model (HMM) for technology life-cycle prediction (Lee et al. 2016; Mansouri and Mohammadpour 2023). Researchers extracted several indicators from patents, such as patent class and citations, and investigated the state transferring probabilities. They trained the hidden Markov model to predict the probability of each phase in the future. However, using intrinsic indicators from patents as the sole predictor of technology life cycles may not be sufficient. The adoption and success of patents are heavily influenced by social needs and user acceptance. In addition, other extrinsic factors, such as market trends, competitive landscape, and strategic decisions, can influence the pace of technology adoption and development. Therefore, a multi-dimensional approach that combines intrinsic patent data with extrinsic information will likely provide a more accurate and holistic prediction of technology life cycles.
5.8.3 Patent application trend prediction
Patent application trend prediction aims to predict patent classification codes for which a company will apply in the future, given a sequence of patents that were previously applied by the same company. Precise forecasts of trends in patent applications can enable businesses to devise effective development strategies and identify potential partners or competitors in advance (Zou et al. 2023). Researchers implemented and tested dynamic graph representation learning methods for this task under various experimental conditions to demonstrate the effectiveness (Zou et al. 2023). Although the authors significantly improved the performance compared to machine-learning benchmarks, the recall was hardly higher than 20% on overall experiments, which indicates substantial room for improvement. Company-dependent patent application prediction is a newly proposed task and only few papers have investigated solutions.
5.9 Innovation recommendation
5.9.1 Task definition of innovation recommendation
Innovation recommendation refers to the process of suggesting new ideas or methods in a technology context. The automation of this task can enhance competitiveness, efficiency, or user experience. Innovation recommendations should help companies to identify novel research and development opportunities.Footnote 18
5.9.2 Methodologies for innovation recommendation
Figure 13 illustrates methods for innovation recommendation, including concept association analysis, technology gap detection, cross-domain analysis, and idea generation.

Methods for innovation recommendation
Concept association analysis. Researchers used NLP techniques to identify key concepts in patent documents and analyze their associations to discover novel combinations of concepts and suggest potential directions for innovation. For example, Song et al. (2017) identified technologies with technical attributes similar to a target technology. Thus, the authors could obtain novel technology ideas by applying these similar but distinct technical attributes to the target technology. From a patent-law perspective, it would be naturally interesting whether and how such technology ideas were synthesized out of existing patents. Potentially, the inclusion of intentional variability through higher temperature may lead to a more creative tool.
Technology gap detection. Technology gap detection algorithmically searches for areas within a technology field that are underdeveloped or unexplored. Such technology gaps can indicate new opportunities for research and innovation. TechNet is a large-scale network consisting of technical terms retrieved from patent texts and associated according to pair-wise semantic distances (Sarica et al. 2020). Sarica et al. (2021) focused on white space surrounding a focal design domain and adopted semantic distance to guide the inference of new technical concepts in TechNet. However, the strong dependency of TechNet on the terminology in patents may need further research because quite a number of patents form their own world of terminology and technical terms.
Cross-domain analysis. Cross-domain analysis links patents across different technological fields to find proper cross-domain techniques. Such cross-domain innovations can sometimes lead to breakthrough developments. Wang et al. (2023) applied causal extraction with a BERT-derived model to patents from different domains to output cause–effect matches to represent technology–application relationships that can undergo similarity comparison afterwards. The results are connections between patents from different fields that appear to have similarities in causality, presumably technology–application links, and may be good candidates to stimulate each other’s field. It supports cross-domain comparisons of technologies and applications to identify prospects for multiple applications of a specific technology. However, this approach may depend strongly on the terminology used in both patent texts.
Idea generation. Researchers developed generative language models to output innovative ideas automatically. A previous study fine-tuned the GPT-2 model to generate idea titles based on input keywords in a specific domain (Zhu and Luo 2022). The authors collected patent titles and extracted keywords from them. They used keywords as inputs and fine-tuned GPT-2 to generate titles. However, patent titles are often generic for legal reasons. For example, “charging station and methods to control it” covers almost any conceivable detail of a car charger.
6 Patent generation tasks
Patent text generation tasks aim to automatically create coherent and contextually relevant texts based on input prompts or requirements. As shown in Fig. 14, language generation is a sequence-to-sequence mapping of texts. The input and output are both word sequences, \(x=[w_1^i, w_2^i, \ldots, w_n^i]\) and \(y=[w_1^o, w_2^o, \ldots, w_m^o]\). There are four types of patent text generation tasks according to different objectives, including summarization (Sect. 6.1), translation (Sect. 6.2), simplification (Sect. 6.3), and patent writing (Sect. 6.4).

Illustration of text generation tasks
6.1 Summarization
6.1.1 Task definition of summarization
Patent summarization aims to create concise and informative summaries of patent documents. Given the complex and technical nature of patents, summarization helps in extracting the most important information and paraphrasing in more accessible language depending on the audience. The target audience may be as diverse as patent examiners, researchers, development engineers, the technophile public, and legal professionals. Additionally, summarization can extract the gist of patent subgroups within classification systems, which is essential for organizing and managing large patent datasets (Souza et al. 2021). The summarization process involves understanding and condensing the key aspects of a patent, such as claims, background, and detailed descriptions of the invention.
6.1.2 Methodologies for summarization
Extractive and abstractive summarization are two primary approaches for text summarization.
Extractive summarization. Extractive methods refer to selecting and extracting key phrases or sentences directly from the text of the patent. The goal is to retain the most significant and representative parts of the original document without altering the text. For instance, Souza et al. (2019) used different approaches, such as term-frequency–inverse-document-frequency (TF-IDF) and latent semantic analysis (LSA) (Deerwester et al. 1990), to choose the most representative sentence for each classification subgroupFootnote 19.
Compared to abstractive summarization, extractive methods are simpler to implement, as they do not require complex language generation capabilities. In addition, since the extracted sentences are taken verbatim, the original context, meaning, and particularly the wording of texts are well-preserved. However, this method may lack coherence, because extractive summaries can sometimes be disjointed. Moreover, it is hard to capture the essence of the text if the key information is not explicitly stated. In that sense, the summary can have the same limitations as the claims, which only contain the essence of the invention (in features) but are often poorly intelligible without the description as their dictionary.
Abstractive summarization. Abstractive summarization involves rephrasing original documents into shorter texts that retain essential information, a process demanding a deeper understanding of the text and the ability to generate coherent summaries. Researchers commonly use sequence-to-sequence models for this task, where the models receive original texts as inputs and produce summarized texts as outputs.
Trappey et al. (2020) trained a summarization model based on long short-term memory (LSTM), i.e., a sequential deep learning network, with attention mechanisms to extract essential knowledge from patent documents. Although promising, the performance was surpassed by the recently proposed transformer-based models. Concretely, fine-tuning transformer-based language models for summarization has shown remarkable performance in both general and patent domains (Zhang et al. 2020; Zaheer et al. 2020). Whereas the focus of most research has been on single patent summarization, Kim and Yoon (2022) introduced a method for multi-document summarization. The authors showed that their models enabled high-quality information summary for a large number of patent documents, which could be used to facilitate the activities of researchers and decision-makers.
Abstractive summarization can produce more concise, fluent, and cohesive summaries, by condensing and synthesizing information from multiple parts of the source text. Nonetheless, there is a higher risk of distorting facts, confusing meanings of terms that may deviate from everyday language on which the embedding of language models was trained, or misrepresenting the original text because of the involvement of paraphrasing and rewording. Additionally, abstractive summarization can be resource-intensive in terms of computational power and training data.
Table 5 compares representative models on the BigPatent benchmark (Sharma et al. 2019) for patent summarization. Transformer-based models outperform previous LSTM-based methods. In addition, models with long input lengths, such as LongT5 (Guo et al. 2022), significantly increase the performance, because patent descriptions usually contain more than 10,000 tokens (Suzgun et al. 2023).
LLMs have achieved satisfactory performance on most summarization tasks in the general domain, even surpassing the benchmark of reference summaries (Pu et al. 2023). The state-of-the-art method for text summarization is to use LLMs for abstractive summarization (Rao et al. 2024). However, how these LLMs, such as GPT-4, perform on patent summarization is still worth investigating. The technical content and legal information in patents may pose some challenges to LLMs compared to normal summarization.
6.2 Translation
6.2.1 Task definition of translation
Patent translation refers to the process of converting patent texts from one language to another, which is crucial in the global landscape of intellectual property. Translation can make patents accessible to individuals, companies, and researchers across different linguistic regions to foster cross-border innovation and cooperation. In addition, translation can ensure that patents comply with the legal requirements of different countries and obtain protection under the law.
Automated translation is maybe one of the earliest language-processing applications in the intellectual property domain and has become a highly established tool in the field already, which is used by patent offices routinely. Patent offices can leverage the large body of meticulously translated documents in many languages for model training. For instance, the European Patent Office (EPO) described their approach to identify parallel patent documents and sentences to generate training and evaluation datasets for patent translation (Wirth et al. 2023). The EPO offers machine translation on its free database interface, Espacenet. The engine in the back, called Patent Translate, was initially developed in 2012 in collaboration with Google. It started out with the most frequent six languages and has enhanced to now understand all of the office’s languages in addition to many others, such as Chinese, Japanese, and Korean. At a similar time, the World International Patent Office (WIPO) introduced a machine translation tool, WIPO Translate, which is integrated into their search engine Patentscope. It was reported to outperform standard machine translators for everyday texts, such as Microsoft Translate (Pouliquen 2015). Standard translators tend to vary terms and use synonyms in translations, which are acceptable or even desired in everyday language. However, the substitution is not acceptable and can render a patent worthless when it involves features or feature-relevant language. Therefore, in designing generative models, the tendency to introduce variations, often driven by the temperature in LLMs, must be carefully managed.
6.2.2 Methodologies for translation
Machine translation has been widely studied and gained significant progress in the general domain, such as statistical methods and neural machine translation (Wang et al. 2022). However, these models may not achieve strong performance in patent translation, because patents contain highly specialized technical jargon and precise terminology, challenging accurate translation. Therefore, researchers focused on the adaptation of general machine translation models to the patent domain.
Patent translation datasets. A feasible approach is to train the translation model on the above-mentioned multi-language patent data. For example, Heafield et al. (2022) proposed the EuroPat corpus, which includes patent-specific parallel data for official European languages: English, German, Spanish, French, Croatian, Norwegian, and Polish. In addition, the European Patent Office described their approach to identify parallel patent documents and sentences to generate training and evaluation datasets for patent translation (Wirth et al. 2023).
Fixing specific errors. Since accurate language is crucial in patent texts while language models are even designed to vary based on distance metrics of word meanings, for instance, research has studied pre- and post-processing methods for fixing common problems. As an example for terminology errors, Ying et al. (2021) identified eight types of terminology errors in patent translation from English into Chinese and suggested solving these errors by pre-editing the source texts. In addition, Larroyed (2023) compared ChatGPT (Ray 2023) and the Patent Translate system of the European Patent Office on patent translation. In their analysis, Patent Translate could exploit its training on patent corpora and specialization in patent translation to outperform ChatGPT in accuracy. ChatGPT, however, performed better on language structure and overall textual coherence. In linguistics, these two qualities might refer to paradigmatic versus syntagmatic properties. Such results suggest that a combination of both advantages may open new opportunities. One part of the solution may be on the model side, where transformers or a combination of recurrent neural networks (RNNs) and transformers may improve structural, i.e., syntagmatic shortcomings. Further deriving a domain-specific model through training and/or fine-tuning to patent corpora promises to enhance both syntagmatic and paradigmatic performance through the incorporation of more patent-typical language structures as well as sharper control over terminology-related issues.
Although translation systems, such as Patent Translate, offer valuable tools for understanding patent documents in various languages, it is important to recognize that machine translations may not always achieve the precision required for legal or formal purposes. Therefore, for critical applications such as patent filings or legal proceedings, consultation with professional human translators is advisable to ensure the highest level of accuracy. From the above studies, we can conclude that training specific LLMs on extensive patent translation datasets is highly promising to further improve translation accuracy and language precision.
6.3 Simplification
6.3.1 Task definition of simplification
Patent simplification refers to the process of translating complex and technical patent documents into more straightforward readable language. The difficulty of patent texts is often two-fold: First, the content is supposed to be at the forefront of science and technology and/or refer to particular details that require an exceptionally good understanding of the context. Second, the language that describes the invention focuses on precision, accuracy, and sometimes intentional flexibility to avoid unnecessary reduction of the scope instead of readability. This precision typically leads to high repetitiveness in both terminology and structure of sentences, paragraphs, and sections. Especially, sentences are often overburdened with specifications for precision (typically relative or adverbial clauses) or examples and alternatives for a wide enough scope.
Different from patent summarization, all information should ideally be retained in simplified texts in the task of patent simplification. The aim is to improve readability and make patent texts more accessible to a wider audience, such as technical experts without an interest in legal language. Simplification can involve multiple aspects, such as summarizing key concepts, removing jargon, and rephrasing technical terms in layman’s terms.
6.3.2 Methodologies for simplification
Formatting. Original documents undergo formatting to enhance accessibility without modifying the texts. Patent offices, for instance, often structure claims in their interfaces. On the macro level, the dependency on claims can be automatically derived from the claims (e.g., Invention of one of the previous claims, wherein...) to form a tree structure of claims. An example claim tree is shown in Fig. 15. Within a claim, the individual features can be separated so that a graphical representation can indicate which features get added by each claim. The independent claims may further have a two-part structure (e.g., European Patent Regulations Rule 43, PCT Regulations Rule 6.3, US 37 CFR 1.75(e)) where the first part (preamble) lists the features of the prior art and the second part (typically introduced with an adverb as whereby, a participle as comprising or characterized by, or a relative pronoun) refines it with further features (characterizing portion).

a Claim tree of EP 2 346 553 (specifically version A1 of it, i.e., the not granted (therefore A and not B, C or similar) first (accordingly counter 1) filing of the applicant), which can be generated from the text based on the logical relationship between the 20 claims. b Claim 1 of patent EP 2 346 553 B1. Each claim can further be split into features, e.g., all elements that a device collectively has to contain to be considered an embodiment of the invention
While the European Patent Office uses explicit references in the text to other claims to generate claim trees, such as according to claim 1, Andersson et al. (2013) developed a dependency claim graph to exploit implicit references by detecting discourse references. The authors defined rules to extract and use linguistic information to build the tree, including part-of-speech, phrase boundaries, and discourse theory. The claim tree simplified the connection and relation between complex claims to improve patent accessibility. In addition, Sheremetyeva (2014) designed two levels of visualization of patent documents. The macro-level simplification involved the development of claim trees based on pre-defined rules. Meanwhile, micro-level simplification used both rule-based and statistical techniques that rely on linguistic knowledge. The authors highlighted nominal terms with the reference in patent description, aiming to improve readability by providing terminology at a glance. They also segmented complex claims into simple sentences to increase accessibility. This hierarchy visualization system effectively increases the overall productivity in processing patent documents.
To simplify patent claim texts, Ferraro et al. (2014) proposed some rules to segment the original claims into three components, consisting of the preamble, transitional phrase, and body. Although the clearer presentation of patent claims improved the readability and accessibility, the original complicated texts were not modified. Thus, it could still be challenging to read and understand the technical documents.
Paraphrasing. Paraphrasing refers to rewriting the original complex sentences into simpler versions with the text meaning unchanged. Kang et al. (2018) proposed a simplification system based on the analysis of patent syntactic and lexical patterns. This simplification system could detect complex sentences and simplify those sentences through splitting, dropping, and modifying. Paraphrasing can break down complex concepts into simpler language to be accessible to a broader audience. Nonetheless, paraphrasing may lose subtle nuances and specific terminologies, which are crucial in some contexts.
Additionally, some studies focused on sequence-to-sequence models for text simplification in the general domain. For example, Martin et al. (2020) proposed to use explicit control tokens for attributes, such as length, lexical complexity, and syntactic complexity, to tailor simplifications for the needs of different audiences. However, these models were rarely used for patent simplification because of the lack of in-domain datasets. Casola et al. (2023) aimed to break the boundary by proposing data generation methods for patent simplification. The authors used a Pegasus-based—a transformer model for abstractive summarization (Zhang et al. 2020)—paraphraser trained on general-domain datasets in a zero-shot fashion to obtain simplification candidates from complex patent sentences. Subsequently, the authors discussed filtering to select appropriate candidate patent documents for simplification only and obtained the first large-scale dataset for patent sentence simplification.
In contrast to well-established tasks of patent summarization and translation, patent simplification is less investigated and worth more attention. Particularly, established benchmarks to compare different models and approaches are important to accelerate the development of this topic. LLMs appear an ideal tool for this task, despite the challenges of processing complex technical documents with legal requirements.
6.4 Patent writing
6.4.1 Task definition of patent writing
Patent writing refers to the automated creation of patent texts, including various sections such as abstracts, claims, and descriptions. The primary goal of patent text generation is to assist inventors, patent agents, and attorneys in drafting patent applications more efficiently and effectively. Text generation is a difficult task, especially in the patent domain due to the linguistic, technical, and legal complexities. These facts pose significant challenges for language models to handle complex legal jargon and terminology while ensuring accuracy and adherence to technical norms.
6.4.2 Methodologies for patent writing
A few studies have investigated patent writing for different sections based on fine-tuning LLMs (Table 6). Lee and Hsiang (2020a) provided an initial proof-of-concept study for patent claim generation. The authors fine-tuned the GPT-2 model to generate patent claims, but the quality of generated claims was not measured, which reduced the actual value of the work. In further research, Lee (2020) trained the GPT-2 model to map one section to another, such as generating abstracts based on title and generating claims from abstracts. Nonetheless, patent professionals may raise concerns about the validity of the tasks. Patent titles only include a few words and lack specificity, which makes title-based generation unfounded. In contrast, abstract-based claim generation sometimes makes sense because the abstract in some patents is just a paraphrased version of the first independent claim (without the legal phraseology). Hence, this task is straightforward by extracting and revising the abstract. However, abstracts are typically crafted to be general and reveal minimal details of the invention, while still adhering to requirements of patent offices (European Patent Office 2000; World Intellectual Property Organization 2022). Consequently, it is almost impossible to generate detailed invention features required by claims based solely on general and vain abstracts. Therefore, both title-based and abstract-based generation tasks are not well-conditioned. Alternatively, patent descriptions include all details and specific embodiments of the invention, which makes description-based patent generation notably promising for future research. Recent research constructed a dataset with 9,500 examples and evaluated the performance of various LLMs in patent claim generation. The results demonstrated that description-based claim generation outperformed previous research, which relied on abstracts (Jiang et al. 2024). Moreover, fine-tuning can enhance the claims’ completeness, conceptual clarity, and logical linkage. GPT-4 achieved the best performance among all tested LLMs and uniquely grouped alternative embodiments within dependent claims logically. Despite promising capabilities, comprehensive revisions are still necessary for LLM-generated claims to pass rigorous patent scrutiny. Follow-up work further explored the ability of LLMs to revise patent claims. The findings indicate that LLMs often introduce ineffective edits that deviate from the intended revisions, whereas fine-tuning can improve performance (Jiang et al. 2024). Conversely, Wang et al. (2024) appear to be the first to investigate the generation of patent specifications from claim and drawing texts. They fine-tuned GPT-J (Wang 2021) and T-5 (Raffel et al. 2020) and demonstrated their ability to produce human-like patent specifications that adhere to a legal writing style. However, their approach still relies on certain simplifying assumptions that deviate from real-world patent drafting practices, such as the assumption that each specification paragraph corresponds to only one claim feature and a single drawing. While their work lays a solid foundation for specification generation, significant challenges remain before achieving practical applicability.
In addition, Christofidellis et al. (2022) proposed a prompt-based generative transformer for the patent domain, which used GPT-2 as backbone and trained with multi-task learning (Maurer et al. 2016) on part-of-patent generation, text infilling, and patent coherence evaluation tasks. Specifically, the training processes involved two text generation tasks, generating patent titles based on abstracts and suggesting words for masked tokens in the given abstracts. The performance was better than the baseline, specifically BERT and GPT-2 on a single task. This paper indicates that multi-task learning may be a promising method for patent text generation in the future. A recent report focused on the drafting of patent sections from academic papers, such as background, summary, and description (Knappich et al. 2024). The authors highlighted the potential of LLMs in patent drafting and revealed the main challenges, including handling content repetition, retrieving contextually relevant data, and adapting the system for longer documents.
Recent studies have explored the application of LLM-based agents in various aspects of patent drafting, analysis, and management. An agent in this context refers to an autonomous system that leverages LLMs to perform specialized tasks, often in a structured, multi-agent framework where different agents collaborate to achieve complex objectives. For example, Wang et al. (2024) proposed EvoPat, a multi-LLM-based agent designed for patent summarization and analysis. Wang et al. (2024) introduced AutoPatent, a multi-agent framework comprising an LLM-based planner agent, writer agents, and an examiner agent, which work together for patent application drafting. Additionally, Chu et al. (2024) presented an LLM-based recommender system specifically designed to assist with patent office action responses. PatExpert (Srinivas et al. 2024) in turn suggested a meta-agent that orchestrates task-specific expert agents for various patent-related tasks, such as classification, claim generation, and summarization. It also includes a critique agent for error handling and feedback provision to enhance adaptability and reliability.
While LLMs have shown outstanding performance on generation tasks, their application in the patent domain is under-explored. Future work needs comprehensive evaluations of LLMs on patent generation tasks. The highly specialized and technical nature of patent texts may pose significant challenges for applying general LLMs to patent tasks.
7 Future research directions
7.1 Data and benchmarks
Machine-learning models for the patent field, particularly LLMs, require extensive pre-structured and pre-processed high-quality data for training, testing, and knowledge extraction. Although patent databases contain vast amounts of raw data accumulated over the years, there is a lack of labeled patent datasets for different tasks. We summarize existing curated patent data collections in Sect. 4.2 and demonstrate that the number of publicly accessible datasets for some tasks is limited, such as patent novelty prediction and patent text simplification. To stimulate the development of better methods, patent offices might consider providing more of their internal pre-processed databases.
Additionally, benchmarks consist of labeled datasets and established metrics for performance evaluation, such as accuracy and precision. These benchmarks serve as a foundational framework that ensures researchers can assess the strengths and limitations of their methods against a standardized set of conditions to promote transparency and fairness in comparison. In the context of the patent domain, many tasks have relied on closed-source datasets, which limits the ability of other researchers to replicate and validate findings. Moreover, general text evaluation metrics may not be suitable for patent text assessment (Jiang et al. 2024). The absence of well-defined benchmarks for these tasks renders it challenging to assess and compare the effectiveness of various models fairly and comprehensively.
7.2 Use of large language models
Since texts are the key ingredient to patent documents, promising methods to analyze and generate patent texts are worth investigating. Large language models have dramatically changed the field and achieved remarkable performance in a wide range of tasks in the general domain (Min et al. 2023), such as information retrieval, translation, and summarization. However, few works have evaluated and investigated the usage of LLMs on patent-related tasks, which leaves a large research gap. Patents include a distinct category of text, characterized by their formal language, dense technical content, and legal implications. The exploitation of LLMs to handle the intricacies of patent texts could yield considerable benefits in understanding and managing intellectual property. LLMs could identify more intricate and nuanced patterns and relationships within patent texts to improve the effectiveness in patent analysis tasks, such as patent classification and novelty prediction. Furthermore, LLMs could assist in generating and refining patent texts based on a comprehensive understanding of existing patent literature. For example, LLMs could assist inventors and patent attorneys in drafting initial claims, expanding descriptions, or adapting texts to align with jurisdictional requirements. The integration of LLMs into patent tasks cannot only enhance the efficiency and effectiveness of patent analysis but also improve the quality of the patent drafting process. As these models continue to evolve, LLMs appear significantly promising in the patent domain.
7.3 Long sequence modeling
Most patent analysis tasks are based on short texts, such as titles, claims, and abstracts but ignore the patent description. One of the potential reasons is that the average length of patent descriptions far exceeds the context length of many transformer models. It is difficult to deal with such long-range dependencies and context retention. Whereas patent titles and abstracts are usually generic and vain, patent descriptions have to provide details of the invention and disclose the invention in all aspects. Hence, integrating detailed descriptions for patent analysis tasks may significantly improve performance. Therefore, a closer investigation of long-sequence modeling approaches appears to lead to a promising tool for patent descriptions. It is worth noting that the latest LLMs can support longer inputs with currently more than 100,000 tokens context length as the benchmark. As discussed in Sect. 3, latest LLMs would unlock the potential of including the patent description part.
7.4 Patent text generation
Patent text generation tasks are much less investigated, probably due to the complexity and difficulty. Automated patent-text generation poses several challenges because of its highly specialized and technical nature. Firstly, patent documents require a specific style of language and use of terminology. Secondly, the language must be formal, unambiguous, and follow legal requirements to be granted. Thirdly, the language of the description and the claims must be precise, accurate, and clear. Lack of language precision, accuracy, and clarity hampers examination, risks a small scope and may provide leverage for litigation.
Although deep-learning models, especially large language models, have demonstrated previously unexpected performance in text generation in the general domain, patent text generation methods are still scarce. The development and refinement of patent text generation models are not only helpful to the patent application process but also advantageous to research in natural language processing and related domains, such as law and technology.
Furthermore, we see an important research need for evaluation metrics for patent texts. We included common text evaluation methods in Appendix B.3. However, patent texts have specific language requirements. Hence, previous evaluation metrics may not be appropriate for patent text assessment.
7.5 Multimodal methods
Apart from text, patent documents themselves and their context include other useful information, such as drawings and citations. Multimodal models can combine multiple data types to improve the performance of patent analysis (Huang et al. 2024). Research explores model architectures such as CLIP (Radford et al. 2021) and Vision Transformers (Dosovitskiy 2020) to bridge the gap between textual descriptions and visual data to enhance patent processing. Given the only recently increased performance gains in general multimodal methods, there are only few studies for patent applications yet, for example in patent classification (Jiang et al. 2022) and patent image retrieval (Pustu-Iren et al. 2021). Ideally, researchers can adopt multimodal methods in other patent tasks as well. For example, multimodal models can assist in patent drafting from design figures to ensure the textual descriptions and figures are aligned. Furthermore, multimodal methods can create more informative and intuitive visualizations of patent data to provide a clearer understanding of the patent landscape. A multimodal approach appears promising and deserves more attention.
8 Conclusion
Patent documents are different from mundane texts in various aspects. They must be precise to ensure the patent is grantable, defensible, and enforceable. The topic, on the other hand, refers to intricate technical aspects. The requirement for precision in combination with technical complexity has led to a highly artificial language. Reading and correct interpretation of those texts require a high level of concentration, specific patent training, and experience. Whereas patent tasks are highly manual and the knowledge contained in the patent literature is widely unused, NLP appears as an ideal solution. It can deal with complicated structures and learn definitions (terms) that deviate from every-day language or even the vocabulary of experts in the specific field.
As NLP techniques critically rely on high-quality training data, we collected patent data sources and databases, with curated datasets specifically designed for different patent tasks. Although patent offices have provided raw patent documents for years, publicly accessible curated datasets for specific tasks are limited. Offices only offer manual reading of individual documents, instead of pre-processed data or large-scale access to well-structured legal process documents of the file (register). The field needs high-quality data for training to optimize the model performance. In addition, the proposal of novel patent tasks should suggest open-sourced datasets and benchmarks for future research.
NLP techniques play a prominent role in the automation of patent processing tasks. Text embeddings can extract word and semantic information for patent analysis. Sentence/paragraph embeddings appear preferable to word embeddings because they can capture more nuanced contextual information from entire sentences or paragraphs. From the model perspective, most traditional machine-learning models, such as feature-based neural networks, support vector machines, or random forests, may already be outdated. Deep learning models, particularly convolutional and recurrent neural networks, are still used in some circumstances, for example when the computing power is limited. However, larger transformer-based models, such as the BERT and the GPT series, have almost revolutionized the field despite their excessive need for computational resources. Furthermore, scaling the model size to LLMs has led to an explosion in performance on numerous general tasks.
Research has prominently focused on short text parts of patents, such as titles and abstracts, e.g., for patent analysis or generation tasks. However, these texts are the least specific texts with little information about the actual invention. Since they are highly generic and take little time during drafting, the automation of these short texts is not necessarily helpful. Among the shorter parts of patents, the claims would be an exception as they define the legal scope of patent protection. The tasks of claim generation, description generation, and LLM-based patent agents are worth investigating.
The most studied and developed topics are automated patent classification and retrieval, which are routine tasks in patent offices. Transformer-based language models have shown better effectiveness in leveraging text information compared to traditional machine learning models and deep word embeddings. A more promising direction is to hybridize methods so that they can use multiple sources from patents, including texts, images, and metadata. Information extraction serves as a primer to support various patent-related applications. State-of-the-art language models can help in precise extraction to improve the performance in further applications. Furthermore, we found that the conception of novelty used in research can substantially deviate from its strict definition in patent law. Accordingly, a share of the studies may aim at predicting the patent novelty but actually generate some form of metric for oddness, potential creativity, or perceived originality. Such cases indicate the often underestimated difficulties when working with patents. Interestingly, practically no capable foundation models can deal with the particularities of the patent domain and simplify the derivation of usable tools for specific tasks. Granting prediction, litigation prediction, and patent valuation are comparably less investigated. The key acts in patent examination are almost ignored so far, including the automated formal novelty and inventiveness detection for higher quality and objectivity, deriving of arguments, and support in formulating motions.
The exploitation of the knowledge base in the patent literature appears more developed. Technology forecasting and innovation recommendation are pattern search tasks that do not necessarily need recent language processing techniques but can already produce reasonable output with older text-parsing techniques in combination with conventional statistics and machine-learning methods. Large language models would cause an overwhelming computational burden if they had to process such large bodies of text. Thus, these fields depend more on good problem definitions and mapping to conventional pattern-identification tasks than on the latest developments of machine-learning techniques.
Latest language models play a role in generative tasks around patents and reflect the most recent trend towards generative artificial intelligence. Apart from patent analysis, the language particularities of patents also complicate generative tasks. Summarization and automated translation tasks are well-established and available online. Particularly, automated translation has been studied and in production at patent offices for more than a decade. Less conspicuous yet socially beneficial tasks, such as patent simplification, receive scant attention in research. This oversight is primarily attributed to the absence of appropriate datasets. Although patent drafting, especially the sections on descriptions and claims, is an obvious task, the available research is limited and generally unsatisfactory.
The primary obstacles to more effective techniques are twofold. First, there is a need for better access and classification of data for training and analysis. Patent laws in most countries mandate the publication of patent applications. Historically, this was considered a contract between inventors and society which offered inventors a limited monopoly in exchange for disclosing their inventions in sufficient detail to stimulate progress. However, the current mode of publication presents PDF documents with text extraction and related registry documents that are rudimentarily classified, often accompanied by poor-quality scans, with restrictions on automated processing. The necessary information would be available in these offices, though. Second, the field would greatly benefit from foundational models capable of handling the high degree of formality in patent language, where challenges are most prominently observed.
Data availability
No datasets were generated or analysed during the current study.
Notes
Amendments must not introduce novel features, i.e., inventive content, to avoid losing the original date stamp or the entire file.
Such additional material should not be added casually but would require proper announcement with a new filing that typically claims the priority of the base filing for all aspects already described in the latter. Otherwise, the inadmissibly extended file may be rejected or later challenged in the granted stage.
It is worth mentioning that the high importance of legal and formal aspects can tip the balance away from the sciences. Prophetic examples or experiments in patent documents describe expected results or theoretical experiments that have not been physically conducted. These are hypothetical scenarios intended to demonstrate the scope of an invention or to anticipate and complicate any competing patent filing for competitors with wild speculation. While many offices only require a basic feasibility of the invention per the claims, such documents can receive incorrect citations and let these prophecies or speculations appear as factual, which can lead to misinformation (Freilich 2019).
This aspect may reflect an important discussion to be led by the field and society. As in other domains, there may be a missing or unclear consensus on which data can be used for machine learning. In stark contrast to other domains, where even books and copyrighted materials may be processed in large numbers, sometimes to create new works that compete with the originals, the patent system is a bit different. The entire modern patent system was developed and is justified as a social contract, trading invention disclosure for temporary exclusion from competition. The descriptions are often public domain and related correspondence with patent offices is made public to ensure transparency. Thus, imposing paywalls would typically violate the mission of patent offices. Admittedly, big-data methods and artificial intelligence were not considerations during the establishment of these legal frameworks. Patent offices may still restrict or complicate larger-scale data access to parts or all contents to avoid commercial exploitation. Some patent offices offer costly paid database access as a stream of revenue, which can be prohibitively expensive for academic research. Important context to know is that in many places patent offices need to fund their own operating expenses or even earn a profit (United States Patent and Trademark Office 2023; President of the European Patent Office and Administrative Council of the European Patent Organisation 2021; van Pottelsberghe de la Potterie and François 2009; Frakes and Wasserman 2014). Therefore, society—which the patent offices are ultimately meant to serve—must reach a consensus on how to manage data access for commercial versus academic purposes, which potentially lead to both proprietary and open-source models.
TREC-CHEM: https://trec.nist.gov/data/chem-ir.html
Whereas most research retrieved patent documents as outputs, prior art can also be other types of published (oral or visual) information.
See Articles 54 and 56 of the European Patent Convention (EPC), Sections 2 and 3 of the UK Consolidated Patent Act, or §102 and §103 of the United States patent law codified in Title 35 Code of Laws (USC) as examples.
They collectively refer to the prior art or state of the art.
While researchers consider this task as a binary classification task, it may also be useful to assess the level of novelty of an invention.
A patent is typically terminally rejected if the inventors or their representatives cannot find any more features to establish novelty and inventiveness. Practically any good patent application is rejected in the first cycle. If a patent application is not rejected but granted based on the first draft of the claims, the patent attorneys—except for a few rare cases—should potentially contemplate if they did not potentially phrase the independent claims too restrictively so that they lost scope by not first testing a more general claim version.
Strategically, most defendants immediately trigger cross action going after the validity of the respective rights when they receive an infringement indictment and the case is not rock solid.
Strictly speaking, the use of AI to generate inventions may raise legal issues, notably around inventorship and ownership. The use of AI for writing a patent could do so if the AI starts to add information or hallucinate so that it could be considered inventive, not considering copyright and authorship rights. Traditionally, patents are granted to human inventors, i.e., natural persons. The US Patent and Trademark Office, at present, does not consider AI-generated inventions as patentable, which limits how technology gap detection and idea generation can be used to create patentable inventions. Practically, natural co-inventors might suppress the co-inventorship of an AI until technical means are available to detect AI contributions. No precedence seems available if that would collide with the inventors’ oath filed with the application or would set an inventor into bad faith. These issues highlight the need for evolving legal standards to accommodate the rapid advancements of AI technology in the patent system.
Patent sub-groups are the most specific level in the patent classification hierarchy, see Sect. 5.1.2
Important background information: in most patent offices, the drawings are not supposed to contain text beyond reference numbers.
References
Abbas A, Zhang L, Khan SU (2014) A literature review on the state-of-the-art in patent analysis. World Patent Inf 37:3–13
Abdelgawad L, Kluegl P, Genc E, Falkner S, Hutter F (2019) Optimizing neural networks for patent classification. In: Joint European conference on machine learning and knowledge discovery in databases. Springer, pp. 688–703
Abood A, Feltenberger D (2018) Automated patent landscaping. Artif Intell Law 26(2):103–125
Albert MB, Avery D, Narin F, McAllister P (1991) Direct validation of citation counts as indicators of industrially important patents. Res Policy 20(3):251–259
Ali A, Tufail A, De Silva LC, Abas PE (2024) Innovating patent retrieval: a comprehensive review of techniques, trends, and challenges in prior art searches. Appl Syst Innov 7(5):91
Almazrouei E, Alobeidli H, Alshamsi A, Cappelli A, Cojocaru R, Alhammadi M, Daniele M, Heslow D, Launay J, Malartic Q, Noune B, Pannier B, Penedo G (2023) The falcon series of language models: towards open frontier models
Althammer S, Hofstätter S, Hanbury A (2021) Cross-domain retrieval in the legal and patent domains: a reproducibility study. In: Advances in information retrieval: 43rd European conference on IR research, ECIR 2021, Virtual Event, March 28–April 1, 2021, Proceedings, Part II 43. Springer, pp. 3–17
Andersson L, Lupu M, Hanbury A (2013) Domain adaptation of general natural language processing tools for a patent claim visualization system. In: Multidisciplinary information retrieval: 6th information retrieval facility conference, IRFC 2013, Limassol, Cyprus, October 7-9, 2013. Proceedings 6. Springer, pp. 70–82
Anthropic: The claude 3 model family: Opus, sonnet, haiku. Preprint (2024)
Aristodemou L, Tietze F (2018) The state-of-the-art on intellectual property analytics (ipa): a literature review on artificial intelligence, machine learning and deep learning methods for analysing intellectual property (ip) data. World Patent Inf 55:37–51
Arts S, Hou J, Gomez JC (2021) Natural language processing to identify the creation and impact of new technologies in patent text: code, data, and new measures. Res Policy 50(2):104144
Aubakirova D, Gerdes K, Liu L (2023) Patfig: Generating short and long captions for patent figures. In: Proceedings of the IEEE/CVF international conference on computer vision, pp. 2843–2849
Baeza-Yates R, Ribeiro-Neto B et al (1999) Modern information retrieval 463:1999
Bai Z, Zhang R, Chen L, Cai Q, Zhong Y, Fang CWY, Fang J, Sun J, Wang W, Zhou L, et al (2024) Patentgpt: a large language model for intellectual property. arXiv:2404.18255
Balsmeier B, Assaf M, Chesebro T, Fierro G, Johnson K, Johnson S, Li G-C, Lück S, O’Reagan D, Yeh B et al (2018) Machine learning and natural language processing on the patent corpus: data, tools, and new measures. J Econ Manag Strat 27(3):535–553
Banerjee S, Lavie A (2005) Meteor: an automatic metric for mt evaluation with improved correlation with human judgments. In: Proceedings of the Acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, pp. 65–72
Beaty RE, Johnson DR (2021) Automating creativity assessment with semdis: an open platform for computing semantic distance. Behav Res Methods 53(2):757–780
Bekamiri H, Hain DS, Jurowetzki R (2021) Patentsberta: A deep nlp based hybrid model for patent distance and classification using augmented sbert. arXiv:2103.11933
Beltagy I, Peters ME, Cohan A (2020) Longformer: the long-document transformer. arXiv:2004.05150
Breunig MM, Kriegel H-P, Ng RT, Sander J (2000) Lof: identifying density-based local outliers. In: Proceedings of the 2000 ACM SIGMOD international conference on management of data, pp. 93–104
Campbell W, Li L, Dagli C, Greenfield K, Wolf E, Campbell J (2016) Predicting and analyzing factors in patent litigation. In: NIPS2016, ML and the law workshop
Casola S, Lavelli A (2022) Summarization, simplification, and generation: the case of patents. Expert Syst Appl 205:117627
Casola S, Lavelli A, Saggion H (2023) Creating a silver standard for patent simplification. In: Proceedings of the 46th international acm sIGIR conference on research and development in information retrieval, pp. 1045–1055
Chen H, Deng W (2023) Interpretable patent recommendation with knowledge graph and deep learning. Sci Rep 13(1):2586
Chen L, Xu S, Zhu L, Zhang J, Lei X, Yang G (2020) A deep learning based method for extracting semantic information from patent documents. Scientometrics 125:289–312
Chen G, Li X, Meng Z, Liang S, Bing L (2023) Clex: continuous length extrapolation for large language models. In: The twelfth international conference on learning representations
Chen X, Yu G, Wang J, Domeniconi C, Li Z, Zhang X (2019) Activehne: active heterogeneous network embedding. In: Proceedings of the 28th international joint conference on artificial intelligence, pp. 2123–2129
Chiarello F, Cirri I, Melluso N, Fantoni G, Bonaccorsi A, Pavanello T (2019) Approaches to automatically extract affordances from patents. In: Proceedings of the design society: international conference on engineering design. Cambridge University Press, vol. 1, pp. 2487–2496
Chikkamath R, Endres M, Bayyapu L, Hewel C (2020) An empirical study on patent novelty detection: a novel approach using machine learning and natural language processing. In: 2020 Seventh international conference on social networks analysis, management and security (SNAMS). IEEE, pp. 1–7
Choi S, Lee H, Park E, Choi S (2022) Deep learning for patent landscaping using transformer and graph embedding. Technol Forecast Soc Chang 175:121413
Christofidellis D, Lehmann MM, Luksch T, Stenta M, Manica M (2023) Automated patent classification for crop protection via domain adaptation. Appl AI Lett 4(1):80
Christofidellis D, Torres AB, Dave A, Roveri M, Schmidt K, Swaminathan S, Vandierendonck H, Zubarev D, Manica M (2022) Pgt: a prompt based generative transformer for the patent domain. In: ICML 2022 workshop on knowledge retrieval and language models
Chu J-M, Lo H-C, Hsiang J, Cho C-C (2024) From paris to le-paris: toward patent response automation with recommender systems and collaborative large language models. Artif Intell Law. https://doi.org/10.1007/s10506-024-09409-7
Chung P, Sohn SY (2020) Early detection of valuable patents using a deep learning model: case of semiconductor industry. Technol Forecast Soc Chang 158:120146
Chung J, Gulcehre C, Cho K, Bengio Y (2014) Empirical evaluation of gated recurrent neural networks on sequence modeling. In: NIPS 2014 workshop on deep learning
Colombo P, Pires TP, Boudiaf M, Culver D, Melo R, Corro C, Martins AF, Esposito F, Raposo VL, Morgado S, et al. (2024) Saullm-7b: A pioneering large language model for law. arXiv:2403.03883
Deerwester S, Dumais ST, Furnas GW, Landauer TK, Harshman R (1990) Indexing by latent semantic analysis. J Am Soc Inf Sci 41(6):391–407
Deng W, Ma J (2021) A knowledge graph approach for recommending patents to companies. Electron Comm Res 22:1–32
Devlin J, Chang M-W, Lee K, Toutanova K (2018) Bert: pre-training of deep bidirectional transformers for language understanding. arXiv:1810.04805
Dhondt E, Verberne S, Koster C, Boves L (2013) Text representations for patent classification. Comput Linguist 39(3):755–775
Dosovitskiy A (2020) An image is worth 16x16 words: transformers for image recognition at scale. arXiv:2010.11929
Du W, Wang Y, Xu W, Ma J (2021) A personalized recommendation system for high-quality patent trading by leveraging hybrid patent analysis. Scientometrics 126:9369–9391
Dubey A, Jauhri A, Pandey A, Kadian A, Al-Dahle A, Letman A, Mathur A, Schelten A, Yang A, Fan A, et al (2024) The llama 3 herd of models. arXiv:2407.21783
Dunn A, Dagdelen J, Walker N, Lee S, Rosen AS, Ceder G, Persson K, Jain A Structured information extraction from complex scientific text with fine-tuned large language models. arXiv:2212.05238 (2022)
European Patent Office: EPC - The European Patent Convention. https://www.epo.org/en/legal/epc/2020/regulations.html. Accessed: 2023-06-12 (2000)
Fall CJ, Törcsvári A, Benzineb K, Karetka G (2003) Automated categorization in the international patent classification. Acm Sigir Forum 37:10–25
Ferraro G, Suominen H, Nualart J (2014) Segmentation of patent claims for improving their readability. In: Proceedings of the 3rd workshop on predicting and improving text readability for target reader populations (PITR), pp. 66–73
Frakes MD, Wasserman MF (2014) The failed promise of user fees: Empirical evidence from the us patent and trademark office. J Empir Leg Stud 11(4):602–636
Freilich J (2019) Prophetic patents. UC Davis L. Rev. 53:663
Freunek M, Bodmer A (2021) Bert based freedom to operate patent analysis. arXiv:2105.00817
Frumkin M (1947) Early history of patents for innovation. Trans Newcomen Soc 26(1):47–56
Giordano V, Puccetti G, Chiarello F, Pavanello T, Gualtiero F: Unveiling the inventive process from patents by extracting problems, solutions and advantages with natural language processing. Solut Adv Natl Lang Process (2022)
Goel A, Gueta A, Gilon O, Liu C, Erell S, Nguyen LH, Hao X, Jaber B, Reddy S, Kartha R, et al.: (2023) Llms accelerate annotation for medical information extraction. In: Machine learning for health (ML4H). PMLR, pp. 82–100
Guo M, Ainslie J, Uthus DC, Ontanon S, Ni J, Sung Y-H, Yang Y (2022) Longt5: efficient text-to-text transformer for long sequences. In: Findings of the association for computational linguistics: NAACL 2022, pp. 724–736
Haghighian Roudsari A, Afshar J, Lee W, Lee S (2022) Patentnet: multi-label classification of patent documents using deep learning based language understanding. Scientometrics 127:1–25
Hain DS, Jurowetzki R, Buchmann T, Wolf P (2022) A text-embedding-based approach to measuring patent-to-patent technological similarity. Technol Forecast Soc Chang 177:121559
Harhoff D, Narin F, Scherer FM, Vopel K (1999) Citation frequency and the value of patented inventions. Rev Econ Stat 81(3):511–515
Heafield K, Farrow E, Linde J, Ramírez-Sánchez G, Wiggins D (2022) The Europat corpus: a parallel corpus of european patent data. In: Proceedings of the thirteenth language resources and evaluation conference, pp. 732–740
Helmers L, Horn F, Biegler F, Oppermann T, Müller K-R (2019) Automating the search for a patent’s prior art with a full text similarity search. PLoS ONE 14(3):0212103
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778
Higuchi K, Yanai K (2023) Patent image retrieval using transformer-based deep metric learning. World Patent Inf 74:102217
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735–1780
Hofstätter S, Rekabsaz N, Lupu M, Eickhoff C, Hanbury A (2019) Enriching word embeddings for patent retrieval with global context. In: Advances in information retrieval: 41st European conference on IR research, ECIR 2019, Cologne, Germany, April 14–18, 2019, Proceedings, Part I 41. Springer, pp. 810–818
Hu J, Li S, Hu J, Yang G (2018) A hierarchical feature extraction model for multi-label mechanical patent classification. Sustainability 10(1):219
Hu Z, Zhou X, Lin A (2023) Evaluation and identification of potential high-value patents in the field of integrated circuits using a multidimensional patent indicators pre-screening strategy and machine learning approaches. J Informet 17(2):101406
Huang D, Yan C, Li Q, Peng X (2024) From large language models to large multimodal models: a literature review. Appl Sci 14(12):5068
Huang J, Ping W, Xu P, Shoeybi M, Chang KC-C, Catanzaro B (2023) Raven: in-context learning with retrieval augmented encoder-decoder language models. arXiv:2308.07922
Izacard G, Lewis P, Lomeli M, Hosseini L, Petroni F, Schick T, Dwivedi-Yu J, Joulin A, Riedel S, Grave E (2023) Atlas: Few-shot learning with retrieval augmented language models. J Mach Learn Res 24(251):1–43
Jang H, Kim S, Yoon B (2023) An explainable ai (xai) model for text-based patent novelty analysis. Expert Syst Appl 231:120839
Jeon D, Ahn JM, Kim J, Lee C (2022) A doc2vec and local outlier factor approach to measuring the novelty of patents. Technol Forecast Soc Chang 174:121294
Jiang AQ, Sablayrolles A, Mensch A, Bamford C, Chaplot DS, Casas Ddl, Bressand F, Lengyel G, Lample G, Saulnier L, et al (2023) Mistral 7b. arXiv:2310.06825
Jiang AQ. Sablayrolles A, Roux A, Mensch A, Savary B, Bamford C, Chaplot DS, Casas Ddl, Hanna EB, Bressand F, et al (2024) Mixtral of experts. arXiv:2401.04088
Jiang S, Luo J, Ruiz-Pava G, Hu J, Magee CL (2021) Deriving design feature vectors for patent images using convolutional neural networks. J Mech Des 143(6):061405
Jiang S, Sarica S, Song B, Hu J, Luo J (2022) Patent data for engineering design: a critical review and future directions. J Comput Inf Sci Eng 22(6):060902
Jiang H, Fan S, Zhang N, Zhu B (2023) Deep learning for predicting patent application outcome: the fusion of text and network embeddings. J Inf 17(2):101402
Jiang P, Atherton M, Sorce S (2023) Extraction and linking of motivation, specification and structure of inventions for early design use. J Eng Design, 1–26
Jiang S, Hu J, Magee CL, Luo J(2022) Deep learning for technical document classification. IEEE Trans Eng Manag
Jiang L, Scherz PA, Goetz S (2024) Patent-cr: A dataset for patent claim revision. arXiv:2412.02549
Jiang L, Zhang C, Scherz PA, Goetz S (2024) Can large language models generate high-quality patent claims? arXiv:2406.19465
Just J (2024) Natural language processing for innovation search-reviewing an emerging non-human innovation intermediary. Technovation 129:102883
Kamateri E, Salampasis M, Diamantaras K (2023) An ensemble framework for patent classification. World Patent Inf 75:102233
Kang J, Souili A, Cavallucci D (2018) Text simplification of patent documents. In: Automated invention for smart industries: 18th international TRIZ future conference, TFC 2018, Strasbourg, France, October 29–31, 2018, Proceedings. Springer, pp. 225–237
Kaplan J, McCandlish S, Henighan T, Brown TB, Chess B, Child R, Gray S, Radford A, Wu, J., Amodei, D.: Scaling laws for neural language models. arXiv:2001.08361 (2020)
Katz DM, Hartung D, Gerlach L, Jana A, Bommarito MJ (2023) Natural language processing in the legal domain. arXiv:2302.12039
Kim S, Yoon B (2022) Multi-document summarization for patent documents based on generative adversarial network. Expert Syst Appl 207:117983
Knappich V, Razniewski S, Hätty A, Friedrich A (2024) Pap2pat: Towards automated paper-to-patent drafting using chunk-based outline-guided generation. arXiv:2410.07009
Kovaleva O, Romanov A, Rogers A, Rumshisky A (2019) Revealing the dark secrets of bert. arXiv:1908.08593 [cs.CL]
Krestel R, Chikkamath R, Hewel C, Risch J (2021) A survey on deep learning for patent analysis. World Patent Inf 65:102035
Kucer M, Oyen D, Castorena J, Wu J (2022) Deeppatent: Large scale patent drawing recognition and retrieval. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision, pp. 2309–2318
Kyebambe MN, Cheng G, Huang Y, He C, Zhang Z (2017) Forecasting emerging technologies: a supervised learning approach through patent analysis. Technol Forecast Soc Chang 125:236–244
Larroyed A (2023) Redefining patent translation: the influence of chatgpt and the urgency to align patent language regimes in Europe with progress in translation technology. GRUR Int 72(11):1009–1017
Lee, J.-S.: Controlling patent text generation by structural metadata. In: Proceedings of the 29th ACM international conference on information & knowledge management, pp. 3241–3244 (2020)
Lee J-S (2023) Evaluating generative patent language models. World Patent Inf 72:102173
Lee J-S, Hsiang J (2020) Patent claim generation by fine-tuning openai gpt-2. World Patent Inf 62:101983
Lee J-S, Hsiang J (2020) Patent classification by fine-tuning bert language model. World Patent Inf 61:101965
Lee C, Kim J, Kwon O, Woo H-G (2016) Stochastic technology life cycle analysis using multiple patent indicators. Technol Forecast Soc Chang 106:53–64
Lee C, Kwon O, Kim M, Kwon D (2018) Early identification of emerging technologies: a machine learning approach using multiple patent indicators. Technol Forecast Soc Chang 127:291–303
Lee J, Lee J, Kang J, Kim Y, Jang D, Park S (2022) Multimodal deep learning for patent classification. In: Proceedings of sixth international congress on information and communication technology: ICICT 2021, London. Springer, Volume 4, pp. 281–289
Le Q, Mikolov T (2014) Distributed representations of sentences and documents. In: International conference on machine learning. PMLR, pp. 1188–1196
Li S, Hu J, Cui Y, Hu J (2018) Deeppatent: patent classification with convolutional neural networks and word embedding. Scientometrics 117:721–744
Lin C-Y (2004) Rouge: a package for automatic evaluation of summaries. In: Text summarization branches out, pp. 74–81
Lin W, Yu W, Xiao R (2023) Measuring patent similarity based on text mining and image recognition. Systems 11(6):294
Lin H, Wang H, Du D, Wu H, Chang B, Chen E (2018) Patent quality valuation with deep learning models. In: Database systems for advanced applications: 23rd international conference, DASFAA 2018, Gold Coast, QLD, Australia, May 21-24, 2018, Proceedings, Part II 23. Springer, pp. 474–490
Liu W, Li S, Cao Y, Wang Y (2023) Multi-task learning based high-value patent and standard-essential patent identification model. Inf Process Manag 60(3):103327
Liu A, Feng B, Xue B, Wang B, Wu B, Lu C, Zhao C, Deng C, Zhang C, Ruan C, et al (2024) Deepseek-v3 technical report. arXiv:2412.19437
Liu Q, Wu H, Ye Y, Zhao H, Liu C, Du D (2018) Patent litigation prediction: a convolutional tensor factorization approach. In: IJCAI, pp. 5052–5059
Lo H-C, Chu J-M, Hsiang J, Cho C-C (2024) Large language model informed patent image retrieval. arXiv:2404.19360
Lupu M, Fujii A, Oard DW, Iwayama M, Kando N (2017) Patent-related tasks at ntcir. Curr Chall Patent Inf Retrieval, 77–111
Lupu M, Huang J, Zhu J (2009) Tait J Trec-chem: large scale chemical information retrieval evaluation at trec. Acm Sigir Forum 43:63–70
Magdy W, Jones GJ (2010) Pres: a score metric for evaluating recall-oriented information retrieval applications. In: Proceedings of the 33rd international ACM SIGIR conference on research and development in information retrieval, pp. 611–618
Mansouri A, Mohammadpour M (2023) Determining technology life cycle prediction based on patent bibliometric data. Int J Inf Sci Manag (IJISM) 21(3):161–185
Martin L, De La Clergerie ÉV, Sagot B, Bordes A (2020) Controllable sentence simplification. In: Proceedings of the twelfth language resources and evaluation conference, pp. 4689–4698
Maurer A, Pontil M, Romera-Paredes B (2016) The benefit of multitask representation learning. J Mach Learn Res 17(81):1–32
Ma X, Wang L, Yang N, Wei F, Lin J (2023) Fine-tuning llama for multi-stage text retrieval. arXiv:2310.08319
Mikolov T, Chen K, Corrado G, Dean J (2013) Efficient estimation of word representations in vector space. arXiv:1301.3781
Min B, Ross H, Sulem E, Veyseh APB, Nguyen TH, Sainz O, Agirre E, Heintz I, Roth D (2023) Recent advances in natural language processing via large pre-trained language models: A survey. ACM Comput Surv 56(2):1–40
Nakano R, Hilton J, Balaji S, Wu J, Ouyang L, Kim C, Hesse C, Jain S, Kosaraju V, Saunders W, et al.: Webgpt: Browser-assisted question-answering with human feedback. arXiv:2112.09332 (2021)
OpenAI: Gpt-4 technical report. arXiv:2303.08774 (2023)
Papineni K, Roukos S, Ward T, Zhu W-J (2002) Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th annual meeting of the association for computational linguistics, pp. 311–318
Pennington J, Socher R, Manning CD (2014) Glove: global vectors for word representation. In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pp. 1532–1543
Piroi F, Hanbury A (2017) Evaluating information retrieval systems on European patent data: The clef-ip campaign. Curr Chall Patent Inf Retrieval, 113–142
Plantec Q, Le Masson P, Weil B (2021) Impact of knowledge search practices on the originality of inventions: a study in the oil & gas industry through dynamic patent analysis. Technol Forecast Soc Chang 168:120782
Potterie B, François D (2009) The cost factor in patent systems. J Ind Compet Trade 9(4):329–355
Pouliquen B (2015) Full-text patent translation at wipo; scalability, quality and usability. In: Proceedings of the 6th workshop on patent and scientific literature translation
President of the European Patent Office and Administrative Council of the European Patent Organisation: 2022 budget, estimates for 2023–2026, ca/50/21add.1b. Technical report, European Patent Organisation (2021)
Puccetti G, Giordano V, Spada I, Chiarello F, Fantoni G (2023) Technology identification from patent texts: a novel named entity recognition method. Technol Forecast Soc Chang 186:122160
Pu X, Gao M, Wan X (2023) Summarization is (almost) dead. arXiv:2309.09558
Pujari, S., Strötgen, J., Giereth, M., Gertz, M., Friedrich, A.: Three real-world datasets and neural computational models for classification tasks in patent landscaping. In: Proceedings of the 2022 conference on empirical methods in natural language processing, pp. 11498–11513 (2022)
Pustu-Iren K, Bruns G, Ewerth R (2021) A multimodal approach for semantic patent image retrieval. In: CEUR workshop proceedings; 2909, vol. 2909, pp. 45–49. Aachen, Germany: RWTH Aachen
Radford A, Kim JW, Hallacy C, Ramesh A, Goh G, Agarwal S, Sastry G, Askell A, Mishkin P, Clark J, et al.: (2021) Learning transferable visual models from natural language supervision. In: International conference on machine learning. PMLR, pp. 8748–8763
Radford A, Narasimhan K, Salimans T, Sutskever I, et al (2018) Improving language understanding by generative pre-training. OpenAI blog
Raffel C, Shazeer N, Roberts A, Lee K, Narang S, Matena M, Zhou Y, Li W, Liu PJ (2020) Exploring the limits of transfer learning with a unified text-to-text transformer. J Mach Learn Res 21(1):5485–5551
Rao A, Aithal S, Singh S (2024) Single-document abstractive text summarization: a systematic literature review. ACM Comput Surv
Ray PP (2023) Chatgpt: A comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope. Internet Things Cyber-Phys Syst
Reid M, Savinov N, Teplyashin D, Lepikhin D, Lillicrap T, Alayrac J-b, Soricut R, Lazaridou A, Firat O, Schrittwieser J, et al (2024) Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv:2403.05530
Reimers, N., Gurevych, I.: Sentence-bert: Sentence embeddings using siamese bert-networks. In: Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pp. 3982–3992 (2019)
Risch J, Krestel R (2019) Domain-specific word embeddings for patent classification. Data Technol Appl 53(1):108–122
Risch J, Alder N, Hewel C, Krestel R (2020) Patentmatch: a dataset for matching patent claims & prior art. arXiv:2012.13919
Risch J, Garda S, Krestel R (2020) Hierarchical document classification as a sequence generation task. In: Proceedings of the ACM/IEEE joint conference on digital libraries in 2020, pp. 147–155
Robertson S, Zaragoza H, et al.: (2009) The probabilistic relevance framework: Bm25 and beyond. Foundations and Trends® in Information Retrieval 3(4), 333–389
Roudsari AH, Afshar J, Lee S, Lee W (2021) Comparison and analysis of embedding methods for patent documents. In: 2021 IEEE international conference on big data and smart computing (BigComp), pp. 152–155. IEEE
Sarica S, Luo J, Wood KL (2020) Technet: technology semantic network based on patent data. Expert Syst Appl 142:112995
Sarica S, Song B, Luo J, Wood KL (2021) Idea generation with technology semantic network. AI EDAM 35(3):265–283
Sarica S, Song B, Low E, Luo J (2019) Engineering knowledge graph for keyword discovery in patent search. In: Proceedings of the design society: international conference on engineering design, vol. 1, pp. 2249–2258
Schmitt VJ, Denter NM (2024) Modeling an indicator for statutory patent novelty. World Patent Inf 78:102283
Schmitt VJ, Walter L, Schnittker FC (2023) Assessment of patentability by means of semantic patent analysis-a mathematical-logical approach. World Patent Inf 73:102182
Shalaby W, Zadrozny W (2019) Patent retrieval: a literature review. Knowl Inf Syst 61:631–660
Shalaby M, Stutzki J, Schubert M, Günnemann S (2018) An lstm approach to patent classification based on fixed hierarchy vectors. In: Proceedings of the 2018 SIAM international conference on data mining. SIAM, pp. 495–503
Shao Y, Mao J, Liu Y, Ma W, Satoh K, Zhang M, Ma S (2020) Bert-pli: Modeling paragraph-level interactions for legal case retrieval. In: IJCAI, pp. 3501–3507
Sharma E, Li C, Wang L (2019) Bigpatent: a large-scale dataset for abstractive and coherent summarization. In: Proceedings of the 57th annual meeting of the association for computational linguistics, pp. 2204–2213
Sheremetyeva S (2014) Automatic text simplification for handling intellectual property (the case of multiple patent claims). In: Proceedings of the workshop on automatic text simplification-methods and applications in the multilingual society (ATS-MA 2014), pp. 41–52
Shibayama S, Yin D, Matsumoto K (2021) Measuring novelty in science with word embedding. PLoS ONE 16(7):0254034
Shomee HH, Wang Z, Ravi SN, Medya S (2024) Impact: a large-scale integrated multimodal patent analysis and creation dataset for design patents. In: The thirty-eight conference on neural information processing systems datasets and benchmarks track
Shukla S, Sharma N, Gupta M, Mishra A (2025) Patentlmm: large multimodal model for generating descriptions for patent figures. In: AAAI
Siddharth L, Madhusudanan N, Chakrabarti A (2020) Toward automatically assessing the novelty of engineering design solutions. J Comput Inf Sci Eng 20(1):011001
Siddharth L, Blessing LT, Wood KL, Luo J (2022) Engineering knowledge graph from patent database. J Comput Inf Sci Eng 22(2):021008
Siddharth L, Li G, Luo J (2022) Enhancing patent retrieval using text and knowledge graph embeddings: a technical note. J Eng Des 33(8–9):670–683
Son J, Moon H, Lee J, Lee S, Park C, Jung W, Lim H (2022) Ai for patents: a novel yet effective and efficient framework for patent analysis. IEEE Access 10:59205–59218
Song K, Kim KS, Lee S (2017) Discovering new technology opportunities based on patents: text-mining and f-term analysis. Technovation 60:1–14
Souza CM, Santos ME, Meireles MR, Almeida PE (2019) Using summarization techniques on patent database through computational intelligence. In: Progress in artificial intelligence: 19th EPIA conference on artificial intelligence, EPIA 2019, Vila Real, Portugal, September 3–6, 2019, Proceedings, Part II 19, pp. 508–519. Springer
Souza CM, Meireles MR, Almeida PE (2021) A comparative study of abstractive and extractive summarization techniques to label subgroups on patent dataset. Scientometrics 126(1):135–156
Srinivas SS, Vaikunth VS, Runkana V (2024) Towards automated patent workflows: ai-orchestrated multi-agent framework for intellectual property management and analysis. arXiv:2409.19006
Sun X, Chen N, Ding K (2022) Measuring latent combinational novelty of technology. Expert Syst Appl 210:118564
Suzgun M, Melas-Kyriazi L, Sarkar SK, Kominers S, Shieber S(2023) The harvard USPTO patent dataset: A large-scale, well-structured, and multi-purpose corpus of patent applications. In: Thirty-seventh conference on neural information processing systems datasets and benchmarks track. https://openreview.net/forum?id=tk27oD2cBw
Tan M, Le Q (2019) Efficientnet: rethinking model scaling for convolutional neural networks. In: International conference on machine learning. PMLR, pp. 6105–6114
Touvron H, Martin L, Stone K, Albert P, Almahairi A, Babaei Y, Bashlykov N, Batra S, Bhargava P, Bhosale S, et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv:2307.09288 (2023)
Trappey AJ, Trappey CV, Govindarajan UH, Sun JJ (2019) Patent value analysis using deep learning models-the case of iot technology mining for the manufacturing industry. IEEE Trans Eng Manag 68(5):1334–1346
Trappey AJ, Trappey CV, Wu J-L, Wang JW (2020) Intelligent compilation of patent summaries using machine learning and natural language processing techniques. Adv Eng Inform 43:101027
Trappey A, Trappey CV, Hsieh A (2021) An intelligent patent recommender adopting machine learning approach for natural language processing: a case study for smart machinery technology mining. Technol Forecast Soc Chang 164:120511
United States Patent and Trademark Office (2023) United states patent and trademark office fiscal year 2024 ongressional submission. Technical report, Department of Commerce
United States Patent and Trademark Office: Manual of Patent Examining Procedure. https://www.uspto.gov/web/offices/pac/mpep/index.html. Accessed: 2023-06-12 (2022)
Utiyama M, Isahara H (2007) A japanese-english patent parallel corpus. In: Proceedings of machine translation summit XI: Papers
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I (2017) Attention is all you need. Adv Neural Inf Process Syst 30
Verhoeven D, Bakker J, Veugelers R (2016) Measuring technological novelty with patent-based indicators. Res Policy 45(3):707–723
Vowinckel K, Hähnke VD (2023) Searchformer: Semantic patent embeddings by siamese transformers for prior art search. World Patent Inf 73:102192
Wang B (2021) Mesh-Transformer-JAX: model-parallel implementation of transformer language model with JAX. https://github.com/kingoflolz/mesh-transformer-jax
Wang Q, Ni S, Liu H, Lu S, Chen G, Feng X, Wei C, Qu Q, Alinejad-Rokny H, Lin Y et al. (2024) Autopatent: a multi-agent framework for automatic patent generation. arXiv:2412.09796
Wang J, Chen Y-J (2019) A novelty detection patent mining approach for analyzing technological opportunities. Adv Eng Inform 42:100941
Wang H, Wu H, He Z, Huang L, Church KW (2022) Progress in machine translation. Engineering 18:143–153
Wang M, Sakaji H, Higashitani H, Iwadare M, Izumi K (2023) Discovering new applications: cross-domain exploration of patent documents using causal extraction and similarity analysis. World Patent Inf 75:102238
Wang J, Mudhiganti SKR, Sharma M (2024) Patentformer: a novel method to automate the generation of patent applications. In: Proceedings of the 2024 conference on empirical methods in natural language processing: industry track, pp. 1361–1380
Wang S, Yin X, Wang M, Guo R, Nan K (2024) Evopat: A multi-llm-based patents summarization and analysis agent. arXiv:2412.18100
Wang H, Zhang Y (2023) Learning efficient representations for image-based patent retrieval. arXiv:2308.13749
Wei T, Feng D, Song S, Zhang C (2024) An extraction and novelty evaluation framework for technology knowledge elements of patents. Scientometrics 129:1–26
Wirth M, Hähnke VD, Mascia F, Wéry A, Vowinckel K, Rey M, Pozo RM, Montes P, Klenner-Bajaja A: Building machine translation tools for patent language: A data generation strategy at the European patent office. In: Proceedings of the 24th annual conference of the European association for machine translation, pp. 471–479 (2023)
World intellectual property organization: PCT regulations rule. https://www.wipo.int/pct/en/texts/rules/rtoc1.html. Accessed: 2023-06-12 (2022)
Wu H, Zhu G, Liu Q, Zhu H, Wang H, Zhao H, Liu C, Chen E, Xiong H (2023) A multi-aspect neural tensor factorization framework for patent litigation prediction. IEEE Trans Big Data
Xiong W, Liu J, Molybog I, Zhang H, Bhargava P, Hou R, Martin L, Rungta R, Sankararaman KA, Oguz B, et al.: Effective long-context scaling of foundation models. arXiv:2309.16039 (2023)
Xu P, Ping W, Wu X, McAfee L, Zhu C, Liu Z, Subramanian S, Bakhturina E, Shoeybi M, Catanzaro B (2024) Retrieval meets long context large language models. In: The twelfth international conference on learning representations
Yao L, Ni H (2023) Prediction of patent grant and interpreting the key determinants: an application of interpretable machine learning approach. Scientometrics 128(9):4933–4969
Ying C, Shuyu Y, Jing L, Lin D, Qi Q (2021) Errors of machine translation of terminology in the patent text from English into Chinese. ASP Trans Comput 1(1):12–17
Zaheer M, Guruganesh G, Dubey KA, Ainslie J, Alberti C, Ontanon S, Pham P, Ravula A, Wang Q, Yang L et al (2020) Big bird: transformers for longer sequences. Adv Neural Inf Process Syst 33:17283–17297
Zanella G, Liu CZ, Choo K-KR (2021) Understanding the trends in blockchain domain through an unsupervised systematic patent analysis. IEEE Trans Eng Manag
Zhang L, Liu W, Chen Y, Yue X (2022) Reliable multi-view deep patent classification. Mathematics 10(23):4545
Zhang L, Zhang T, Lang Y, Li J, Ji F (2024) Research on patent quality evaluation based on rough set and cloud model. Expert Syst Appl 235:121057
Zhang T, Kishore V, Wu F, Weinberger KQ, Artzi Y (2019) Bertscore: evaluating text generation with bert. In: International conference on learning representations
Zhang J, Zhao Y, Saleh M, Liu P (2020) Pegasus: pre-training with extracted gap-sentences for abstractive summarization. In: International conference on machine learning. PMLR, pp. 11328–11339
Zhao WX, Zhou K, Li J, Tang T, Wang X, Hou Y, Min Y, Zhang B, Zhang J, Dong Z, et al (2023) A survey of large language models. arXiv:2303.18223
Zhao J, Xie X, Xu X, Sun S (2017) Multi-view learning overview: recent progress and new challenges. Inf Fusion 38:43–54
Zhou Y, Dong F, Liu Y, Li Z, Du J, Zhang L (2020) Forecasting emerging technologies using data augmentation and deep learning. Scientometrics 123:1–29
Zhou Y, Dong F, Liu Y, Ran L (2021) A deep learning framework to early identify emerging technologies in large-scale outlier patents: an empirical study of cnc machine tool. Scientometrics 126:969–994
Zhu H, He C, Fang Y, Ge B, Xing M, Xiao W (2020) Patent automatic classification based on symmetric hierarchical convolution neural network. Symmetry 12(2):186
Zhu Q, Luo J (2022) Generative design ideation: a natural language generation approach. In: International conference on-design computing and cognition. Springer, pp. 39–50
Zou T, Yu L, Sun L, Du B, Wang D, Zhuang F (2023) Event-based dynamic graph representation learning for patent application trend prediction. IEEE Trans Knowl Data Eng
Zuo Y, Gerdes K, Clergerie, ’E, Sagot B Patenteval (2024) Understanding errors in patent generation. In: Proceedings of the 2024 conference of the North American chapter of the association for computational linguistics: human language technologies. Vol 1: Long Papers, pp. 2687–2710
Funding
No funding was received to assist with the preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
LJ and SMG wrote the manuscript. LJ led the writing as well as the search process and designed the images. SMG designed the research and revised the text.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no conflict of interest to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Patent drawings and metadata
Apart from patent texts, researchers also use metadata and images for patent analysis. Metadata typically includes citations/references, classification codes, inventors, applicants, assignees, law firms, and examiners. Researchers have exploited the relationship information between patents through citations and classification codes based on graph neural networks (GNNs) for patent classification and patent valuation. Solely relying on classification codes can sometimes be misleading and become a problem because patents may span multiple technology areas. Furthermore, the publicly used classification is rather coarse in light of the high number of documents and notably coarser than what offices use internally for their search or assigning competent examiners. Importantly, metadata provide high-level information but do typically not include details of the invention, which limits the possibility of capturing the invention and certainly not technical nuances.
The images, called drawings or figures in patents, could leverage the development of image processing techniques, particularly convolutional neural networks (CNNs). However, the figures can be very generic, particularly in method inventions. The fact that patent figures are not supposed to contain (significant) text beyond reference numbers, can have technological advantages. Patent figures from computer aided design (CAD) models may be harder to match with corresponding ones from other documents due to the high number of lines representing details, which tend to overwhelm convolutional neural networks. However, many patents and patent applications contain simpler sketches and schematic figures with the intention to not disclosing more than necessary. Such simplifications can be beneficial for processing with artificial intelligence. By now, researchers have applied convolutional neural networks in patent subject classification and patent retrieval. However, considering the above, the performance of patent classification based on images only appears to be much worse than using texts. Therefore, hybrid methods that leverage multiple sources for patent analysis, such as texts, images, and classification codes, appear promising.
The drawings are not helpful for automated processing in many cases. Methods are commonly illustrated as block diagrams, but these diagrams, without supplementary text beyond reference numbers-which many patent offices do not accept for formal reasons-become ambiguous and could be interpreted as representing completely different and undeniably novel inventions. Furthermore, the size and rapid growth of patent descriptions (including applications that are not granted) and the scientific-technical literature worldwide pose significant challenges to the prior-art search.
1.1 Patent classification
Images can serve for automated patent classification (Jiang et al. 2021). There is usually no specific feature extraction process. Deep-learning networks, typically convolutional neural networks, can automatically extract image features from the pixel values. Jiang et al. designed a method based on convolutional neural networks for patent classification using only images and achieved 54.32% accuracy on eight-class prediction (Jiang et al. 2021). The results are poorer than text-based methods for two main reasons. Firstly, predicting the subject class based solely on images is inherently challenging, even for human experts.Footnote 20 Secondly, some patent images suffer from low resolution. However, using images as additional information for patent classification on top of the text may be a promising research direction.
1.2 Patent retrieval
Metadata-based methods. Commonly used metadata includes citations / references, classification codes, inventors, applicants, assignees, and examiners. Involving metadata for patent retrieval may improve the retrieval performance because metadata can imply relevance among documents (Shalaby and Zadrozny 2019). For example, citations naturally indicate the relationship between patent documents, documents that belong to the same category may have connections, and an inventor may tend to investigate similar types of inventions. A representative study would be the embedding method that used both texts and metadata for patent representation (Siddharth et al. 2022). The authors aggregated text embeddings obtained from Sentence-BERT and citation embedding obtained from knowledge graphs to formulate the patent representation. This method improved the accuracy by approximately 6% compared to using text only.
Image-based methods. Recently, the rapid development of image processing techniques has directed the attention of retrieval tasks to patent drawings. Kucer et al. (2022) introduced a large-scale dataset, DeepPatent, for an image-based patent retrieval benchmark. The dataset includes 45,000 unique design patents and 350,000 drawings from 2018 and the first half of 2018 from the United States Patent and Trademark Office. This paper also implemented the PatentNet model as a baseline, a deep learning approach based on the ResNet architecture (He et al. 2016). It achieved a 0.376 mean average precision (MAP), which was better than traditional computer vision approaches and other deep representations tested in their experiments. After that, Wang and Zhang (2023) improved the performance to 0.712 by leveraging the unique characteristics of patent drawings. The authors used EfficientNet-B0 (Tan and Le 2019) as the backbone, which is an effective and efficient convolutional network. They also incorporated a neck structure that comprises a fully connected layer and a consecutive batch normalization layer to improve the intra-class compactness and inter-class discrimination. In addition, Higuchi and Yanai (2023) proposed a transformer-based deep metric learning architecture, which reached a new state-of-the-art mean average precision score of 0.856 on the DeepPatent dataset.
1.3 Figure caption/description generation
Researchers studied generating brief descriptions of the patent figures. Aubakirova et al. (2023) introduced the first large-scale patent figure dataset, comprising more than 30,000 figure–caption pairs. The authors fine-tuned large vision language models to generate captions as baselines on this novel dataset and call for future research on the improvement of existing caption generation models. As contextual information, the quality of such brief figure descriptions can vary significantly. In quite many cases, the figure captions read Figure n depicts another embodiment of the invention or Figure m depicts perspective xy of an embodiment of the invention to fulfill the minimum formalities (e.g., per European Patent Regulations Rule 42(d), PCT Regulations Rule 5.1(a)(iv), US 37 CFR 1.74) and let the subsequent detailed description of the figures and embodiments provide more content. Similarly, Shukla et al. (2025) presented PatentDesc, a novel large-scale dataset that comprises approximately 355K patent figures paired with both brief and detailed textual descriptions. They trained a vision encoder specifically designed for patent figures and demonstrated that it can significantly enhance the generation performance. Furthermore, Shomee et al. (2024) introduced IMPACT, a multimodal patent dataset that contains 3.61 million design patent figures paired with detailed captions and rich metadata. They used the dataset to build benchmarks for two novel computer vision tasks—3D image construction and visual question answering (VQA).
Appendix B: Evaluation metrics
Evaluation metrics quantify a model’s performance, offering a clear and objective measure of how well the model can achieve the intended task. This is essential for understanding the model’s capabilities and limitations. In addition, metrics allow researchers and developers to compare the effectiveness of different models or algorithms on the same task. By understanding the most relevant metrics to a specific task, developers can select or design models that are optimized for those metrics. Different metrics are used based on task types. We introduce some common evaluation metrics for different tasks, including classification (Sect. B.1), information retrieval (Sect. B.2), and text generation (Sect. B.3).
1.1 Classification
Widely used metrics for classification tasks are accuracy (A)
precision (P)
recall (R)
and F1 scores (F1)
where true positives (TP) refer to the number of samples that are correctly predicted as positive, true negatives (TN) the number of samples that are correctly predicted as negative, false positives (FP) the number of samples that are wrongly predicted as positive, and false negatives (FN) the number of samples that are wrongly predicted as negative.
There are two methods of aggregating performance metrics across classes, namely macro-averaging and micro-averaging. Macro-averaging calculates the metric independently for each class and then takes the numerical average. This means the weights of all classes are equal, regardless of size or frequency. For example, macro-averaged precision can be calculated per
where N is the number of classes.
In micro-averaging, the process involves summing up all TP, FP, and FN respectively across classes, followed by the calculation of the metric. By default, micro-averaging often serves as the preferred method unless specified otherwise, due to its ability to more appropriately handle class imbalances by assigning more weight to the majority class. Micro-averaged precision can for instance follow
1.2 Information retrieval
In information retrieval tasks, precision (P)
recall (R)
and mean average precision (MAP)
usually serve for evaluation (Baeza-Yates et al. 1999).
\(N_R\) is the number of relevant documents retrieved, \(N_T\) the total number of documents retrieved, and \(N_K\) the total number of really relevant documents. Q denotes the total number of required queries, \(m_q\) the number of relevant documents for the q-th query, \(n_q\) the number of documents retrieved for the q-th query, P(k) the precision at the k-th position, and \(\sigma (k)\) an indicator function that equals 1 if the k-th document is relevant, and 0 otherwise.
In addition, the patent retrieval evaluation score (PRES)
is a metric specifically designed to evaluate the performance of patent retrieval systems (Magdy and Jones 2010). N represents the number of relevant documents, \(N_{max}\) the maximum number of documents returned by the retrieval system, and \(r_i\) the rank of the i-th relevant document in the retrieval results. It calculates the average deviation of the actual ranking of relevant documents from their ideal ranking with normalization.
1.3 Text generation
Evaluation metrics provide feedback that is used to adjust the model’s parameters and improve its performance. This optimization is critical to developing highly accurate and efficient models. The most reliable but expensive and slow evaluation methods for text generation are human evaluations. Human evaluation involves assessing the quality of the generated text by human experts. Multiple aspects are evaluated simultaneously, such as accuracy, fluency, coherence, and relevance. Human evaluation is often considered the gold standard, but it can be time-consuming and expensive.
Researchers have developed automated evaluation methods for text generation to improve efficiency and reduce costs. These approaches compare generated texts with referenced texts (gold standard) to obtain the performance score. We briefly introduce four of the most commonly used methods, including BLEU (Papineni et al. 2002), ROUGE (Lin 2004), METEOR (Banerjee and Lavie 2005), and BERTScore (Zhang et al. 2019).
Bilingual evaluation understudy (BLEU) score (Papineni et al. 2002) quantifies how much the generated texts match the high-quality reference texts, by comparing the n-grams to count the number of exact matches. BLEU is simple and easy to use, but it only focuses on literal matches, overlooking overall sentence semantics. BLEU was originally designed for machine translation but could also be used for other generation tasks.
Recall-oriented understudy for gisting evaluation (ROUGE) counts the number of overlapping units, such as n-gram and word sequences, to obtain the performance score (Lin 2004). While BLEU focuses more on precision, i.e., how many generated texts match reference texts, ROUGE prioritizes more recall performance, i.e., how many reference texts are covered by generated texts. Hence, this method is more suitable for text summarization tasks. Similar to BLEU, it evaluates text content, without considering semantics or synonyms.
Metric for evaluation of translation with explicit ordering (METEOR) improves on BLEU by accounting for both exact word matches and similar words based on stemming and synonyms (Banerjee and Lavie 2005). Thus, METEOR can better account for semantic variations compared to BLEU. In addition, METEOR provides a more balanced assessment by considering both precision and recall. However, METEOR is more complex and needs adjustments for different tasks.
BERTScore (Zhang et al. 2019) leverages the contextual embedding from BERT (Devlin et al. 2018) and calculates cosine similarity between output text embedding and referenced embedding. It can effectively capture complex and subtle semantic information but requires significant computational resources for evaluation.
Recently, Lee (2023) proposed a novel keystroke-based evaluation method for generative patent models. This method measured the number of keystrokes that the model could save by providing model predictions in an auto-complete function. The experimental results demonstrated that the larger models could not improve this specific evaluation metric. However, the experiments only focused on patent claims generation and the effectiveness of this metric on other generative tasks was unknown.
A recent work proposed PatentEval as a human evaluation framework to evaluate machine-generated patent texts (Zuo et al. 2024). The framework categorizes errors into different types, such as grammatical errors, irrelevant content, incomplete coverage, and clarity issues. The authors manually assessed 400 granted patents and indicated that while LLMs demonstrate potential for patent drafting, they still exhibit limitations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jiang, L., Goetz, S.M. Natural language processing in the patent domain: a survey. Artif Intell Rev 58, 214 (2025). https://doi.org/10.1007/s10462-025-11168-z
Accepted:
Published:
DOI: https://doi.org/10.1007/s10462-025-11168-z