
Abstract
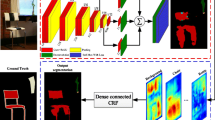
Deep convolutional neural networks trained with strong pixel-level supervision have recently significantly boosted the performance in semantic image segmentation. The receptive field is a crucial issue in such visual tasks, as the output must capture enough information about large objects to make a better decision. In DCNNs, the theoretical receptive field size could be very large, but the effective receptive field may be quite small. The latter is an really important factor in performance. In this work, we defined a method of measuring effective receptive field. We observed that stacking layers with large receptive field can increase the size of receptive field and increase the density of receptive field. Based on the observation, we designed a Dense Global Context Module, which makes the effective receptive field coverage larger and density higher. With the Dense Global Context Module, segmentation model reduces a large number of parameters while the performance has been substantially improved. Massive experiments proved that our Dense Global Context Module exhibits very excellent performance on the PASCAL VOC2012 and PASCAL CONTEXT data set.





Similar content being viewed by others

Explore related subjects
Discover the latest articles and news from researchers in related subjects, suggested using machine learning.References
Badrinarayanan V, Kendall A, Cipolla R (2015) Segnet: A deep convolutional encoder-decoder architecture for image segmentation. arXiv:151100561
Baehrens D, Schroeter T, Harmeling S, Kawanabe M, Hansen K, MÞller KR (2010) How to explain individual classification decisions. J Mach Learn Res 11(Jun):1803–1831
Chen LC, Papandreou G, Kokkinos I, Murphy K, Yuille AL (2016a) Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. arXiv:160600915
Chen LC, Yang Y, Wang J, Xu W, Yuille AL (2016b) Attention to scale: Scale-aware semantic image segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 3640–3649
Chen LC, Papandreou G, Schroff F, Adam H (2017) Rethinking atrous convolution for semantic image segmentation. arXiv:170605587
Eigen D, Fergus R (2015) Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In: Proceedings of the IEEE International Conference on Computer Vision, pp 2650–2658
Everingham M, Eslami SA, Van Gool L, Williams CK, Winn J, Zisserman A (2015) The pascal visual object classes challenge: A retrospective. Int J Comput Vis 111(1):98–136
Farabet C, Couprie C, Najman L, LeCun Y (2013) Learning hierarchical features for scene labeling. IEEE Trans Pattern Anal Mach Intell 35(8):1915–1929
Ghiasi G, Fowlkes CC (2016) Laplacian reconstruction and refinement for semantic segmentation. CoRR, arXiv:1605022641
Girshick R, Donahue J, Darrell T, Malik J (2014) Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 580–587
Hariharan B, Arbeláez P, Bourdev L, Maji S, Malik J (2011) Semantic contours from inverse detectors. In: IEEE International Conference on Computer Vision (ICCV), 2011. IEEE, pp 991–998
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 770–778
Jia Y, Shelhamer E, Donahue J, Karayev S, Long J, Girshick R, Guadarrama S, Darrell T (2014) Caffe: Convolutional architecture for fast feature embedding. In: Proceedings of the 22nd ACM international conference on Multimedia, ACM, pp 675–678
Koltun V (2011) Efficient inference in fully connected crfs with gaussian edge potentials. Adv Neural Inf Process Syst 2(3):4
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. In: Advances in neural information processing systems, pp 1097–1105
Lin G, Milan A, Shen C, Reid I (2016a) Refinenet: Multi-path refinement networks with identity mappings for high-resolution semantic segmentation. arXiv:161106612
Lin G, Shen C, van den Hengel A, Reid I (2016b) Efficient piecewise training of deep structured models for semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 3194–3203
Lin TY, Maire M, Belongie S, Hays J, Perona P, Ramanan D, Dollár P, Zitnick CL (2014) Microsoft coco: Common objects in context. In: European Conference on Computer Vision. Springer, pp 740– 755
Liu Z, Li X, Luo P, Loy CC, Tang X (2015) Semantic image segmentation via deep parsing network. In: Proceedings of the IEEE International Conference on Computer Vision, pp 1377–1385
Long J, Shelhamer E, Darrell T (2015) Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 3431–3440
Long JL, Zhang N, Darrell T (2014) Do convnets learn correspondence? In: Advances in Neural Information Processing Systems, pp 1601–1609
Luo W, Li Y, Urtasun R, Zemel R (2016) Understanding the effective receptive field in deep convolutional neural networks. In: Advances in Neural Information Processing Systems, pp 4898– 4906
Mottaghi R, Chen X, Liu X, Cho NG, Lee SW, Fidler S, Urtasun R, Yuille A (2014) The role of context for object detection and semantic segmentation in the wild. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 891–898
Noh H, Hong S, Han B (2015) Learning deconvolution network for semantic segmentation. In: Proceedings of the IEEE International Conference on Computer Vision, pp 1520–1528
Oquab M, Bottou L, Laptev I, Sivic J (2015) Is object localization for free?-weakly-supervised learning with convolutional neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 685–694
Papandreou G, Chen LC, Murphy KP, Yuille AL (2015) Weakly-and semi-supervised learning of a deep convolutional network for semantic image segmentation. In: Proceedings of the IEEE International Conference on Computer Vision, pp 1742–1750
Peng C, Zhang X, Yu G, Luo G, Sun J (2017) Large kernel matters–improve semantic segmentation by global convolutional network. arXiv:170302719
Pinheiro P, Collobert R (2014) Recurrent convolutional neural networks for scene labeling. In: International Conference on Machine Learning, pp 82–90
Pohlen T, Hermans A, Mathias M, Leibe B (2016) Full-resolution residual networks for semantic segmentation in street scenes. arXiv:161108323
Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241
Shimoda W, Yanai K (2016) Distinct class-specific saliency maps for weakly supervised semantic segmentation. In: European Conference on Computer Vision, Springer, pp 218–234
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Simonyan K, Vedaldi A, Zisserman A (2013) Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv:13126034
Tompson JJ, Jain A, LeCun Y, Bregler C (2014) Joint training of a convolutional network and a graphical model for human pose estimation. In: Advances in neural information processing systems, pp 1799– 1807
Yu F, Koltun V (2015) Multi-scale context aggregation by dilated convolutions. arXiv:151107122
Zhao H, Shi J, Qi X, Wang X, Jia J (2017) Pyramid scene parsing network. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Zheng S, Jayasumana S, Romera-Paredes B, Vineet V, Su Z, Du D, Huang C, Torr PH (2015) Conditional random fields as recurrent neural networks. In: Proceedings of the IEEE International Conference on Computer Vision, pp 1529–1537
Zhou B, Khosla A, Lapedriza A, Oliva A, Torralba A (2014) Object detectors emerge in deep scene cnns. arXiv:14126856
Acknowledgments
Prof. Liu is supported by the Major Projects entrusted by the National Social Science Fund of China (Under Grant 16ZH017A3) and Program for Changjiang Scholars and Innovative Research Team in University (PCSIRT) granted by Ministry of Education, China. Dr. Han is supported by the NSFC (Under Grant U1509206,61472276)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Liu, Y., Yu, J. & Han, Y. Understanding the effective receptive field in semantic image segmentation. Multimed Tools Appl 77, 22159–22171 (2018). https://doi.org/10.1007/s11042-018-5704-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-018-5704-3