
Abstract
Immune events such as infection, vaccination, and a combination of the two result in distinct time-dependent antibody responses in affected individuals. These responses and event prevalence combine non-trivially to govern antibody levels sampled from a population. Time-dependence and disease prevalence pose considerable modeling challenges that need to be addressed to provide a rigorous mathematical underpinning of the underlying biology. We propose a time-inhomogeneous Markov chain model for event-to-event transitions coupled with a probabilistic framework for antibody kinetics and demonstrate its use in a setting in which individuals can be infected or vaccinated but not both. We conduct prevalence estimation via transition probability matrices using synthetic data. This approach is ideal to model sequences of infections and vaccinations, or personal trajectories in a population, making it an important first step towards a mathematical characterization of reinfection, vaccination boosting, and cross-events of infection after vaccination or vice versa.
Similar content being viewed by others
Explore related subjects
Discover the latest articles and news from researchers in related subjects, suggested using machine learning.Avoid common mistakes on your manuscript.
1 Introduction
As a disease becomes endemic and vaccination widespread, the ability to characterize the antibody response across time and events can become as important as the capacity to track epidemiological trends. Analysis of antibody testing can characterize the immune response to infection or vaccination and provides information with which to make population-level decisions (Caini et al. 2020; Peeling et al. 2020). Accurate interpretation of an antibody measurement randomly sampled from a population should depend on the prevalence at the time of measurement, whether the sample was obtained from a vaccinated or infected individual, and when the measurement was taken. These effects can be seen in biological literature, and have been separately modeled in cohesive probabilistic frameworks (Patrone and Kearsley 2021; Bedekar et al. 2022; Böttcher et al. 2022; Patrone et al. 2022; Luke et al. 2023). However, existing methods are not equipped to consider both transmission dynamics and time-dependent antibody response in a multiclass setting.
To overcome these real-world obstacles, we must consider mathematical models that bridge multiple scales by simultaneously considering the effects of (i) prevalence, (ii) more than two classes, and (iii) time-dependence. A shortcoming of canonical models for communicable diseases, such as susceptible-infected-recovered (SIR) models or statistical regression models, is their inability to track population-level antibody responses across time, even though many capture global transmission dynamics of viral infections by using a proxy for immune response (e.g., D’Arienzo and Coniglio 2020; McMahon et al. 2020; Quick et al. 2021; Roberto Telles et al. 2021). In one example, Dick et al. (2021) built an age-structured SIR-type model of boosting and waning immunity to severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) infection. Their model estimates prevalence as the total population with some “immunity” (not defined). To address viral evolution and antibody response, within-host differential equation models have been created, studying questions such as the protection time of antibodies (e.g., Wodarz 2005; Hernandez-Vargas and Velasco-Hernandez 2020; dePillis et al. 2023; Xu et al. 2023); such models ignore population-level trends. Finally, as an example of an approach that addresses time-dependence and antibody levels, Hay et al. (2019) applied Markov chain Monte Carlo methods to influenza infections or vaccinations in ferrets. None of these works addressed all three effects (i, ii, and iii) simultaneously, nor their complex multi-scale interactions.
There is a rich literature on longitudinal immune response dynamics (e.g., Diep et al. 2023; Guo et al. 2023; Liu et al. 2023) and many seroprevalence studies have been conducted (e.g., Osborne et al. 2000; Pollán et al. 2020; Bajema et al. 2021); a mathematical framework is needed to analyze measurements and make decisions. This is no easy feat; time-dependence, prevalence, and multiple classes combine non-trivially and pose considerable modeling challenges. In prior work we have addressed questions of time-dependence and multiclass situations separately via probabilistic modeling (Bedekar et al. 2022; Luke et al. 2023); both included prevalence estimation schemes. These works constructed mathematical machinery to calculate the probabilities of events of interest, such as single infections, but not a way to track transitions from one event to another or estimate an individual’s antibody levels associated with a sequence of events. To fully address the task of modeling real-life situations, a time-inhomogeneous Markov chain model for event-to-event transitions can be used to extend the probabilistic framework already in place.
In this paper, we combine our prior work (Bedekar et al. 2022; Luke et al. 2023) into a probabilistic model for the time-dependent antibody kinetics of the situation in which an individual either gets infected or vaccinated and then stays in that class (Sect. 3). Using methods mirroring Bedekar et al. (2022) and Luke et al. (2023), we develop a prevalence estimation scheme for naïve, infected, or vaccinated samples. We then present the same problem through the lens of a time-inhomogeneous Markov chain model (Sect. 4); such a formulation facilitates generalization to the case where reinfections and revaccinations are allowed. We demonstrate the equivalence of our extension of prior work and Markov chain frameworks by defining the transition probabilities through the class incidences and prevalence on a given time step. In addition, we develop a transition probability matrix estimation framework that allows for an equivalent method of prevalence estimation by utilizing unlabeled antibody data from the population. We validate our methods using synthetic data based on SARS-CoV-2 serological measurements (Abela et al. 2021; Congrave-Wilson et al. 2022)Footnote 1 in Sect. 5. The discussion includes further analysis of prevalence estimation, comparisons to other approaches, limitations, and extensions (Sect. 6). We present this work to bridge the gap to the most general model in which reinfections, revaccinations, and cross events will be allowed.
2 Notation
Below is a summary of baseline terminology and descriptions of terms as they pertain to our work.
2.1 Definitions from Applied Diagnostics
-
The naïve class consists of individuals who have no history of infection or vaccination. In a binary classification setting, such individuals are often referred to as ‘negative’.
-
The infected class consists of individuals who have been acutely or previously infected but who are unvaccinated. In a binary classification setting, such individuals are often referred to as ‘positive’.
-
The vaccinated class consists of individuals with a new or prior inoculation against a disease without a prior infection.
-
Incidence refers to the fraction of new infections or vaccinations in the total population during a given time step (Bouter et al. 2023). We define an infection incidence and a vaccination incidence.
-
A class prevalence during a given time step after the emergence of a disease is the fraction of individuals in the population in that class on that time step and is the sum of the incidences over all previous time steps.
-
Training data correspond to sample antibody measurements from individuals for whom the true classes are known. Typically, such data are used to construct conditional probability models.
-
Test data correspond to sample antibody measurements from individuals for whom the true classes are unknown or assumed to be unknown for validation purposes. Typically, a prevalence estimation procedure is applied to such data.
-
Personal timeline refers to the duration since infection or vaccination for an individual.
-
Absolute timeline denotes time relative to the emergence of the disease.
2.2 Notation Specific to this Paper
-
Antibody measurement is denoted by vector \(\varvec{r}\). The set \(\Omega \) denotes the entire measurement space.
-
The prevalence for each class is denoted by \(q_J\) and the incidence by \(f_J\), with \(J = N, I, V\) denoting the class as naïve, infected, or vaccinated. These are functions of time.
-
The use of the symbol
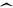 denotes an estimated quantity.
denotes an estimated quantity.
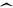 denotes an estimated quantity.
denotes an estimated quantity.3 Multiclass Extension of Existing Time-Dependent Theory
In this section, we combine our prior work (Bedekar et al. 2022; Luke et al. 2023) to arrive at a probabilistic model for the time-dependent antibody kinetics of the situation in which an individual either gets infected or vaccinated, and then stays in that class. Here, the focus lies on explicitly enumerating all the ways in which, for example, an individual could have been infected by a certain time period. This will be contrasted with a Markov chain approach in Sect. 4 where the focus is on keeping track of transitions in the population every time period.
For both Sects. 3 and 4, the following holds true. A blood or saliva sample from an individual is measured to obtain an antibody measurement \(\varvec{r}\), a vector in some compact domain \(\Omega \subset {\mathbb {R}}^n\). The boundaries of \(\Omega \) are governed by the measurement range of the instrument used. We generally use t to indicate time in the personal timeline, which is the duration since infection or vaccination for an individual. We generally use T to denote time in the absolute timeline in the emergence of the disease. We consider time to be discrete in this manuscript, as antibody measurements are generally reported at regular time intervals.
3.1 Probability Models
The antibody response to infection or vaccination is time dependent, but that of an immuno-naïve individual is not. This is a basic assumption of our probability models. Let \(N(\varvec{r}) = \text {Prob}(\varvec{r} | \text {Nave})\) denote the probability density that a sample yields measurement \(\varvec{r}\) given that the true underlying class is naïve. Here we use Prob to denote probability density. Let \(I(\varvec{r}, T) = \text {Prob}(\varvec{r}, T | \text {Infected})\) give the probability density that a sample yields measurement \(\varvec{r}\) on time step T of the absolute timeline given that the true underlying class is infected. \(V(\varvec{r}, T)\) is similarly defined for the vaccinated class. Note that in contrast to an SIR framework, we have no recovered class; the infected class consists of individuals whose symptoms may have subsided but their antibody response is still determined by the infection event. For our three classes, we assume
We consider time to be discretized such that one time step is of length dt days, as information is reported, e.g., once per day or as seven-day averages of new caseloads.
Each class has an associated prevalence: \(q_N(T), q_I(T),\) and \( q_V(T)\), denoting the fraction of the population in each class at time step T. Prevalence quantifies the total fraction of the population incident into that class so far and thus takes values in the range [0, 1]. Since we assume that reinfection, revaccination, and infection after vaccination or vice versa do not occur, once someone is infected, they move into the infected class and stay there; similarly for vaccination. As a result, \(q_I\) and \(q_V\) increase over time, and \(q_N\) decreases over time.
The probabilities above combine to form the measurement density \(Q(\varvec{r}, T)\) that a sample collected on time step T has antibody level \(\varvec{r}\). The law of total probability gives
We want to construct \(I(\varvec{r}, T)\), which is naturally composed of the probabilities of being infected on different time steps before time step T. Via the law of total probability, following Bedekar et al. (2022), we find
Note that this conditional probability density can be determined in this straightforward way because the set of collectively exhaustive events are defined by the date of infection, since we assume this occurs once and only once. Let R denote the probability density of observing a measurement \(\varvec{r}\), t time steps after infection. We then have
where \(f_I(T)\) describes the infection incidence, or fraction of the total population that is infected on time step T of the absolute timeline. Define \(V(\varvec{r},t)\) and \(f_V\) similarly, where W is analogous to R:
Due to the assumptions stated earlier, \(f_I, f_V \ge 0\). The infection and vaccination incidences sum to the prevalence of their respective classes:
and the prevalence for classes are related:
Motivated by the limiting behavior of antibody kinetics as in Bedekar et al. (2022), the naïve distribution is identical to both the infected and vaccinated distributions on time step 0 of the personal timeline and asymptotically:
Replacement in Eq. (2) using Eqs. (4), (5), and (8) and combining and rearranging terms gives
3.2 Prevalence Estimation
Unbiased estimators can be constructed for the prevalence of these classes, \(q_N(T), q_I(T)\), and \(q_V(T)\). Introduce a partition \(\{D_1, D_2, D_3\}\) of the domain \(\Omega \) such that
Then define
where
and \(W_j\) is defined similarly to \(R_j\). Then, arbitrarily choosing to use \(D_1\) and \(D_2\), using Eq. (11), for \(T = 1\) we have
and similarly
In matrix form this is given by
To simplify notation, let \(\varvec{f}(0) = [f_I(0), f_V(0)]^T\), \(\varvec{M}(1) = \begin{bmatrix} R_1(1) & W_1(1) \\ R_2(1) & W_2(1) \end{bmatrix}\),
\(\varvec{N}^* = [N_1, N_2]^T [1,1]\), \(\varvec{N} = [N_1, N_2]^T\) and \(\varvec{Q}(1) = [Q_1(1), Q_2(1)]^T\). Then \(\varvec{Q}(1)\) can be written as
Solving for \(\varvec{f}(0)\) gives
Define the Monte Carlo estimators \(\hat{Q}_j(T)\) by
where \({\mathbb {I}}_j\) is the indicator function on \(D_j\) and \(\{\varvec{r}_1, \ldots , \varvec{r}_S\}\) is the set of sample values observed on time step T from S randomly-collected samples. Let \(\varvec{\hat{f}}(0) = [\hat{f}_I(0), \hat{f}_V(0)]^T\) and \(\varvec{\hat{Q}}(1) = [ \hat{Q}_1(1), \hat{Q}_2(1)]^T\). Then, we can estimate \(\varvec{f}(0)\), which contains the fractions of the population newly infected or vaccinated, on time step 0, via
We will assume that the inverse in Eq. (20) exists; additional discussion follows in Sect. 4.
We now iterate in this vein to obtain linear systems in terms of previously obtained estimates. Let \(\varvec{f}(t) = [f_I(t), f_V(t)]^T\), \(\varvec{M}(T-t) = \begin{bmatrix} R_1(T-t) & W_1(T-t) \\ R_2(T-t) & W_2(T-t) \end{bmatrix}\), and \(\varvec{\hat{Q}}(T) = [\hat{Q}_1(T), \hat{Q}_2(T)]^T\). We estimate the fraction of the population newly infected on time step \(T-1\) to be
Notice that we use the Monte-Carlo estimate from the population at time step T since the emergence of the disease to obtain information about the prevalence at the previous time step. This is because we cannot immediately discern new infections or vaccinations from the naïve population due to the time lag in personal antibody response (Bedekar et al. 2022). The estimators \(\varvec{\hat{f}}(T-1)\) can be found recursively and then summed to estimate the prevalence at time step \(T-1\):
where the vector addition is computed element-wise and \(\varvec{\hat{q}}(T-1) = [\hat{q}_I(T-1), \hat{q}_V(T-1)]^T\). Then \(\hat{q}_N(T-1) = 1 - \hat{q}_I(T-1) - \hat{q}_V(T-1)\). Note that it may be easiest to fix the partition \(\{D_1, D_2, D_3\}\) to compute each \(\hat{\varvec{f}}(T-1)\) in the same manner. See Appendix A for a proof of the unbiasedness of the prevalence estimators, which follows from the fact that \(\hat{Q}_j(\tau )\) is a Monte Carlo estimator of \(Q_j(\tau )\).
4 Markov Chain Approach
To begin this section, we reiterate that disallowing reinfection or revaccination significantly simplifies the task of finding \(I(\varvec{r}, T)\) and \(V(\varvec{r}, T)\) to a straightforward combination of our prior work (Bedekar et al. 2022; Luke et al. 2023), as given by Eqs. (4) and (5). To then apply the method, one is left with a modeling exercise to construct \(R(\varvec{r}, t)\) and \(W(\varvec{r},t)\) for the personal timeline antibody responses. However, if we allow reinfection and/or revaccination, the possible ways to arrive at an antibody level \(\varvec{r}\) at time step T expand significantly, and a system that can track trajectories of infection and vaccination history becomes necessary. As an extreme example of the complexity, such a framework must be able to handle the situation in which at each next opportunity, an individual alternates between being infected and vaccinated, or repeats the same event over and over (Kocher et al. 2024). Clearly, the corresponding models for \(I(\varvec{r}, T)\) and \(V(\varvec{r}, T)\) are not simple constructions, as they must take all possible trajectories–the collectively exhaustive set of events of interest–into account. This section revisits the problem of no reinfection, no revaccination through a different lens, with an eye towards the setting in which reinfection, revaccination, and movement between the two classes is allowed.
A generalization of the conditional probability models \(I(\varvec{r}, T)\) and \(V(\varvec{r}, T)\) from Sect. 3.1 depends on transitions into infection or vaccination states, as these affect antibody level. Thus, the models should depend on a weighted sum of all potential transitions, which can be represented via a transition matrix. The population-level antibody response over time can thus be formulated in terms of the transition probabilities weighted by personal antibody response evolution. Given a current class and time t in personal timeline, one can compute the transition probability for the next time step. This motivates using a discrete-time Markov chain framework, because only the current state (N, I, V) and conditions \((\varvec{r}, t, T)\) affect the next state. To consider the event of infection separately from previous infection, we partition class I from Sect. 3.1 into two states representing new infections (\( \mathcal {I}\)) and previous infections (\(\mathcal {I}'\)). Similarly, we partition V into \(\mathcal {V}\) and \(\mathcal {V}'\).
4.1 Transition Probabilities
A transition matrix S defines the probabilities of moving between states. Here, S(i, j) is the probability of moving to state i from state j, where the ordering is \(N, \mathcal {I}', \mathcal {I}, \mathcal {V}', \mathcal {V}\). Let \(T =0\) index the emergence of a disease. We assume that our initial state vector is \(X_{-1} = \varvec{e}_1\) to model the disease emergence, so that everyone is in state N with probability 1 on the day before the disease emerges. Here, \(\varvec{e}_1\) is the first unit vectorFootnote 2. Let \(X_j\) denote the state, or class, at time step j. We disallow transition from \(\mathcal {I}'\) or \(\mathcal {V}'\) back to N, which is reasonable for a time scale on the order of several months. Denote the transition probabilities by s.

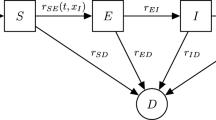
Graph describing the allowable movements between states. Here, N is naïve, \(\mathcal {I}\) is newly infected, \(\mathcal {I}'\) is previously infected, \(\mathcal {V}\) is newly vaccinated, and \(\mathcal {V}'\) is previously vaccinated. Double subscripts on s denote the transition probability from the second state to the first
We employ a graph to represent our framework, in which each state or class is a node and transitions between classes are directed, weighted edges; see Fig. 1. We let \(s_N(T)\) denote the weight of the degenerate edge to N from N, or the probability of staying naïve. The probabilities \(s_{\mathcal {I}N}(T)\) and \(s_{\mathcal {V}N}(T)\) weight the edges to \(\mathcal {I}\) from N and to \(\mathcal {V}\) from N, indicating infection or vaccination, respectively. Since we forbid reinfection or revaccination, one moves to \(\mathcal {I}'\) from \(\mathcal {I}\) or to \(\mathcal {V}'\) from \(\mathcal {V}\) on the next time step with probability 1. Once in \(\mathcal {I}'\) or \(\mathcal {V}'\), one remains there with probability 1 and mounts their antibody response.
By definition, the transition probabilities depend on \(f_I(T)\) and \(f_V(T)\), the fractions of the population that are infected and vaccinated on time step T, respectively. At time step T, the fraction of the population becoming newly infected or vaccinated is divided by the relative size of the naïve population at the previous step to obtain the transition probability. This assumes that, of all the individuals in the naïve class on the previous time step, a percentage \(f_\mathcal {I}\) or \(f_\mathcal {V}\) move to \(\mathcal {I}\) and \(\mathcal {V}\), respectively. Thus, we have
The final relationship between the transition rates, the one defining \(s_N(T)\), is a total probability statement. Here we define \(q_N(-1) = 1\) to be consistent with our assumption that everyone is in the naïve class on the day before the disease emerges. When \(q_N(T-1) = 0\) we define \(s_{\mathcal {I}N}(T)\) and \(s_{\mathcal {V}N}(T)\) to be zero, as there are no individuals remaining in the N class, so transitions out of that class are impossible.
We note a difference between the transition probabilities and the quantity f(t)/q(T) in Bedekar et al. (2022) as well as in Eqs. (4) and (5). In the context of these probabilistic models, this ratio f(t)/q(T) is the proportion of those who became infected on time step t of the disease emergence (\(t<T\)) out of the entire previously infected population as of time step T, and it is used to write out the total probability equation for time step T. In contrast, the transition probabilities \(s_{\mathcal {I}N}(T)\) and \(s_{\mathcal {V}N}(T)\) denote the fraction of the population that are newly infected or vaccinated out of those available; i.e., the proportion of the population that was naïve the time step before.
The transition matrix for movement from time step \(T-1\) to time step T is thus given by
where the ordering is \(N, \mathcal {I}', \mathcal {I}, \mathcal {V}', \mathcal {V}\). As an example, we distill the probability of a person ending up in a particular class after three time steps using product of transition matrices as follows:
The interpretation of the first three entries of the resulting vector is as follows: the probability that one stays naïve through time step 3; the probability that one got infected on time step 1 and is considered previously infected on time step 2 plus the probability that one got infected on time step 2 and is considered previously infected on time step 3; and the probability that one did not get infected on time steps 1 or 2 but did get infected on time step 3. In short, we confirm that all possible trajectories to N, \(\mathcal {I}'\), and \(\mathcal {I}\) on time step 3 are considered. Parallel interpretations hold for \(\mathcal {V}'\) and \(\mathcal {V}\) as for \(\mathcal {I}'\) and \(\mathcal {I}\).
Specifically, such multi-step transitions can be represented in terms of the entries of the matrix–vector product of the subsequent transitions. A \(\tau \) step transition from time step 0 to time step \(\tau \) is represented by \(H_\tau ,\)
where \(\tau - t\) is used to ensure indexing of the product in the correct order. Thus, if everyone starts in the naïve class on time step 0, then the total probabilistic distribution of the classes after T time steps in the absolute timeline will be
4.2 Equivalence of State Probabilities and Original Framework Prevalence
Here, we continue to assume that everyone begins in the naïve class at time step zero, or that our initial state vector is \(\varvec{e}_1\). By using Eq. (27), the state probabilities are given explicitly by
The state probabilities and the prevalence in Sect. 3.2 are related; in fact, \( \textrm{Prob} (X_T = N) = q_N(T), \textrm{Prob} (X_T = \mathcal {I}') = q_I(T-1), \textrm{Prob} (X_T = \mathcal {I}) = f_I(T),\) \(\textrm{Prob} (X_T = \mathcal {V}') = q_V(T-1),\) and \( \textrm{Prob} (X_T = \mathcal {V}) = f_V(T)\), as proved below. Using the definition of the state probability and Eq. (23), we have
Using Eqs. (6) and (7) and the fact that \(q_N(0) = 1\), we then find
Using Eq. (30), we find that for \(\mathcal {I}'\),
This is expected, because the previously infected class does not include new infections occurring on time step T. Finally, using Eq. (30), for \(\mathcal {I}\) we find
One can analogously show that \(\textrm{Prob} (X_T = \mathcal {V}') = q_V(T-1)\) and \(\textrm{Prob} (X_T = \mathcal {V}) = f_V(T)\). Thus,
Since we have split the infected class of Sect. 3 into \(\mathcal {I}\) and \(\mathcal {I}'\) to represent new and old infections, we expect that \(\textrm{Prob} (X_T = \mathcal {I}') + \textrm{Prob} (X_T = \mathcal {I}) = q_I(T)\); this is in fact true, as \(q_I(T-1) + f_I(T) = q_I(T)\). This allows us to confirm the relationship between the state probabilities and the prevalence of Sect. 3.2 and that the state probabilities sum to 1, as expected.
Equations (30), (31), (32) and analogous statements for \(\mathcal {V}', \mathcal {V}\) help rewrite the \(\tau -\) step transition matrix \(H_\tau \) as follows:
where the ordering is \(N, \mathcal {I}', \mathcal {I}, \mathcal {V}', \mathcal {V}\). Notice that these transitions are as expected. However, these transition matrices do not carry over information about antibody kinetics, nor the convolution between personal and absolute timelines that leads to a given sampled antibody value from a population on a given time. We will incorporate this in the next subsection.
4.3 Conditional Probabilities in Terms of Transition Matrices and Personal Timeline Models
The set of previously infected individuals can be partitioned using the time period when they were newly infected, i.e., when they were in the transient class \(\mathcal {I}'\). Thus, using the law of total probability, the conditional probability density for an antibody measurement \(\varvec{r}\) during time step T in the absolute timeline given that the sample comes from a previously infected individual is
This summand consists of people who were naïve through time period \(t-1\), become newly infected in time period t, and stay in the previously infected class thereafter, i.e. \(NN\cdots N \mathcal {I}\mathcal {I}'\mathcal {I}'\cdots \mathcal {I}'\). For such a sequence, \(R(\varvec{r},T-t)\) is the distribution of the antibody response on time step T in the absolute timeline. Thus,
Here, angle brackets denote the (dot) inner product. In total, the conditional probability density can be rewritten as
In other words, the inner product inside the large parentheses is the prevalence of newly infected individuals on a particular time step. Thus, the sum in the last term is the inner product of responses on different time steps with the vector of newly infected prevalence. Using Eq. (28b)-(28c), we can see that this is solely in terms of the transition matrix S and the personal antibody response model R. The expression for \(\textrm{Prob} (\varvec{r}, T | X_T = \mathcal {V}')\) is analogous.
The expression for \(\textrm{Prob} (\varvec{r}, T | X_T = \mathcal {I})\) is simpler than that for \(\mathcal {I}'\) because there is only one possible sequence of state transitions: \(N N \cdots N \mathcal {I}\), where the transition from N to \(\mathcal {I}\) occurs on time step T. This sequence has antibody response distribution \(R(\varvec{r}, 0 ) = N(\varvec{r})\), and thus \(\textrm{Prob} (\varvec{r}, T | X_T = \mathcal {I}) = \textrm{Prob} (\varvec{r}, T | X_{T-1} = N, X_T = \mathcal {I}) = N(\varvec{r})\).
4.3.1 Equivalence of Measurement Density in Markov Chain and Original Frameworks
Ideas similar to Eq. (2) lead us to derive the measurement density,
Using Eqs. (28) and (37), the relationship between the state probabilities and the prevalence in Sect. 3.2, and the above discussion, after some rearranging, Eq. (38) can be written as
Here we have also used \(q_N(T-1) = q_N(T) + f_I(T) + f_V(T)\). While Eq. (39) is a different representation of the measurement density from that given by Eq. (9) in Sect. 3, by rewriting the inner products as state probabilities and using the relationship between the state probabilities and the prevalence in Sect. 3.2, one can show their equivalence:
Due to this equivalence, prevalence estimation in this Markov chain approach will follow Sect. 3.2. Then, original class I will be broken into \(\mathcal {I}\) and \(\mathcal {I}'\) so that the estimators are \(\hat{q}_{\mathcal {I}'}(T) = \sum _{t = 0}^{T-1} \hat{f}_I(t)\) and \(\hat{q}_{\mathcal {I}}(T) = \hat{f}_I(T)\) by their definitions. Similar estimators can be found for \(q_{\mathcal {V}'}(T)\) and \(q_{\mathcal {V}}(T)\).
4.4 Estimation of Transition Probability Matrices
Let us reconsider the measurement density Eq. (39), from Sect. 4.3.1. We note that it can be written in terms of the transition matrix \(H_t\) from Eq. (34) as
where \(H_{t,(k,1)}:= \langle H_t \varvec{e}_1, \varvec{e}_k\rangle .\) Integrating both sides of the equation over some subdomain \(D_j\) of the antibody measurement space leads to
Unbiased estimation of \(Q_{D_j}\) can be achieved by Monte-Carlo estimation as in Sect. 3.2: by measuring antibody levels for randomly selected samples from the population during time period T, followed by a counting of the fraction of the measurements that fall in that subdomain.
Notice that for \(T = 0,\) we have \(Q_{D_j}(0) = N_{D_j}\); this follows our assumption that every person starts naïve at \(T = -1\), the day before the disease emerges, and that antibody response does not mount immediately after infection. That is, the total probability mass is distributed exactly as the naïve distribution: this is as expected. For \(T=1\),
Let \(D_1, D_2, D_3\) partition the domain as in Eq. (10). Notice that for such a partition, as N, R(t), W(t) are probability distributions for all \(t\ge 0\),
Using Eq. (43) for \(D_1, D_2, D_3\), we can write down a system of linear equations, given by
where the term \(q_N(-1)=1\) as before due to our assumption that everyone starts naïve before the emergence of the disease. The last equation of this matrix system arises out of an application of Eq. (44), and expresses that the naïve population in the preceding time step distributes into naïve, newly infected, and newly vaccinated in the next time step.
We can thus estimate \(q_N(0), H_{0,(3,1)}, H_{0,(5,1)}\) and obtain the respective estimates \(\widehat{q_N}(0), \widehat{H}_{0,(3,1)},\) and \( \widehat{H}_{0,(5,1)}\). Via induction, for a general T we obtain the following system
Note that even though we only estimate values pertaining to the naïve, newly infected, and newly vaccinated entry in the first column, these sequential estimates determine the values for previously infected and vaccinated entries by the following recursive relation:
and similarly
This is as expected because the prevalence of previously infected/vaccinated is obtained as an accumulation of prevalence for newly infected/vaccinated over the entire absolute timeline.
5 Example Applied to SARS-CoV-2 Antibody Data
In the context of SARS-CoV-2, our models characterize the time frame around spring 2021, when individuals either had a previous infection or were receiving their first vaccination, with very few people having done both. We create synthetic training data motivated by clinical data from Abela et al. (2021) and Congrave-Wilson et al. (2022). The synthetic data are created by studying immunoglobulin G (IgG) measurements for naïve, infected, and vaccinated individuals. These values are considered together to have arbitrary units (AU) and log-transformed similarly to Patrone and Kearsley (2021), Bedekar et al. (2022), and Luke et al. (2023) to yield the unit-less, one-dimensional measurement
We use gamma distributions to model the infected and vaccinated antibody responses t days after infection or vaccination, which both change with time, and the naïve distribution. We use pre-vaccine measurements reported as SARS-CoV-2-naïve to model the naïve population with
For this synthetic dataset, \(\alpha _n = 15.1\) and \(\beta _n = 0.184\). We allow \(\alpha \) to vary in time for both the vaccinated and infected responses as
where the subscripts i and v denote infected and vaccinated. The model for the personal timeline of an infected individual is then given by
Following Bedekar et al. (2022), we require that at \(t = 0\), both the vaccinated and infected models are identical to N(r). This is enforced by our modeling; note that the shape and scale at \(t=0\) and as \(t\rightarrow \infty \) are identical to those for naïve. The model for personal timeline for vaccination, W(r, t), is given similarly to Eq. (52). The model parameters are \(\theta _{1, i} = 1.56, \theta _{2, i} = 5.1 \times 10^{-4}, \theta _{1, v} = 1.74\), and \(\theta _{2, v} = 2.8 \times 10^{-4}\). The models are shown in Figs. 2 and 3.

Log-transformed synthetic antibody measurements from the naïve population with corresponding probability model (Color Figure Online)

Log-transformed synthetic antibody measurements from the infected and vaccinated populations with corresponding probability models (Color Figure Online)
5.1 Prevalence Estimation Via Transition Probability Matrices
We conduct prevalence estimation for test data sampled from the probability models described above and through transition probability matrix estimation methods developed in Sect. 4.4. We create 1000 sets of synthetic test data for various numbers of sample points \(N_s\) to calculate the mean and standard deviation of the prevalence estimates. We discretize time into time steps of \(dt = 21\) days and use 10 time periods. This results in 210 days total, or about 7 months, which is on the order of the synthetic training data.
To mimic a wave of infections during the emergence of a disease, we assume a sinusoidal change in the infected prevalence per time period, given by
This gives the corresponding true newly plus previously infected prevalence as
We also assume a constant rate of vaccination, given by an incidence
and corresponding true newly and previously vaccinated prevalence as
Thus, the prevalence of naïve for time-period t is
These incidence rates lead to the true one-step and \(\tau \)-step transition matrices by using Eqs. (24) and (34) respectively. The \(\tau \)-step transition matrix entries are then estimated using methods detailed in Sect. 4.4, which provide us with estimates of prevalence for different classes.
The results of prevalence estimation are shown in Fig. 4. The mean prevalence estimates are shown as data points and corresponding standard deviations are shown as shaded regions in lighter colors. The mean estimates agree fairly well across the sample sizes and with the true values in both the infected and vaccinated cases. We note that for low sample sizes, such as \(N_s = 10^3\), some prevalence estimates are negative, which are infeasible. However, the standard deviation of the estimates decreases with increasing sample size as expected. We observe larger prevalence estimation standard deviations at later time periods, as expected following Bedekar et al. (2022), who noted that errors accumulate over time. For \(N_s = 10^5\), the average prevalence estimate errors across all time periods are \((17 \pm 15)\) % for infected and \((8.6 \pm 7.0)\) % for vaccinated.
The results of prevalence estimation via the methods developed in Sect. 3.2 (not shown) are essentially identical: the norms of the differences, taken across all time periods, of the means and standard deviations produced by the two methods are less than \(1.5 \times 10^{-14}\) for both I and V. This is as expected, as we have shown in Sect. 4.3.1 that the measurement densities under these two frameworks are equivalent.

Prevalence estimation via transition probability estimates using synthetic data for antibody responses. The mean over 1000 synthetic data sets is shown for various numbers of samples \(N_s\) with standard deviation confidence intervals (shown in a lighter shade of the corresponding color of \(N_s\)) over time (Color Figure Online)
6 Discussion
We have shown the equivalence of the probabilistic modeling approaches in Bedekar et al. (2022) and Luke et al. (2023) and the time-inhomogeneous Markov chain approach for the case of multiclass time-dependent effects that preclude reinfection, revaccination, or any cross-effects. Useful immediately after the introduction of vaccines, this case is restrictive for general use. The equivalence itself is a significant contribution as we anticipate that our Markov chain approach will be effective in modeling the most general case. As a very promising result, prevalence estimation via transition probability matrices is identical in expectation to that of the multiclass extension of the existing time-dependent framework (Sect. 3); the former can reliably be used as we address the most general version of the problem.
6.1 More on Prevalence Estimation
We begin with a few comments on prevalence estimation. In Sect. 3.1, we noted how we discretize time in time steps of dt days to follow batched reporting trends. Daily measurements are rarely available and testing delays occur; using a larger value of dt provides less detailed information, but results in better prevalence estimates when data are sparse (Bedekar et al. 2022). We also note that for prevalence estimation via transition probability matrices, the system given by Eq. (45) is invertible provided the choice of time step dt and subdomain partition is such that \(R_{D_j}(1), W_{D_j}(1), \text { and } N_{D_j}\) are well separated from each other. This ensures that the antibody response of infected or vaccinated individuals is separable from that of naïve population. Further, a careful selection of subdomains \(D_j\) as guided by Patrone and Kearsley (2024), Luke et al. (2023), and Bedekar et al. (2022) can help the estimation by minimizing numerical errors.
We now revisit prevalence estimation via transition probability matrices after observing the large errors and standard deviations in our example shown in Fig. 4. A known issue in prevalence estimation and classification is overlap of class data (Luke et al. 2023). By plotting the probability models at one time step (21 days) in Fig. 5a, we note that the previously infected and vaccinated distributions exhibit significant overlap. As an exercise, we artificially create populations that exhibit more separation at the first time step using similar gamma distributionsFootnote 3, as shown at time step 1 in Fig. 5b. We conduct prevalence estimation via transition probability matrices for test data sampled from these distributions and display the results in Fig. 6. As before, prevalence estimation using the methods developed in Sect. 3.2 yields essentially identical results due to the equivalence in measurement densities, as proven in Sect. 4.3.1.

Note that a smaller number of samples, \(N_s = 10^2\), is shown in Fig. 6 as compared to Fig. 4, and there are no negative prevalence estimates observed by using \(N_s = 10^4\). Further, by using \(N_s = 10^4\) samples, we are able to achieve average prevalence estimate errors across all time periods of \((5.6 \pm 4.6)\) % for infected and \((3.6 \pm 2.8)\) % for vaccinated, which is significantly better than the errors shown in Fig. 4 for \(N_s = 10^5\). Using \(N_s = 10^5\) for these better separated populations improves our errors to \((1.9 \pm 1.5)\) % for infected and \((1.2 \pm 0.9)\) % for vaccinated.

Prevalence estimation via transition probability estimates using synthetic data for antibody responses. The mean over 1000 synthetic data sets is shown for various numbers of samples \(N_s\) with standard deviation confidence intervals (shown in a lighter shade of the corresponding color of \(N_s\)) over time (Color Figure Online)
How many sample points are needed from the population at each time step might vary based on how separated the populations are, which can change over time. The importance of sampling may depend on the disease in question, which determines how separated the populations are naturally. We investigate the degree of separation over time of the distributions from the above example using the overlap metric defined by Weitzman (1970) as the shared area under two probability densities:
We compare the pairwise overlap over time in Fig. 7. The overlapping infected and vaccinated distributions (Fig. 5a) agree on two-thirds of their underlying area at time step 1, whereas the artificially separated distributions have 3 % agreement at the same time. Interestingly, at time step 10 there is greater overlap of the infected and vaccinated populations for the artificially separated data; this suggests that separability is crucial in the early time steps due to the accumulation of errors. Schmid and Schmidt (2006) provide nonparametric estimators for the coefficient of overlap that could provide insight into the expected difficulty of prevalence estimation given sample populations with high levels of similarity. In future work, ideas from these authors could be extended to identify the number of samples needed to perform prevalence estimation with low variance.

Measure of overlap of the antibody responses over time for the models that generated Fig. 5 (Color Figure Online)
For this synthetic example, we have demonstrated that better separation of populations in the first few time steps can result in more accurate prevalence estimation. We now discuss how to separate real data. First and foremost, if additional measurements per person are available, such as values for other protein markers, one can visualize the data in higher dimensions, thereby inducing separation (see e.g., Luke et al. 2023). If additional measurements are not available, there are ways to embed the data into a higher dimension, such as basis expansion from the field of kernel methods (Hastie et al. 2009). Metrics like the silhouette coefficient for data and the KL-divergence for distributions indicate a similarity score between populations, which we expect can determine if the populations are separated “enough” to conduct prevalence estimation. One can also borrow the idea of a holdout domain from Patrone et al. (2022) to exclude highly overlapped data from the prevalence estimation. Instead of a multiclass prevalence estimation, a two level binary procedure can be conducted: first to estimate the relative sizes of the naïve and not-naïve populations, and then another to separate the previously infected and vaccinated classes. For the secondary step, holdout analysis or other separation methods can be applied as needed. Finally, one can compute an altered estimate \(\hat{\varvec{Q}}\) by summing indicator functions weighted inversely proportional to the overlap of the populations. This may lose the desirable property of unbiasedness, but we expect this to be overlooked in favor of reasonable prevalence estimates.
6.2 Relationship to Susceptible–Infected–Recovered Models
Our approach is superior to an SIR framework, which can model disease transmission but cannot track the distribution of antibody response of a population across time. In contrast, we provide such probabilistic information as well as a prevalence estimation scheme that is independent of classification. However, there are connections between the two approaches. Probabilistic descriptions of SIR models exist, including Markov chain formulations (e.g., Liao et al. 2005; Cortés et al. 2020; El Hajji et al. 2021). Within-host SIR-like deterministic versions explicitly account for antibody densities and viral load as variables (Hancioglu et al. 2007). Our naïve state may be a proxy for the susceptible compartment, with a population-level equivalence of these two categories. We noted in Sect. 3.1 that unlike an SIR model, we have no recovered class; this leads to an interesting question. It is unclear how to mathematically describe the process by which someone becomes naïve after previous infection or vaccination. Our current framework assumes equivalence in the limit of time, but for a seasonal disease, there should be a nonzero probability of returning to N in finite time. We speculate that the naïve state is a recurrent state in finite time for the Markov chain model that allows transition back to naïve state.
6.3 Limitations and Extensions
The choice of the form of the naïve model and shape functions for the infected and vaccinated populations are subjective choices (Smith 2013), but the influence of this issue is lessened as more sample points are used (Schwartz 1967). A family of models may be proposed and the one selected with minimal error on a measure of interest (Patrone and Kearsley 2024), such as prevalence estimates. As in our previous works, we have noted that the overlap of populations increases prevalence estimation error; we have provided potential solutions in Sect. 6.1. Additionally, Bedekar et al. (2022) first noted that prevalence estimation errors accumulate over time; our current scheme does not address controlling such errors.
Perhaps the largest drawbacks to our current approach are the simplifying assumptions we make to construct the groundwork for a multiclass time-dependent framework. For long-term analysis of disease emergence effects, multiple events must be allowed. In future work, we will relax the assumption that reinfection, revaccination, and infection after vaccination or vice versa do not occur. Mathematically, this involves a graph with higher connectivity, with edges connecting \(\mathcal {I}'\) to \(\mathcal {V}\), \(\mathcal {I}'\) to \(\mathcal {I}\), and so on. The many facets of the most general problem make tracking the immune response difficult, but we must consider such cases, because reinfections and revaccinations are the norm as a newly emergent disease becomes endemic. There is little biological understanding of interactions between such events and precious few models, as the antibody kinetics are still being studied. Modeling how these effects build on each other in terms of immune response is a complex question.
However, there are some guiding principles about immune memory from which to start building additive, probabilistic multi-event personal response models. Extreme sequences of events, such as an individual becoming newly infected every day, should be assigned very low probabilities due to the underlying biology. Further, despite the multitude of potential sequences of events leading to an antibody response and current state on a particular time step, the likelihood of infection or vaccination on the next time step depends solely on the current state information. Additionally, the multi-step transition probability matrix in the current Markov chain framework is considerably more structured than can be expected from the more general model. As a result, the estimation methods will need to be revised. These and other considerations inform our ongoing work to form a general model that can tackle real-life scenarios. As a first attempt at addressing such complexities, we are currently studying the setting in which we allow reinfection and revaccination, but simplify to a time-homogeneous Markov chain, which makes the calculation of desired quantities such as state probabilities more tractable. We will use this setting to inform the extension to the more complex time-inhomogeneous Markov chain.
There are significant data-related challenges that should be addressed in future work. One is simply a lack of temporal data, which affects the modeling process and prevalence estimation. Access to temporal random testing data from public health institutes can be used to verify the estimates by our models. Even when data are available, it can poorly represent the progression of an emerging disease through a population as truly random testing is not realistic. In the case of SARS-CoV-2, it is well known that people tested less frequently as the pandemic progressed, false negative tests occurred, and people often did not recognize mild or asymptomatic cases as infections. Furthermore, other confounders might cause skewed estimations of prevalence (Binder et al. 2024). Uncertainty quantification could address the deterioration of accuracy and precision of collected antibody data since the start of the pandemic. Prevalence estimation is a data-dependent analysis, which begins by estimating the incidence of new infections and vaccinations. Vaccination incidence rates may be well-documented for a population if de-identified medical data are available, but new infection case rates are prone to missing responses and errors due to the inexactness of days post symptom onset (DPSO) as an infection marker. Moreover, DPSO may often underestimate the true time since the beginning of infection. Future work could include the design of a prevalence estimation method that does not require knowing incidence information at the very emergence of a disease, with which we could verify our work using real incidence rates from a time period after all three of caseload numbers, vaccination rates, and antibody measurements are available. We note that immunocompromised individuals affect prevalence estimation and the modeling exercise. Future work could address the propagation of error by separating the population by immune system status, and correct errors due to reporting bias or gaps. We could also consider inflammatory markers as candidate variables, which have been studied in the context of severity of diseases such as the coronavirus disease of 2019 (COVID-19) (Zeng et al. 2020), but may not be fully understood in connection with sequences of immune response events.
6.4 Implications for Immunologists
We have created a cohesive framework for the multiclass time-dependent problem of the emergence of a disease, so that unbiased predictions of the relative fractions of naïve, infected, and vaccinated individuals can be generated over time. Although we use SARS-CoV-2 as a motivating example, this approach is fully generalizable to other diseases for which immunity is lost on the time frame of months or a few years. In particular, the models follow biological assumptions that can be adapted or narrowed to focus on populations of interest, such as children, the elderly, or the immunocompromised. Our methods are limited by data availability; we recommend implementing longitudinal studies that continue to record infections with high granularity even as vaccines are deployed. As assay standardization is not fully achieved, such studies should use the same data collection methods, instruments, and protocol to facilitate the comparison of measurements across large periods of time.
Notes
Certain commercial equipment, instruments, software, or material are identified in this paper in order to specify the experimental procedure adequately. Such identification is not intended to imply recommendation or endorsement by the National Institute of Standards and Technology, nor is it intended to imply that the materials or equipment identified are necessarily the best available for the purpose.
This assumption holds for an emergent disease; we would expect almost none of the population to be in the naïve state in the case of an endemic virus such as the common cold.
The model parameters are \(\alpha _n = 17.6, \beta _n = 0.123\), \(\theta _{1, i} = 2.23, \theta _{2, i} = 5.3 \times 10^{-4}, \theta _{1, v} = 4.23\), and \(\theta _{2, v} = 5.3 \times 10^{-4}\).
References
Abela IA, Pasin C, Schwarzmüller M, Epp S, Sickmann ME, Schanz MM, Rusert P, Weber J, Schmutz S, Audigé A et al (2021) Multifactorial seroprofiling dissects the contribution of pre-existing human coronaviruses responses to SARS-CoV-2 immunity. Nat Commun 12(1):1–18
Böttcher L, D’Orsogna MR, Chou T (2022) A statistical model of COVID-19 testing in populations: effects of sampling bias and testing errors. Philos Trans R Soc A 380(2214):20210121
Borremans B, Gamble A, Prager K, Helman SK, McClain AM, Cox C, Savage V, Lloyd-Smith JO (2020) Quantifying antibody kinetics and RNA detection during early-phase SARS-CoV-2 infection by time since symptom onset. Elife 9:60122
Bedekar P, Kearsley AJ, Patrone PN (2022) Prevalence estimation and optimal classification methods to account for time dependence in antibody levels. J Theor Biol 559:111375
Binder RA, Matta AM, Forconi CS, Oduor CI, Bedekar P, Patrone PN, Kearsley AJ, Odwar B, Batista J, Forrester SN et al (2024) Minding the margins: Evaluating the impact of covid-19 among latinx and black communities with optimal qualitative serological assessment tools. Plos one 19(7):0307568
Bajema KL, Wiegand RE, Cuffe K, Patel SV, Iachan R, Lim T, Lee A, Moyse D, Havers FP, Harding L et al (2021) Estimated SARS-CoV-2 seroprevalence in the US as of September 2020. JAMA Int Med 181(4):450–460
Bouter L, Zeegers M, Li T (2023) Textbook of epidemiology. Wiley, West Sussex, p 10
Caini S, Bellerba F, Corso F, Díaz-Basabe A, Natoli G, Paget J, Facciotti F, De Angelis SP, Raimondi S, Palli D et al (2020) Meta-analysis of diagnostic performance of serological tests for SARS-CoV-2 antibodies up to 25 April 2020 and public health implications. Eurosurveillance 25(23):2000980
Cortés J-C, El-Labany S, Navarro-Quiles A, Selim MM, Slama H (2020) A comprehensive probabilistic analysis of approximate SIR-type epidemiological models via full randomized discrete-time Markov chain formulation with applications. Math Meth Appl Sci 43(14):8204–8222
Congrave-Wilson Z, Cheng WA, Lee Y, Perez S, Turner L, Marentes Ruiz CJ, Mendieta S, Skura A, Jumarang J, Del Valle J et al (2022) Twelve-month longitudinal serology in SARS-CoV-2 naïve and experienced vaccine recipients and unvaccinated COVID-19-infected individuals. Vaccines 10(5):813
D’Arienzo M, Coniglio A (2020) Assessment of the SARS-CoV-2 basic reproduction number, R0, based on the early phase of COVID-19 outbreak in Italy. Biosaf Health 2(2):57–59
dePillis L, Caffrey R, Chen G, Dela MD, Eldevik L, McConnell J, Shabahang S, Varvel SA (2023) A mathematical model of the within-host kinetics of SARS-CoV-2 neutralizing antibodies following COVID-19 vaccination. J Theor Biol 556:111280
Dick DW, Childs L, Feng Z, Li J, Röst G, Buckeridge DL, Ogden NH, Heffernan JM (2021) COVID-19 seroprevalence in Canada modelling waning and boosting COVID-19 immunity in Canada a Canadian immunization research network study. Vaccines 10(1):17
Diep AN, Schyns J, Gourzonès C, Goffin E, Papadopoulos I, Moges S, Minner F, Ek O, Bonhomme G, Paridans M et al (2023) How do successive vaccinations and SARS-CoV-2 infections impact humoral immunity dynamics: an 18-month longitudinal study. J Infect 88(2):183–186
El Hajji M, Sayari S, Zaghdani A (2021) Mathematical analysis of an SIR epidemic model in a continuous reactor-deterministic and probabilistic approaches. J Korean Math Soc 58(1):45–67
Guo L, Zhang Q, Gu X, Ren L, Huang T, Li Y, Zhang H, Liu Y, Zhong J, Wang X et al (2023) Durability and cross-reactive immune memory to SARS-CoV-2 in individuals 2 years after recovery from COVID-19: a longitudinal cohort study. Lancet Microbe 5(1):24–33
Hay JA, Laurie K, White M, Riley S (2019) Characterising antibody kinetics from multiple influenza infection and vaccination events in ferrets. PLoS Comput Biol 15(8):1007294
Hancioglu B, Swigon D, Clermont G (2007) A dynamical model of human immune response to influenza a virus infection. J Theor Biol 246(1):70–86
Hastie T, Tibshirani R, Friedman JH, Friedman JH (2009) The elements of statistical learning: data mining, inference, and prediction, vol 2. Springer, New York, p 10
Hernandez-Vargas EA, Velasco-Hernandez JX (2020) In-host mathematical modelling of COVID-19 in humans. Ann Rev Control 50:448–456
Kocher K, Moosmann C, Drost F, Schülein C, Irrgang P, Steininger P, Zhong J, Träger J, Spriewald B, Bock C, et al (2024) Adaptive immune responses are larger and functionally preserved in a hypervaccinated individual. Lancet Infect Dis, 1473–3099
Liao C-M, Chang C-F, Liang H-M (2005) A probabilistic transmission dynamic model to assess indoor airborne infection risks. Risk Anal 25(5):1097–1107
Luke RA, Kearsley AJ, Patrone PN (2023) Optimal classification and generalized prevalence estimates for diagnostic settings with more than two classes. Math Biosci 358:108982
Luke RA, Kearsley AJ, Pisanic N, Manabe YC, Thomas DL, Patrone PN (2023) Modeling in higher dimensions to improve diagnostic testing accuracy: theory and examples for multiplex saliva-based SARS-CoV-2 antibody assays. PLOS One 18(3):0280823
Liu X, Munro AP, Wright A, Feng S, Janani L, Aley PK, Babbage G, Baker J, Baxter D, Bawa T et al (2023) Persistence of immune responses after heterologous and homologous third COVID-19 vaccine dose schedules in the UK: eight-month analyses of the COV-BOOST trial. J Infect 87(1):18–26
McMahon A, Robb NC et al (2020) Reinfection with SARS-CoV-2: discrete SIR (susceptible, infected, recovered) modeling using empirical infection data. JMIR Public Health Surveill 6(4):21168
Osborne K, Gay N, Hesketh L, Morgan-Capner P, Miller E (2000) Ten years of serological surveillance in England and Wales: methods, results, implications and action. Int J Epidemiol 29(2):362–368
Patrone PN, Bedekar P, Pisanic N, Manabe YC, Thomas DL, Heaney CD, Kearsley AJ (2022) Optimal decision theory for diagnostic testing: minimizing indeterminate classes with applications to saliva-based SARS-CoV-2 antibody assays. Math Biosci 351:108858. https://doi.org/10.1016/j.mbs.2022.108858
Patrone PN, Kearsley AJ (2021) Classification under uncertainty: data analysis for diagnostic antibody testing. Math Med Biol 38(3):396–416
Patrone PN, Kearsley AJ (2024) Minimizing uncertainty in prevalence estimates. Stat Prob Lett 205:109946
Pollán M, Pérez-Gómez B, Pastor-Barriuso R, Oteo J, Hernán MA, Pérez-Olmeda M, Sanmartín JL, Fernández-García A, Cruz I, Larrea NF et al (2020) Prevalence of SARS-CoV-2 in Spain (ENE-COVID): a nationwide, population-based seroepidemiological study. Lancet 396(10250):535–544
Peeling RW, Wedderburn CJ, Garcia PJ, Boeras D, Fongwen N, Nkengasong J, Sall A, Tanuri A, Heymann DL (2020) Serology testing in the COVID-19 pandemic response. Lancet Infect Dis 20(9):245–249
Quick C, Dey R, Lin X (2021) Regression models for understanding COVID-19 epidemic dynamics with incomplete data. J Am Stat Assoc 116(536):1561–1577
Roberto Telles C, Lopes H, Franco D (2021) SARS-COV-2: SIR model limitations and predictive constraints. Symmetry 13(4):676
Schwartz SC (1967) Estimation of probability density by an orthogonal series. Ann Math Stat 38(4):1261–1265
Smith RC (2013) Uncertainty quantification: theory, implementation, and applications, vol 12. SIAM, Philadelphia
Schmid F, Schmidt A (2006) Nonparametric estimation of the coefficient of overlapping-theory and empirical application. Comp Stat Data Anal 50(6):1583–1596
Weitzman MS (1970) Measures of overlap of income distributions of white and negro families in the United States, vol 22. US Bureau of the Census, Washington, D.C
Wodarz D (2005) Mathematical models of immune effector responses to viral infections: Virus control versus the development of pathology. J Comp Appl Math 184(1):301–319
Xu Z, Wei D, Zhang H, Demongeot J (2023) A novel mathematical model that predicts the protection time of SARS-CoV-2 antibodies. Viruses 15(2):586
Zeng F, Huang Y, Guo Y, Yin M, Chen X, Xiao L, Deng G (2020) Association of inflammatory markers with the severity of COVID-19: a meta-analysis. Int J Infect Dis 96:467–474
Acknowledgements
This work is a contribution of the National Institute of Standards and Technology, USA and is not subject to copyright in the United States. P.B. was funded through the NIST PREP, USA grant 70NANB18H162. R.L. is grateful for generous support during the early days of the research from a National Research Council postdoctoral fellowship at NIST and a NIST PREP fellowship (same grant number as P.B.). The aforementioned funders had no role in study design, data analysis, decision to publish, or preparation of the manuscript. The authors are grateful to Pia Pannaraj and Yesun Lee for helpful discussion regarding post-infection or vaccination antibody kinetics. The authors also wish to thank Melinda Kleczynski and Amanda Pertzborn for useful feedback during preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
Prajakta Bedekar: Conceptualization, Data curation, Formal analysis, Methodology, Software, Validation, Visualization, Writing–original draft, Writing–review & editing. Rayanne A. Luke: Conceptualization, Data curation, Formal analysis, Methodology, Software, Validation, Visualization, Writing–original draft, Writing–review & editing. Anthony J. Kearsley: Conceptualization, Methodology, Supervision, Writing–review & editing.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Unbiasedness of the Prevalence Estimators
A straightforward extension of the ideas in Bedekar et al. (2022) shows that the prevalence estimates presented in Sect. 3.2 are unbiased. In what follows we continue to use element-wise vector addition to simplify our notation. First, it is clear that \(\hat{\varvec{Q}}(T)\) is unbiased because each component is a Monte Carlo estimator and therefore
which implies
Next, we find that
and using the previous result we conclude that \(E \left[ \hat{\varvec{f}}(0) \right] = \varvec{f}(0)\). Then, via induction, we find that
Finally, we find that
Unbiasedness of Transition Probability Estimation
The proof of the unbiasedness of the transition probability matrix entries can be obtained easily by using similar techniques as in Appendix A. We use linearity of expectation of the product of a deterministic matrix and a random vector on Eq. (45) to obtain
Using the unbiasedness of the Monte Carlo estimates as shown in Eqs. (A1) and (45) again, we get
These calculations are easily generalized by using the principle of strong induction and Eqs. (46), (A1), and (B2), to obtain
The estimates for the other entries of the transition probability matrix are also unbiased. Using Eqs. (47) and (48) we see that
and
Optimal Classification
Optimal classification can be performed to yield class domains that vary over time. Since the antibody kinetics of states N and \(\mathcal {I}\) share the same distribution, newly infected individuals cannot be distinguished from those naïve to the disease. This reflects the known delay in antibody response after infection (Borremans et al. 2020). Thus, antibody measurements are classified as belonging to one of N, \(\mathcal {I}'\), or \(\mathcal {V}'\).
We combine the ideas in Bedekar et al. (2022) and Luke et al. (2023) to construct the optimal classification domains that minimize a loss function. We seek to define a sequence of partitions \(\{D_N(T), D_{\mathcal {I}'}(T), D_{\mathcal {V}'}(T)\}\), not necessarily the same as any partition used for prevalence estimation, so that at any time T, a measurement is assigned to one and only one class, i.e., N if \(\varvec{r} \in D_N(T)\), and similarly for \(D_{\mathcal {I}'}(T)\) and \(D_{\mathcal {V}'}(T)\). To ensure any sample can be classified and to enforce single-label classification up to sets of measure zero, we require, for any T, that
Here, \(\cup _D = D_N(T) \cup D_{\mathcal {I}'}(T) \cup D_{\mathcal {V}'}(T)\), the subscripts L and K can represent any of \(N, \mathcal {I}'\), or \(\mathcal {V}'\), and \(\mu _N(X) = \int _X N(\varvec{r}) d \varvec{r}\), \(\mu _{\mathcal {I}'}(X) = \int _X \mathcal {I}'(\varvec{r}, T) d \varvec{r}\), and \(\mu _{\mathcal {V}'}(X) = \int _X \mathcal {V}'(\varvec{r}, T) d \varvec{r}\).
Next, define the prevalence-weighted rate of misclassification at time T:
One expects that a sample \(\varvec{r}\) should be assigned to the class to which it has the highest probability of belonging on time step T; that is, \(\max \{ q_N(T) N(\varvec{r}), q_{\mathcal {I}'}(T) \mathcal {I}'(\varvec{r}, T), q_{\mathcal {V}'}(T) \mathcal {V}'(\varvec{r}, T) \}\). It turns out that our intuition is correct. The authors in Luke et al. (2023) showed that for a single time T, the optimal classification domains are given by
This assumes a technical detail that all “boundary” cases, i.e., measurements \(\varvec{r}\) such that there is an equal highest probability of belonging to two or more classes, have measure zero. Since this is often true for any practical implementation, we will assume this going forward. Also note that the use of a superscript \(\star \) denotes an optimal quantity, in this case, an optimal classification domain.
A logical loss function is then the sum of these rates over all time steps of the emergence of the disease:
where each of \(D_N(T), D_{\mathcal {I}'}(T), D_{\mathcal {V}'}(T)\) obey the rules given by Eqs. (C1)-(C2) and \(\varvec{D}_{\varvec{N}}\) is a vector whose ith entry is \(D_N(i)\). The vectors \(\varvec{D}_{\varvec{\mathcal {I}'}}\) and \(\varvec{D}_{\varvec{\mathcal {V}'}}\) are defined analogously. A straightforward application of the ideas in Bedekar et al. (2022) shows us that the loss function (C5) is minimized by taking the pointwise-optimal domains at each time step T given by Eq. (C4). Thus, the optimal classification domains are given by the vectors
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bedekar, P., Luke, R.A. & Kearsley, A.J. Prevalence Estimation Methods for Time-Dependent Antibody Kinetics of Infected and Vaccinated Individuals: A Markov Chain Approach. Bull Math Biol 87, 26 (2025). https://doi.org/10.1007/s11538-024-01402-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11538-024-01402-0