
Abstract
Expanding in vitro fertilization (IVF) access requires improved patient counseling and affordability via cost-success transparency. Clinicians ask how two types of live birth prediction (LBP) models perform: machine learning, center-specific (MLCS) models and the multicenter, US national registry-based model produced by Society for Assisted Reproductive Technology (SART). In a retrospective model validation study, we tested whether MLCS performs better than SART using 4635 patients’ first-IVF cycle data from 6 centers. MLCS significantly improved minimization of false positives and negatives overall (precision recall area-under-the-curve) and at the 50% LBP threshold (F1 score) compared to SART (p < 0.05). To contextualize, MLCS more appropriately assigned 23% and 11% of all patients to LBP ≥ 50% and LBP ≥ 75% whereas SART gave lower LBPs. Here, we show MLCS improves model metrics relevant for clinical utility – personalizing prognostic counseling and cost-success transparency – and is externally validated. We recommend evaluating MLCS in a larger sample of fertility centers.
Similar content being viewed by others

Introduction
Infertility, declared a medical disease and global health issue by the World Health Organization (WHO), is estimated to affect over 100 M women or couples globally and over 10 M in the US1,2,3,4,5,6,7,8,9,10,11,12,13,14. Despite the proven safety and efficacy of in vitro fertilization (IVF, used generically with assisted reproductive technology, ART), patients’ access to IVF continues to be limited by cost and emotional stress, compounded by uncertainty in live birth outcomes. These barriers contribute to an estimated overall ART utilization of 5% among couples in need and discontinuation rates of 10–50%5,6,7,14,15. Therefore, providers have an important responsibility to offer validated, personalized and relevant prognostic counseling to educate patients about the potential benefits and limitations of IVF, especially since the cost of having an IVF baby depends heavily on each patient’s own IVF live birth prognosis over 1, 2, and 3 IVF cycles7,16,17. In other words, IVF cost-to-live birth transparency can be used by patients and providers to support a very personal decision in addressing a medical and/or family-building need.
Artificial intelligence (AI)/ machine learning (ML) has been used to support IVF pretreatment prognostic counseling efforts. ML center-specific (MLCS) IVF live birth prediction models have been in clinical usage for nearly 10 years and has been reported to be associated with a two to threefold increase in IVF utilization rates among new patients proactively seeking care across unrelated fertility centers in US and Canada18. We previously reported the development and clinical usage of MLCS IVF prognostic models to support provider-patient counseling across geographies (e.g., US, Canada, UK and EU) which varied in IVF payers including patients themselves, employers, health insurance plans and government7,18,19,20,21,22,23,24. Geographically distributed, local delivery of fertility care helps to remove barriers in patient-centric care. However, patients’ clinical characteristics have been shown to vary significantly across fertility centers and those inter-center variations were associated with differential IVF live birth outcomes25. Therefore, patient-centric care includes prognostic counseling relevant and reflective of clinical characteristics of the local patient population. Further, validation of MLCS IVF pretreatment models using separate test sets have been reported and the design, validation and clinical usage considerations for IVF pretreatment prognostic model has been reviewed in-depth7,19,20,24,26,27,28.
Nonetheless, there is a widely held perception among providers and researchers that the national registry-based, center-agnostic IVF pretreatment prognostics model developed by the US Society for Assisted Reproductive Technology (SART model) “suffices” based on its usage of a large national dataset from 121,561 IVF cycles started in a two-year period (2014–2015) even though model validation using an external test set and clinical utilization studies have not been reported29,30. Further, SART researchers recommended fertility centers in countries outside of the US and UK to develop localized prognostic models by recalibrating the US SART and UK Human Fertilisation and Embryology Authority (HFEA) models, trained from US and UK national data29,31,32. However, Cai et al. reported that model validation metrics of a de novo MLCS model trained using only local data from a hospital in China were superior to recalibration of the US SART or UK HFEA models26,29,31,32.
The above body of work led providers to ask (1) whether and how MLCS and SART model predictions differ for patients seeking fertility care in the US today, and (2) whether MLCS models are applicable to small-to-midsize US fertility centers. Indeed, a head-to-head comparison between the MLCS and SART pretreatment models for individual US centers has not been conducted. Providers also want to know if the MLCS model, validated prior to clinical usage, continued to be clinically applicable to patients receiving IVF counseling after model deployment.
This retrospective cohort study aimed to compare the performance of the MLCS and SART pretreatment models for six unrelated small-to-midsize US fertility centers operating in 22 locations across 9 states in 4 US regions (West, Southeast, Southwest and Midwest) using center-specific test sets comprising an aggregate of 4635 patients’ first-IVF cycle data meeting SART model usage criteria. We hypothesized that the MLCS approach to training and validating models would provide improved IVF live birth predictions (LBP) compared to SART model. We tested this hypothesis by evaluating MLCS and SART models using model metrics such as area-under-the-curve (AUC) of the receiver operating characteristic curve (ROC-AUC) for discrimination; posterior log of odds ratio compared to Age model (PLORA); Brier score for calibration; precision-recall AUC (PR-AUC) and F1 score for minimization of false positives and false negatives for the overall model and at specific LBP thresholds, respectively24,33,34,35,36,37,38. We also provided a 4 × 4 reclassification table to contextualize model improvement implications for clinical and operational usage impacting patients and providers.
In compliance with the TRIPOD + AI statement and EQUATOR guidelines for scientific publishing, we reported results unrelated to the comparison of MLCS and SART models, including each center’s model performance as measured by ROC-AUC, ROC-AUC comparison against its Age model and PLORA, summary statistics of the original data sets and methods used to develop and validate MLCS models for clinical usage39,40. We provided further clinical utility insights by performing live model validation (LMV), where we tested whether MLCS models externally validated using out-of-time test sets made up of patients who received IVF counseling contemporaneous with clinical model usage. Failure of external validation or LMV, indicated by finding significant difference in the ROC-AUC and PLORA endpoints, would suggest that changes in patient populations (an example of data drift) and/or the predictive relationships between clinical predictors and live birth probabilities (an example of concept drift) have caused the models not to be applicable anymore41,42. (https://towardsdatascience.com/why-isnt-out-of-time-validation-more-ubiquitous-7397098c4ab6) Addressing the above questions will help us to develop best practices for IVF live birth prognostic counseling, which is critical for advancing fertility care in the US and globally.
Results
Model cross-validation and external validation
Six centers participated in this study. For each center, an initial, version 1 MLCS model (MLCS1) and an updated, version 2 MLCS model (MLCS2) were created. Table 1 shows for each model validation, the MLCS model tested, time period of each data set used for training and/or testing, IVF volume range represented by the data set, data set usage (e.g., used for both training and testing or testing only), and the validation type such as internal validation using cross-validation (CV) or external validation using out-of-time test set contemporaneous to clinical usage of model, coined LMV41,42,43. (https://towardsdatascience.com/why-isnt-out-of-time-validation-more-ubiquitous-7397098c4ab6)
Model metrics of discrimination and predictive power
We tested whether MLCS1 and MLCS2 models were superior to their respective Age models overall across the 6 centers and separately, whether each MLCS model was superior to its respective Age model for each of the 6 centers in terms of discrimination and predictive power, using the metrics ROC-AUC and PLORA, respectively. The median ROC-AUC and PLORA metrics and the interquartile range (IQR) for MLCS and their corresponding Age model across 6 centers were summarized in Table 2. Across centers, MLCS models showed improved ROC-AUC compared to their corresponding Age models using two-sided Wilcoxon signed-rank test (MLCS1: Z = 0.0, p < 0.05; MLCS2: Z = 0.0, p < 0.05) (Table 2). At the center level, MLCS model discrimination was shown to be superior to Age model for 5 of 6 centers using the two-sided, paired DeLong’s test (Supplementary Table 1). Separately, we assessed posterior log of odds ratio compared to Age model (PLORA) which indicated how much more likely MLCS models were to give a more correct LBP compared to the Age model given prior data, on a log scale34,35,36,39,40. MLCS1 and MLCS2 models showed improved predictive power as indicated by positive PLORA values for all MLCS models (Table 2 and Supplementary Table 1). (Statistical comparisons of PLORA between MLCS and Age models were not performed as PLORA was already a comparison against the Age control model log-likelihood value.)
Performance of updated models
Each of the 6 centers had previously received an updated MLCS2 model based on machine learning best practices to retrain models using more recent and larger datasets. We tested whether MLCS2 models were improved over MLCS1 models using the ROC-AUC and PLORA metrics. Across the 6 centers, ROC-AUC was similar between MLCS1 and MLCS2 (Z = 7.0, p > 0.05), but the PLORA of MLCS2 (median 23.9, IQR 10.2, 39.4) was significantly improved over that of MLCS1 (median 7.2, IQR 3.6, 11.8), (Z = 0.0, p < 0.05) using two-sided Wilcoxon signed-rank test (Table 2). Therefore, the model update process (i.e., using a larger data set including more recent years of data) resulted in improved predictive power as indicated by PLORA while discrimination was comparable.
External validation or live model validation of MLCS1 models
We tested whether MLCS1 models were appropriate and clinically applicable during the time period contemporaneous to its clinical usage by performing external validation, coined LMV in this specific context. We compared ROC-AUC and PLORA between each center’s MLCS1 model internal (in-time) CV test data and its LMV test data. LMV showed no significant difference from MLCS1 CV results in the ROC-AUC and PLORA values across the 6 clinics using two-sided Wilcoxon signed-rank test (ROC-AUC: Z = 5.0, p > 0.05; PLORA: Z = 6.0, p > 0.05) (Table 2). Further testing of LMV using two-sided, unpaired DeLong’s tests also did not detect significant differences in unweighted ROC-AUC. (Supplementary Table 2). Therefore, the MLCS1 models were externally validated to be appropriate for clinical utility as there was no evidence of concept drift.
Clinical data drift evaluation
Next, we assessed data drift by testing the statistical distribution of 17 key clinical variables or clinical diagnostic frequencies of patients’ first IVF cycles between the MLCS1 internal test set and MLCS1 external test set at each center. The number of clinical factors showing significantly different statistical distributions ranged from 1 to 2 clinical factors at 2 centers, 5 and 6 clinical factors at 3 centers, and 8 clinical factors at 1 center, p < 0.05 using two-sided, two-sample Kolmogorov–Smirnov test (continuous variables) and Chi-square tests (categorical variables)44,45,46. Importantly, none of the 6 centers showed a significant difference in female age between MLCS1 internal and external test sets. (Supplementary Table 3A–F.) Taken together with LMV results above, drift of clinical data was detectable but the nature and/or magnitude of the data drift did not affect clinical utility of MLCS models as indicated by external, LMV.
Comparison of MLCS2 and SART models
MLCS2 and SART models were evaluated for each center using the modified, center-specific de novo model validation test sets 1 and 2 (DNMV1 and DNMV2), each comprising an aggregate of 4645 and 4421 unique patient-cycles across 6 centers. The overall rates of live birth labeling were 58.5% and 56.4% for DNMV1 and DNMV2, respectively. Further, only ~5% of patient-cycles did not have an AMH value and they were tested by the SART model formulae that did not require AMH predictor29,30. Only DNMV1 results are reported here as DNMV2 results were similar to DNMV1 results. Descriptive statistics of key clinical variables and clinical diagnostic frequencies pertaining to the DNMV1 test set are shown in Table 329,30,39,40.
For the DNMV1 test set, ROC-AUC (Z = 7.0, p > 0.05) and PLORA (Z = 2.0, p > 0.05) were not significantly different between the MLCS2 and SART model responses across clinics, using two-sided Wilcoxon signed-rank test (Table 4). Model calibration was evaluated by computing the center-specific Brier scores for MLCS2 and SART model outputs using the DNMV1 test set. Across clinics, Brier scores were significantly lower (better) for MLCS2 compared to SART models using two-sided Wilcoxon signed-rank test (Z = 0.0, p < 0.05), indicating improved calibration of MLCS2 over the SART models. (Table 4; see Brier scores at the clinic level in Supplementary Table 4)37,39,40 Calibration plots for MLCS2 and SART models are shown in aggregate (Fig. 1) and for each center (Supplementary Fig. 2), with accompanying histograms showing the frequency distribution of LBPs47,48,49.

Calibration and frequency distribution plots of live birth predictions (LBP) comparing (A) MLCS2 Production Model and (B) SART Model using data from the six centers’ de novo model validation 1 (DNMV1; N = 4645) test sets in aggregate. The flexible calibration curve and its 95% confidence limits are represented by the plotted dark line and grey areas, respectively, using loess, a non-parametric smoother. MLCS2 model machine learning, center-specific model version 2, SART model Society for Assisted Reproductive Technology model, DNMV1 de novo model validation test set 1, adapted to enable testing of MLCS2 and SART models.
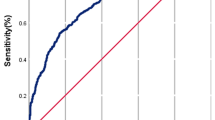
Further, we tested whether MLCS2 and SART models differed in their abilities to predict live birth outcomes (aka predict positive class) and minimize false positives and false negatives by using the model metrics F1 score (the harmonic mean of precision and recall) and Precision-Recall (PR) AUC24,33,44. The F1 score distribution, summarized using median and IQR, was higher for MLCS2 models compared to SART model across live birth prediction (LBP) thresholds sampled at ≥40%, ≥50%, ≥60%, ≥70% (Table 4). At the 50% LBP threshold, MLCS2 F1 scores (median 0.74 IQR 0.72, 0.78) were significantly higher than SART model F1 scores (median 0.71 IQR 0.68, 0.73), (Z = 0.0, p < 0.05) per two-sided Wilcoxon signed-rank test (Table 4). PR-AUC was also significantly higher for MLCS2 models (median 0.75, IQR 0.73, 0.77) compared to the SART model (median 0.69, IQR 0.68, 0.71) across the 6 centers, (Z = 0.0, p < 0.05) per two-sided Wilcoxon signed-rank test (Table 4). For each clinic, across the majority of recall thresholds, precision is higher for MLCS2 compared to SART models, resulting in higher PR curves (Fig. 2).

For each center, precision (aka positive predictive value) and recall (aka sensitivity or true positive rate) are plotted on the y-axis and x-axis, respectively. This PR curve shows that for the majority of recall thresholds, the precision is higher for MLCS2 models compared to SART model. The resulting PR-area-under-the-curve (PR-AUC) is significantly higher for MLCS2 models (median 0.75, IQR 0.73, 0.77) compared to the SART model (median 0.69, IQR 0.68, 0.71) across the 6 centers, (Z = 0.0, p < 0.05) per two-sided Wilcoxon signed-rank test. Color legend: MLCS2 (blue) and SART (red). PR Precision-Recall, DNMV1 de novo model validation test set 1, which was adapted to enable testing of MLCS2 and SART models and comprises 4645 first-IVF cycles in aggregate, MLCS2 model machine learning, center-specific model version 2, SART model Society for Assisted Reproductive Technology model, PR AUC Precision-Recall area-under-the-curve, IQR interquartile range.
Contextualizing clinical relevance of improved model metrics
Although the PR-AUC and F1 scores sufficed to show MLCS2 models provided more appropriate LBPs and clinical utility compared to the SART model, we also sought to communicate clinical relevance explicitly. Therefore, we created a 4 × 4 reclassification table to show the concordance and discordance of LBPs made by the MLCS2 production model and the SART models in a practical, clinical context (see Methods). Overall, 70% (3259 of 4645) of patients had concordant LBPs between SART and MLCS2 models (Fig. 3, green cells), while ~30% (1386 of 4645) of the patients had discordant LBPs (Fig. 3, peach or blue cells)—meaning, MLCS2 and SART models placed 1386 patients into different prognostic categories. Specifically, MLCS2 assigned 26% (1230 of 4645) of patients to a higher LBP category compared to the SART model (Fig. 3, blue cells). SART-LBPs underestimated live birth rates for each of those discordant groups across the spectrum of prognostic categories. Specifically, MLCS2 identified 23% patients with LBP ≥ 50% compared to lower LBPs given by SART. Importantly, MLCS2 models identified ~11% (494 of 4645) of patients to have LBP ≥ 75%, whereas SART model did not place any patient in that group even though the actual live birth rate of the MLCS-LBP ≥ 75% group was 81%. MLCS2 models also appropriately placed 3.4% (156 of 4645) of patients in lower LBPs compared to SART model (Fig. 3, peach cells). Similar patterns were shown for each center (Supplementary Fig. 3). Statistical analyses of reclassification was not performed due to their limited interpretation50,51.

The reclassification table shows the number of IVF cycles receiving predicted IVF live birth prediction (LBP) in each range by the SART vs. MLCS2 model, as well as the live birth rate for each cell. Color legends: Green - patient subgroups that have MLCS2-LBP and SART-LBP in the same prognostic category; Blue - patient subgroups with MLCS2 models placing patients in higher prognostic categories compared to SART model; Peach - patient subgroups with MLCS2 models placing patients in lower prognostic categories compared to SART model. MLCS2 machine learning, center-specific model version 2, SART model Society for Assisted Reproductive Technology model, DNMV1 de novo model validation test set 1, adapted to enable testing of MLCS2 and SART models, n the number of patients being placed into each of the 16 groups, LBR live birth rate of each group.
These findings were consistent with the MLCS2-LBP distribution being more skewed to the right compared to that of the SART model (Fig. 4). Further, each discordant group’s LBR aligned with the expected LBP range for the MLCS2-associated prognostic category. Similar patterns were observed at the center level (Supplemental Table 3A–F). Although the differential prognoses affecting an overall 30% of patients were not endpoints of this study, they served to contextualize more appropriate LBPs and improved PR-AUC and F1 score model metrics observed for MLCS2 over the SART models.

MLCS2 machine learning, center-specific model version 2, SART model Society for Assisted Reproductive Technology model, DNMV1 de novo model validation test set 1. Precision, Recall and Precision-Recall Curve—see Methods for details.
Discussion
This study compared individual MLCS models and the SART model for pretreatment IVF live birth prognostics for six unrelated, geographically distributed US fertility centers that reported to the SART registry. The retrospective study design was appropriate because the prognostic models were previously trained, tested, and already in clinical usage, and evaluation of the models’ technical performance were not biased by the retrospective design. MLCS model validation was performed prior to clinical usage and the deployed MLCS1 models were tested using an out-of-time external validation test set, coined LMV.
We took the pragmatic realist approach to address how MLCS and SART model predictions would differ for patients seeking care today. MLCS2 models performed better than the SART model in predicting the positive class (i.e., live birth prediction) while minimizing both false positives and false negatives, as indicated by the PR-AUC and F1 scores33,38. Translating to clinical context, as shown by the 4 × 4 reclassification table (Fig. 3), overall, 30% of patients showed discordant LBPs between MLCS2 and SART models. 26% of all patients were placed in a higher LBP category by MLCS compared to SART. Specifically, 23% and 11% of all patients were assigned to prognostic categories with LBP ≥ 50% and LBP ≥ 75%, respectively, by MLCS2 whereas SART placed them into lower prognostic categories. The improved PR-AUC, F1 scores and calibration per Brier score, tell us that the MLCS2 models gave more appropriate and colloquially more “accurate” LBPs compared to SART model for all discordant LBPs. The right-skewed LBP distributions for both MLCS2 and SART models but more so for MLCS2 paradoxically resulted in the calibration curves being limited by a sparsity of data points at the lower end of LBPs. These results translate directly to improved risk stratification, a pillar in achieving feasible value-based IVF pricing.
Why are the improved MLCS model metrics important? The improved MLCS model metrics have enabled implementation of a unifying tool to achieve clinical and operational goals important for patient-centered care and IVF access: (1) deliver transparent, personalized IVF prognostic counseling; (2) address patients’ and fertility center needs for prognostic information symmetry linked to fair pricing, risk-tiered, financial safeguards and easy operation by stand-alone fertility centers; (3) allow administration of value-based IVF pricing independent of financial lending (i.e., does not impose a loan on the consumer or rely on charging interest for sustainability); and (4) qualify over 50% of patients (i.e., not based on cherry-picking patients with top prognoses) for value-based pricing7,24.
A tenet of patient-centered care is informed consent based on appropriate prognostication52. Specifically, patients and providers should be aware of the available options to inform IVF prognostics and patients’ decision-making and how those options compare. Patients should know the potential benefits and limitations of subjecting themselves to the financial, emotional and physical impact of IVF. For example, patients with good or excellent prognosis should not be discouraged by an underestimation of prognosis, which may deter or delay IVF, potentially hurting their chances of having a family. Patients of poor prognosis should be properly informed in order to make very personal decisions such as the use of donor egg IVF (where legally permitted). Although no additional justification should be needed, we show how the MLCS approach strengthens the patient-provider relationship by prioritizing patients’ top concern: “Is this IVF success prediction based on your center’s own data?”53 Whereas the MLCS live birth prediction directly responds to that question with validation and transparency, the SART online calculator was not designed to address that concern. As stated by the SART online calculator’s disclaimer, “The estimates are based on the data we have available and may not be representative of your specific experience…Please speak with your doctor about your specific treatment plan and potential for success.”30 The SART model, in the format of a free online calculator, may serve to increase awareness of IVF as a potential treatment among patients who have not yet seen a provider. An important difference between the MLCS and SART models is that MLCS models are operated by professional provider teams employed by each fertility center as part of the center’s clinical services, whereas the SART model is an online tool available for use by any individual including providers, patients under care or patients who have not sought fertility care. In addition, the MLCS model output is given to patients by the provider team via a patient counseling report with wording and visuals that have been implemented in collaboration with and pre-approved by the provider team of each center53.
Improved LBP model metrics also enable greater efficiency in clinical operations and feasibility in value-based pricing, both of which are required to expand access to IVF treatment. Many fertility centers offer shared risk or refund programs to self-pay patients, with the goal of increasing the feasibility of doing a course of several IVF treatments to maximize the chance of having at least one baby from IVF. However, if the prediction models backing these shared risk programs have suboptimal F1 score and PR-AUC, more patients may be deemed ineligible to qualify for a financial program that is favorable to self-paying patients. Therefore, achieving high precision and recall directly alleviate the financial barrier while maximizing live birth outcomes for many patients24. MLCS models have already been successfully implemented and utilized by providers and patients to lower the cost per IVF baby for self-paying patients. This MLCS approach to IVF pricing can also be scaled and adapted for enterprise payers such as health plans and employers. A fuller discussion of such implementations is provided in a separate format as it is beyond the scope of this article24,54.
Importantly, while value-based care in all healthcare requires maximizing desired health outcomes and optimizing the costs of care, the design and requirements of value-based IVF care differ from the rest of healthcare for many reasons. The binary nature of IVF outcomes (succeed or fail) causes many patients to require more than one treatment, escalating the cost needed to reach a couple’s first IVF baby. In the US, the market competitive dynamics also differ as a large part of the market is consumer/self-pay; often, employer-funded IVF is administered through alternative benefits and not part of actuarial-based health insurance plans55,56,57,58. Thus “population health” strategies used in other health areas would not be directly applicable. Nonetheless, the MLCS approach enables success-cost transparency, which benefits patients and all stakeholders.
Though not the focus of this study, it is important to note that the MLCS2 framework enables stakeholders to measure fertility care and IVF outcomes more holistically using the health outcomes measure hierarchy advocated by Porter and Teisberg55. For example, IVF care outcomes that we have successfully applied to the MLCS framework can be organized according to this 3-level hierarchy: (1) achievement of the desired health status (aka live birth); (2) the need for re-intervention and the time taken (aka repeat IVF after a failed cycle, time-to-baby); and (3) sustainability (which, in IVF, largely relates to cost and utilization of services). In addition to the above, Level 2 outcomes such as short- or long-term physical, mental and emotional impacts of treatment should be measured, tracked and evaluated as well. By applying the MLCS framework, we have analyzed the more holistic set of fertility and IVF care outcomes broken down by prognostic group and other operational attributes such as location and provider team. New efforts to improve outcomes could then be tested per prognostic tier to inform operational and patient-care design.
In the context of clinical workflow, MLCS models can improve patient-centric care while supporting diverse healthcare providers to improve scalability and accessibility of IVF pretreatment counseling59,60. For example, in the US, in addition to usage by US board-certified specialists in reproductive endocrinology and infertility, MLCS-based counseling is used by advanced practice providers, nurse practitioners and registered nurses. In the UK and EU, they are used by consultants specialized in clinical infertility as well as general obstetrician-gynecologists. MLCS-based counseling reports have also been developed to support other clinical counseling scenarios such as after one or more failed IVF cycles, prior to egg freezing, empathetic delivery of prognosis and donor egg IVF options for patients with poor prognosis7,18,19,21,22,23,24,53,54,61.
Having discussed the application and scope of real-world benefits of MLCS models, we now discuss key design differences between MLCS and SART models followed by study limitations. Considering the SART model used 121,561 IVF cycles whereas the MLCS2 models used a median dataset size of 1163 IVF cycles (IQR 658-1662 IVF cycles) to achieve comparable ROC-AUC and improved PR-AUC and F1 score, the MLCS approach is 100× more data efficient29. Here, we offer potential factors that might have contributed to improved model metrics for MLCS2: (1) The greater number of consecutive years covered by the MLCS data sets allowed for more freeze-all cycles to generate cumulative outcomes from multiple transfer attempts of available cryopreserved blastocysts that reflect more realistic and higher live birth probabilities. (2) The lower-than-expected SART model ROC-AUC for the DNMV datasets may have resulted from the under 40 age limit of this study, whereas the original report of SART model training used a much larger data set and included age up to 50 years of age24,29. The inclusion of older patients can artificially increase the ROC-AUC due to the much lower IVF live birth rates among patients aged 40+, creating imbalance in a large portion of the data set. That issue is discussed in-depth in separate reviews24,33. (3) MLCS enables greater flexibility in the number and scope of clinical predictors to be tested and used by its prediction model, without constraints imposed by other centers’ patients and protocols7,24,25, Supplementary Fig. 1) (4) Close collaboration with providers and centers’ operational teams likely contributed to the quality and validation of MLCS models7,24. (5) Last but not least, quality control in the commercial environment is applied via standard operating processes to manage data processing and modeling pipelines, expert human supervision, quality testing and software validation, model deployment, and tracking of clinical utility and outcomes24,62,63. Design considerations were reviewed comprehensively by Yao et al. 24
This study’s key limitation is that our findings are limited to 6 fertility centers in the US. Also, this study was not designed to prove causality of differential design and model performance. In fact, we do not conclude that model improvement was necessarily attributed to the use of machine learning or center-specific approach. Further, this study did not intend to compare or advocate for gradient boosted machine (GBM) over other machine learning techniques such as Random Forests and LightGBM64,65,66. Although we strive to achieve superb model metrics, as a platform serving diverse fertility centers, we also consider other important qualities such as consistency in model behavior in response to data set variations, provider communications, support, explainability; and scalability to maximize affordability of technology usage. Further, we value the ability to rely on in-house validated quality assurance protocols which comply with quality management system and product lifecycle management standards in our choice of ML technique. Here, we should clarify that we did not use deep learning, foundational models or generative AI as those technologies had not been shown to be superior to traditional ML in predictive applications using structured clinical data67,68,69. Also, the AI techniques and the problems addressed by this study were distinct from AI usage to improve the quality and efficiency of embryo selection70,71,72.
Under the retrospective study design, it was not possible to know if the changes in statistical distribution of certain clinical variables between the MLCS1 CV and LMV time periods were due to true differences in patients’ characteristics or ongoing changes in the documentation methods or how clinical diagnoses were defined. Notably, female age was not different between those two time periods at the center level and the changes in clinical characteristics of patients appeared insufficient to affect LMV results. It was reassuring to know that the clinical utility of MLCS models was confirmed.
Separately, the use of certain “add-on’s” such as preimplantation genetic test for aneuploidy (PGT-A) and intracytoplasmic sperm injection (ICSI) were not specifically addressed by the MLCS or SART models for different reasons73. This point is not a study limitation per se but it is worthy of discussion because the differential model design affects the impact of add-ons. By design, the MLCS model inherently accounts for each center’s own approach to patient selection for PGT-A, ICSI and other protocol details. In our experience of collaborating with many centers over the past decade, fertility centers would rarely if ever make drastic changes to treatment protocols or patient selection for PGT-A or ICSI in a short time. Therefore, although centers may have different PGT-A usage patterns, the MLCS approach avoids inter-center differences. In contrast, by virtue of the SART model being trained with multicenter data and a center-agnostic approach, any center-level specifics such as PGT-A or ICSI usage pattern would not be reflected.
More broadly, the highly scaled MLCS framework—creating MLCS models for many centers with provider collaboration and quality control—can be used to advance reproductive research to accelerate delivery of benefits to patients. As local specificity is crucial in solving disparate health outcomes in fertility care and IVF, the MLCS framework can be applied to generate specific hypotheses for further investigations related to social determinants of fertility care utilization, access to care and IVF live birth outcomes74,75. The MLCS framework can also be used to improve clinical trial design to better detect efficacy of an intervention, such as novel therapeutics, while reducing trial cost via more targeted, prognostic-based recruitment. The MLCS approach can similarly be applied to support evaluation of “add-on” treatments that yielded inconclusive results when previously studied without a locally validated prognostic framework73. Imagine conducting clinical trials in oncology without validated staging, grading and in many cases, molecular diagnostics. We can leverage the MLCS framework to accelerate progress in evaluating diagnostic and therapeutic interventions. Ultimately, amassing insights from many MLCS models is expected to advance discovery and precision medicine in IVF with cost efficiency to elucidate molecular mechanisms of IVF failure, which will be fundamental to help more people have a family.
To summarize, this study aimed to provide a pragmatic comparison of the differential prognoses a patient may receive today if counseled using MLCS model or SART model at each of 6 participating centers. We discussed potential factors affecting differential model performance and study limitations as a necessary part of scientific discourse. In fact, we hope this study will help to advance reproductive medicine beyond dichotomies of multicenter versus center-specific or ML versus non-ML prediction models. From a utility perspective, we have implemented a globally applicable framework for MLCS modeling of IVF live birth prediction to inform locally relevant patient-provider counseling, clinical workflow and value-based IVF care to lower the cost per IVF baby7,18,24,53,54, Fig. 5) We next hypothesize the optimal prognostic solution is the multicenter scaling of a machine learning, localized approach. One possible next-step is to study IVF LBP model metrics on a wider range of fertility centers—larger centers, academic centers, centers in IVF coverage-mandated states and publicly funded IVF—to test whether multicenter scaling of MLCS models may bring additional benefits. We recommend expanding collaborative research efforts between public and private sectors to tackle crucial questions related to racial disparities in IVF, molecular mechanisms underlying clinical infertility and IVF failure, to both expand IVF care access and improve live birth outcomes and the patients’ experience.

A The MLCS-based, PreIVF model (MLCS model) product life cycle comprises the steps of data pre-processing, model training and validation, deployment and post-deployment validation (or live model validation). MLCS1, MLCS2, etc. indicates that each MLCS model will be replaced by an updated MLCS model trained and tested with a more recent data set which may also become cumulatively larger. B Model pipeline supports feature testing, model training, validation analysis, deployment to production and quality testing. “MLCS” is used generically to indicate the steps used for MLCS1, MLCS2 or any subsequent updates of MLCS model for a particular fertility center. MLCS machine learning, center-specific model version, SART model Society for Assisted Reproductive Technology model, LBP live birth probabilities, LMV live model validation, PMV production model validation, AUC area-under-the-curve (of receiver operating characteristic curve); HIPAA Health insurance Portability and Accountability Act, GDPR General Data Protection Regulation. * US Patent Number 9,458,495B2, Foreign Counterparts and Patents Issued. Copyright 2014–2025 Univfy Inc. All rights reserved.
Methods
This research study complied with all relevant ethical rules. Univfy Inc. submitted a research protocol which was reviewed by Sterling IRB, an accredited company providing institutional review board (IRB) services. Sterling IRB assigned exempt status to this research protocol pursuant to the terms of the U.S. Department of Health and Human Service’s (DHHS) Policy for Protection of Human Research Subjects at 45 C.F.R. §46.104(d) and its Category 4 Exemption (DHHS). The Category 4 Exemption (DHHS) criteria met by this research study were: (i) it is secondary research, meaning, the data had already been collected for another purpose other than for this research; and (ii) “the identity of the human subjects cannot readily be ascertained directly or through identifiers linked to the subjects, the investigator does not contact the subjects, and the investigator will not re-identify the subjects”. Informed consent and compensation were not applicable under the exempt status.
Research data sources, de-identified data sets and prior reporting of methods
IVF treatment clinical variables and outcomes data previously linked and processed as part of Univfy client services data, were further processed to have a different, randomly generated unique patient number and entered into the Univfy research database as per research protocol deemed exempt by institutional review board (IRB). The original data sources included processed data from each center’s electronic medical record and/or Society for Assisted Reproductive Technology Clinic Outcome Reporting System (SART CORS), the US national registry database managed by SART76.
The model development-to-deployment life cycle of the machine learning, center-specific (MLCS) models, including use of data processing and modeling pipelines, is summarized in Fig. 5. The following results and summaries were performed for models that were trained and deployed for clinical usage: MLCS1 and MLCS2 internal cross validation (CV) results (Table 2 and Supplementary Table 1); MLCS1 external validation or LMV results (Table 2 and Supplementary Table 2); summary statistics of key clinical variables and diagnostic frequencies (Supplementary Table 3A–F). To test for evidence of concept drift, we performed post-deployment, LMV for each center, using an out-of-time external validation test set comprising of first cycles from the time period following and exclusive from the MLCS1 internal validation data and contemporaneous with clinical usage of MLCS1 model24,41,42 (https://towardsdatascience.com/why-isnt-out-of-time-validation-more-ubiquitous-7397098c4ab6), Fig. 5).
See “Creating center-specific, de novo model validation test sets (DNMV1 and DNMV2) to enable statistical analyses of metrics of the MLCS2 and SART models” below for detailed methods used to create and analyze test sets for center-specific vs national registry model comparisons.
Data used for model training and testing, inclusion and exclusion criteria
Consecutive years of data within the 2013–2021 period were used for model training and testing performed for each center independently of the others (Table 1). Using a larger, more recent, historical data set, each center’s first model (MLCS1) was replaced by an updated model (MLCS2) trained and evaluated using the same MLCS model life cycle methods (Fig. 5). The MLCS2 models were in clinical use at the start of this retrospective study.
Definitions of IVF treatments, live birth and methods used for data collection, exclusion criteria, use of center-specific variables and MLCS model life cycle and evaluation steps including model training and testing, gradient boosted machines (GBM) on the Bernoulli distribution, and the use of area under the curve (AUC) of the receiver operating characteristic curve (ROC-AUC), ROC-AUC comparison over age-only control model (Age model) and posterior log of odds ratio compared to an age model (PLORA) were substantially as previously reported7,19,20,24,33,34,35,36, Fig. 5). PLORA, expressed in log scale, is the difference between the log-likelihood of the Age model and the log-likelihood of the MLCS model, based on the validation set. Advantages of machine learning in general and GBM specifically over logistic regression have been previously reviewed7,19,24,64.
In the MLCS models and throughout this article, an IVF cycle is defined as a gonadotropin ovarian stimulation cycle with the intention of retrieving oocytes for in vitro fertilization or ICSI, embryo culture and blastocyst transfer with or without preceding cryopreservation and/or preimplantation genetic testing for aneuploidy (PGT-A).
Inclusion criteria for model training and testing were: (1) IVF cycles that were started and used injectable gonadotropins to stimulate the ovaries, (2) IVF cycles using/intending to use the patient’s own eggs and uterus. Exclusion criteria were: Frozen embryo transfers (FETs) not linked to an original IVF ovarian stimulation cycle within that data set; cancellations for reasons unrelated to IVF (e.g., covid, personal reasons, etc.); the use of donor egg, gestational carrier, embryo donation, egg freezing or fertility preservation for any reason; IVF cycles without documentation of the female patient’s age or outcome; IVF cycles performed for patients aged 42 and up; freeze-all cycles that have not had any FETs; batched IVF cycles; usage of preimplantation genetic testing for known hereditary mutations. IVF cycles that resulted in cancellation of egg retrieval, no blastocyst or euploid blastocyst available for transfer or PGT-A usage were not excluded.
Due to the nature of IVF treatment, all patients were of at least female biological sex having a uterus and at least one ovary. If male partner data pertaining to male factor infertility, sperm usage and method for obtaining sperm were available, they were included in the analysis and modeling; however, the presence of a male partner or male partner data was not required as donor sperm usage also sufficed. Race, ethnicity, religion, IVF coverage status, even if available in the original source, were not processed or used in any way in this research project.
IVF labeling criteria in the data used for MLCS training and testing
IVF cycles were labeled as having “no live birth outcome” if they resulted in cancellation at any point due to reasons related to the IVF cycle (e.g., poor ovarian response, thin endometrium, no viable oocytes, no fertilization, no blastocyst for transfer or no euploid blastocyst, etc.). In the context of MLCS models, an IVF cycle has achieved a live birth outcome if at least one live birth or clinical ongoing pregnancy were documented from one or more fresh and/or frozen embryo transfer(s) using the number of blastocyst(s) according to American Society for Reproductive Medicine guidelines77,78.
To be clear, while MLCS and SART pretreatment models had live birth outcomes as primary outcomes for model prediction, live birth outcome itself is not the primary outcome in this study. Rather, this study’s objective was to evaluate MLCS and SART models using model performance metrics. However, comparison of model metrics required providing methods used to process data, train and test MLCS pretreatment models.
Feature sets, model predictors and relative importance of model predictors
The MLCS and SART model feature sets both included female patient’s age, BMI, AMH, standard clinical diagnoses, and prior term birth reproductive history. If available, the MLCS model training also considered other ovarian reserve tests (i.e., Day 3 FSH, AFC) and any additional clinical diagnoses and reproductive history information provided by each center. By allowing models to consider the importance of each model feature at the center level, in addition to considering more clinical diagnoses and reproductive history information, MLCS models reflect each center’s practice without being affected by inter-center laboratory or patient population differences (Supplementary Fig. 1). Note the model predictors used by each center’s MLCS2 model and their relative importance vary across centers, despite drawing from a similar set of clinical variables29,30, Supplementary Fig. 1). This is related to the availability of the data and the strength of its association with live birth outcomes in each clinic’s data set. More detailed considerations of MLCS model design were described by Yao et al. 24
Cross validation (CV) and model metrics
Our standard model evaluation procedure required k-fold cross validation on an in-time internal validation test set (the test and training data sources were contemporaneous) to compute the ROC-AUC and PLORA (Fig. 5). Calculations of ROC-AUC and PLORA accounting for sample weights were calculated using custom code (uploaded to Code Ocean). These weighted ROC-AUC and PLORA values were used for statistical comparisons across centers using the two-sided Wilcoxon signed-rank test44 using python scipy library79. Unweighted MLCS and Age model ROC-AUC values with 95% confidence interval (95% CI) were calculated using the R-package pROC to support application of the two-sided, paired DeLong’s test80. We typically used weighted metrics to account for patients who had recurrent IVF cycles in the data set to avoid having over-representation by a small group of patients.
Statistical analyses comparing MLC1 CV, MLCS2 CV, and MLCS1 LMV model metrics
Model metrics for MLCS1 internal CV, MLCS2 internal CV, and MLCS1 external LMV were reported using median and IQR across 6 centers in Table 2, and at the clinic level in Supplementary Tables 1 and 2. Two-sided Wilcoxon signed-rank test, allowing for non-parametric paired-testing, was used to compare model metrics paired by center44 using python scipy library79. At the center level, two-sided paired DeLong’s test was used to compare MLCS and Age model ROC-AUC using the R-package pROC80. Two-sided, unpaired DeLong’s test was used to compare MLCS1 CV and MLCS1 LMV ROC-AUC using the R-package pROC80.
Statistical analyses comparing statistical distribution of MLC1 CV and MLCS1 LMV test data
To test for data drift, the distribution of clinical variables between first cycles in MLCS1 CV and MLCS1 LMV data sets were compared using the two-sided, two-sample Kolmogorov–Smirnov test for continuous variables and the Chi-square test for homogeneity of proportions reported for diagnostic frequencies and sperm variable incidences44,45,46. These statistical analyses were carried out using R 3.6.181.
Creating center-specific, de novo model validation test sets (DNMV1 and DNMV2) to enable comparison of MLCS2 and SART models
We adapted each of the 6 center-specific MLCS2 internal validation test sets to a center-specific, de novo model validation test set (DNMV1) that allowed validation of MLCS2 and SART models for each center by meeting both MLCS2 and SART model input requirements. This adaptation was performed by limiting the internal validation test set based on these criteria: first IVF cycles started in 2013–2021; age under 40 (required by MLCS model); IVF cycles having BMI value (required by SART model); yes/no for male factor, ovulatory disorder, PCOS, uterine factor and unexplained infertility diagnoses; yes/no for prior full-term birth(s). The aggregated DNMV1 test set comprised 4645 first IVF cycles. Table 3 shows the center-specific summary statistics of key predictors and diagnostic frequencies making up the DNMV1 test set.
For the purpose of MLCS2 and SART model comparison, the DNMV1 test set was subjected to center-specific MLCS2 CV or production model responses while SART model responses were obtained by using pre-treatment model formulae, with and without AMH predictor, reportedly used to support the online SART calculator, as provided in the supplement of McLernon et al. 29 Other than to confirm the accurate implementation of those formulae using a few test cases, we did not interact with or use the online SART calculator website for this research study.
In the context of IVF live birth prediction models, model training required labeling each IVF cycle as having the binary outcomes “live birth” versus “no live birth”. One intentional design difference between MLCS and SART models was that in MLCS2, the models are trained with live births and clinical ongoing pregnancies labeled as “live birth”, whereas the SART model labeled live births as “live birth” and clinical ongoing pregnancies as “no live birth”29.
Since the impact of this intentional design difference was not known, we also created test sets void of IVF cycles with clinical ongoing pregnancies, so that we could be sure any model comparison results were not simply due to those cycles having differential outcome labeling between MLCS and SART models. Therefore, we created a second set of 6 independent test sets (DNMV2) by removing the ~4.8% of IVF cycles with clinical ongoing pregnancies from the DNMV1 test sets.
Statistical analyses comparing MLCS2 and SART model metrics
For MLCS2 vs SART comparisons, the age-based live birth rates stated in the finalized 2020 SART National Summary were used as the Age model because practically, that is the number that providers and patients would use if they were not using any prediction models82.
CV model responses were used to calculate ROC-AUC and PLORA metrics to estimate model performance on new data not used to train the model. Production model responses were used for F1 scores, PR-AUC, calibration plots, and Brier score (measuring calibration) since production model responses are the LBPs providers and patients would see. The MLCS2 and SART models were compared using six independent, center-specific DNMV1 test sets for ROC-AUC, PLORA, PR-AUC, F1 scores and Brier scores. For illustrative purposes, calibration curves and frequency distribution graphs were also generated using the aggregate DNMV1 test set (Fig. 1). The flexible calibration curve and its 95% confidence limits are represented by the plotted dark line and grey areas, respectively, using loess, a non-parametric smoother. The entire process of model comparisons was repeated using DNMV2 test sets33,34,35,36,37,38,39,40,43,44,79,81.
Model metrics for MLCS2 vs SART were reported using median and IQR across 6 centers in Table 4, and at the center level in Supplementary Table 4. Precision, recall, and F1 scores were calculated using custom code (uploaded to Code Ocean). PR-AUC values and PR-AUC curves were generated using python scikit-learn library83. Two-sided Wilcoxon signed-rank test, allowing for non-parametric paired-testing, was used to compare MLCS2 and SART model metrics paired by center44 using python scipy library79. The Brier score metric, measuring calibration and calibration plots were generated using the R-package CalibrationCurves47,48,49.
To provide clinical context, we created a 4 × 4 reclassification table for the DNMV1 test set to show the concordance and discordance of LBPs between MLCS2 and SART models. (Fig. 3) Patients were placed into one of 16 groups based on their LBPs as computed by MLCS2 and SART (MLCS2-LBPs and SART-LBPs, respectively), using 4 arbitrarily defined, yet clinically intuitive prognostic categories based on LBPs: Low LBP (LBP < 25%), Medium LBP (LBP 25–49.9%), High LBP (LBP 50–74.9%) and Very High LBP (LBP ≥ 75%). (Fig. 3) Patient groups were concordant if SART and MLCS2 models placed the patients into the same prognostic category (colored green in Fig. 3); patient groups were discordant if SART and MLCS2 models placed patients into different prognostic categories (colored blue or peach in Fig. 3). Figure 3 was replicated for each of the 6 centers to show center-specific, 4 × 4 reclassification table in Supplementary Fig. 3.
The EQUATOR Reporting Guidelines including “TRIPOD + AI statement: updated guidance for reporting clinical prediction models that use regression or machine learning methods” were followed39,40.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The de-identified data sets containing clinical data are not available for sharing with other researchers because they are the property of each of six different third-party entities and while the co-authors obtained permission to use the data for research, they do not have permission to share the data externally. The contact person for any data-related questions or further contact information for third-party entities is the corresponding author, M. Yao who can be contacted at mylene.yao@univfy.com with expected response time of 2–4 weeks.
Code availability
Custom code for computing model metrics were made available via Code Ocean, with https://doi.org/10.24433/CO.8413662.v1. Functions for comparing model metrics are accessible via publicly available packages and libraries, which are stated wherever applicable. Code from the data pre-processing, processing and model pipelines are proprietary and can be shared via licensing; we would also be open to using these pipelines to support or collaborate with other researchers. The contact person for any code-related questions is the corresponding author, M. Yao who can be contacted at mylene.yao@univfy.com.
References
World Health Organization. Infertility Prevalence Estimates, 1990-2021 (Last accessed 7 February 2025) https://www.who.int/publications/i/item/978920068315 (Global Report, 2023).
U.S. Department of Health and Human Services. Fact Sheet: In Vitro Fertilization (IVF) Use Across the United States (Last accessed 7 February 2025) https://public3.pagefreezer.com/browse/HHS.gov/02-01-2025T05:49/https://www.hhs.gov/about/news/2024/03/13/fact-sheet-in-vitro-fertilization-ivf-use-across-united-states.html (2024).
Definition of Infertility: A Committee Opinion. American Society for Reproductive Medicine (Last accessed 7 February 2025). https://www.asrm.org/practice-guidance/practice-committee-documents/denitions-of-infertility/ (2023).
European Parliamentary Forum for Sexual & Reproductive Rights. White paper on “The Imperative on Access to Fertility Treatments Across Europe” (Last accessed 7 February 2025) https://www.epfweb.org/node/999 (2023).
Adamson, G. D., Zegers-Hochschild, F. & Dyer, S. Global fertility care with assisted reproductive technology. Fertil. Steril. 120, 473–482 (2023).
Fauser, B. C. J. M. et al. Declining global fertility rates and the implications for family planning and family building: an I FFS consensus document based on a narrative review of the literature. Hum. Reprod. Update 30, 153–173 (2024).
Jenkins, J. et al. Empathetic application of machine learning may address appropriate utilization of ART. Reprod. BioMed. Online 41, 573–577 (2020).
Cox, C. M. et al. Infertility prevalence and the methods of estimation from 1990 to 2021: a systematic review and meta-analysis. Hum. Reprod. Open 2022 https://doi.org/10.1093/hropen/hoac051 (2022).
Boivin, J., Bunting, L., Collins, J. A. & Nygren, K. G. International estimates of infertility prevalence and treatment-seeking: potential need and demand for infertility medical care. Hum. Reprod. 22, 1506–1512 (2007).
ESHRE. ART Fact Sheet. https://www.eshre.eu/Europe/Factsheets-and-infographics (2023).
Adamson, G. D. et al. International committee for monitoring assisted reproductive technology: world report on assisted reproductive technology, 2018. https://www.icmartivf.org/reports-publications/presentations/ (2022).
Adamson, G. D. et al. (2022) International committee for monitoring assisted reproductive technology: world report on assisted reproductive technology https://www.icmartivf.org/reports-publications/presentations/ (2019).
Zegers-Hochschild, F. et al. The international glossary on infertility and fertility care, 2017. Fertil. Steril. 108, 393–406 (2017).
Bunting, L., Tsibulsky, I. & Boivin, J. Fertility knowledge and beliefs about fertility treatment: findings from the International Fertility Decision-making Study. Hum. Reprod. 28, 385–397 (2013).
Collura, B. et al. Identifying factors associated with discontinuation of infertility treatment prior to achieving pregnancy: results of a nationwide survey. J. Patient Exp. 11. https://doi.org/10.1177/23743735241229380 (2024).
Malizia, B. A., Hacker, M. R. & Penzias, A. S. Cumulative live-birth rates after in vitro fertilization. N. Engl. J. Med. 360, 236–243 (2009).
Smith, A. D. A. C., Tilling, K., Nelson, S. M. & Lawlor, D. A. Live-birth rate associated with repeat in vitro fertilization treatment cycles. JAMA 314, 2654–2662 (2015).
Yao, M. W. M. et al. Improving IVF utilization with patient-centric artificial intelligence-machine learning (AI/ML): a retrospective multicenter experience. J. Clin. Med. 13, 3560 (2024).
Banerjee, P. et al. Deep phenotyping to predict live birth outcomes in in vitro fertilization. Proc. Natl. Acad. Sci. USA 107, 13570–13575 (2010).
Nelson, S. M. et al. Antimüllerian hormone levels and antral follicle count as prognostic indicators in a personalized prediction model of live birth. Fertil. Steril. 104, 325–332 (2015).
Choi, B. et al. Personalized prediction of first-cycle in vitro fertilization success. Fertil. Steril. 99, 1905–1911 (2013).
Lannon, B. M. et al. Predicting personalized multiple birth risks after in vitro fertilization-double embryo transfer. Fertil. Steril. 98, 69–76 (2012).
Chen, S. H., Xie, Y. A., Cekleniak, N. A., Keegan, D. A. & Yao, M. W. M. In search of the crystall ball - how many eggs to a live birth? A 2-step prediction model for egg freezing counseling based on individual patient and center data. Fertil. Steril. 112, E83–E84 (2019).
Yao, M. W. M., Jenkins, J., Nguyen, E. T., Swanson, T. & Menabrito, M. Patient-centric in vitro fertilization prognostic counseling using machine learning for the pragmatist. Semin Reprod. Med. 42, 112–129 (2024).
Swanson, T. et al. Inter-center variation of patients’ clinical profiles is associated with IVF live birth outcomes. Fertil. Steril. 120, E175 (2023).
Cai, J. et al. Pretreatment prediction for IVF outcomes: generalized applicable model or centre-specific model? Hum. Reprod. 39, 364–373 (2024).
Qiu, J., Li, P., Dong, M., Xin, X. & Tan, J. Personalized prediction of live birth prior to the first in vitro fertilization treatment: a machine learning method. J. Transl. Med. 17, 317 (2019).
Liu, X., Chen, Z. & Ji, Y. Construction of the machine learning-based live birth prediction models for the first in vitro fertilization pregnant women. BMC Pregnancy Childbirth 23, 476 (2023).
McLernon, D. J. et al. Predicting personalized cumulative live birth following in vitro fertilization. Fertil. Steril. 117, 326–338 (2022).
Society for Assisted Reproductive Technology and University of Aberdeen (Last accessed 10 May 2024) https://w3.abdn.ac.uk/clsm/SARTIVF/.
McLernon, D. J., Steyerberg, E. W., Te Velde, E. R., Lee, A. J. & Bhattacharya, S. Predicting the chances of a live birth after one or more complete cycles of in vitro fertilisation: population based study of linked cycle data from 113 873 women. BMJ 355, i5735 (2016).
Ratna, M. B., Bhattacharya, S. & McLernon, D. J. External validation of models for predicting cumulative live birth over multiple complete cycles of IVF treatment. Hum. Reprod. 38, 1998–2010 (2023).
Saito, T. & Rehmsmeier, M. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 10, e0118432 (2015).
O’Hagan, T. Bayes factors. Significance 3, 184–186 (2006).
van de Schoot, R. et al. A gentle introduction to bayesian analysis: applications to developmental research. Child Dev. 85, 842–860 (2014).
Fiveable. All study guides. Bayesian statistics. Unit 9 - Bayesian hypothesis testing (Accessed 7 February 2025) https://library.fiveable.me/bayesian-statistics/unit-9/posterior-odds/study-guide/NcOqQFGxK9sj5iAf.
Rufibach, K. Use of Brier score to assess binary predictions. J. Clin. Epidemiol. 63, 938–939 (2010).
Srivastava, T. 12 Important model evaluation metrics for machine learning everyone should know (updated 2023) (Accessed 1 June 2024). https://www.analyticsvidhya.com/blog/2019/08/11-important-model-evaluation-error-metrics/.
TRIPOD+AI statement: updated guidance for reporting clinical prediction models that use regression or machine learning methods. BMJ. 385, q902. https://doi.org/10.1136/bmj.q902 (2024). Erratum for: BMJ. 2024 Apr 16;385:e078378. PMID: 38636956; PMCID: PMC11025451. URL: https://www.equator-network.org/reporting-guidelines/tripod-statement/ (last accessed 10 May 2024).
Equator Network. Enahance the QUAlity and Transparency Of health Research. URL: equator-network.org (last accessed 10 May 2024).
Sahiner, B., Chen, W., Samala, R. K. & Petrick, N. Data drift in medical machine learning: implications and potential remedies. Br. J. Radio. 96, 20220878 (2023).
Subbaswamy, A. & Saria, S. From development to deployment: dataset shift, causality, and shift-stable models in health AI. Biostatistics 21, 345–352 (2020).
Cross validation in machine learning (Accessed 2024) https://www.geeksforgeeks.org/cross-validation-machine-learning/ (2023).
Kundu, S., Aulchenko, Y. S., van Duijn, C. M. & Janssens, A. C. PredictABEL: an R package for the assessment of risk prediction models. Eur. J. Epidemiol. 26, 261–264 (2011).
Chakravarti, L. & Roy. Handbook of Methods of Applied Statistics, Vol. 1, 392–394. (John Wiley and Sons, 1967).
Mishra, P. et al. Descriptive statistics and normality tests for statistical data. Ann. Card. Anaesth. 22, 67–72 (2019).
Van Calster, B. et al. A calibration hierarchy for risk models was defined: from utopia to empirical data. J. Clin. Epidemiol. 74, 167–176 (2016).
De Cock, B., Nieboer, D., Van Calster, B., Steyerberg, E. & Vergouwe, Y. The CalibrationCurves package: assessing the agreement between observed outcomes and predictions. https://doi.org/10.32614/CRAN.package.CalibrationCurves, R package version 2.0.3, https://cran.r-project.org/package=CalibrationCurves (2023).
De Cock Campo, B. Towards reliable predictive analytics: a generalized calibration framework. Preprint at arXiv, 2309.08559. https://arxiv.org/abs/2309.08559 (2023).
Kerr, K. F. et al. Net reclassification indices for evaluating risk prediction instruments: a critical review. Epidemiology 25, 114–121 (2014).
Kerr, K. F. Net reclassification index statistics do not help assess new risk models. Radiology 306, e222343 (2023).
Shah, P., Thornton, I., Kopitnik, N. L. & Hipskind, J. E. Informed consent. 2024 Nov 24. In StatPearls [Internet]. (Treasure Island (FL): StatPearls Publishing, 2025).
Univfy Inc. Research Support - Sample Patient Counseling Report (Accessed 7 February 2025). https://www.univfy.com/research. (2024).
Univfy. Sample ML-based IVF refund program cost comparison. (Accessed 8 February) https://www.univfy.com/research/sample-ivf-refund-program-cost-comparison (2025).
Porter M. E. & Teisberg E. O. Redefining Health Care: Creating Value-Based Competition on Results (Harvard Business School Press, Boston, 2006).
Bensink, M. et al. Value-based healthcare in fertility care using relevant outcome measures for the full cycle of care leading towards shared decision-making: a retrospective cohort study. BMJ Open 13, e074587 (2023).
Teisberg, E., Wallace, S. & O’Hara, S. Defining and implementing value-based health care: a strategic framework. Acad. Med. 95, 682–685 (2020).
RESOLVE - The National Infertility Association. Insurance coverage by state (Accessed 9 September 2024) https://resolve.org/learn/financial-resources-for-family-building/insurance-coverage/insurance-coverage-by-state/ (2024).
Hariton, E. et al. Meeting the demand for fertility services: the present and future of reproductive endocrinology and infertility in the United States. Fertil. Steril. 120, 755–766 (2023).
Adeleye, A. J. et al. The mismatch in supply and demand: reproductive endocrinology and infertility workforce challenges and controversies. Fertil. Steril. 120, 403–405 (2023).
Klipstein, S. The role of compassionate reproductive care and counseling in the face of futility. Fertil. Steril. 120, P409–P411 (2023).
Overgaard, S. M. et al. Implementing quality management systems to close the AI translation gap and facilitate safe, ethical, and effective health AI solutions. NPJ Digit. Med. 6, 218 (2023).
Zhang, A., Xing, L., Zou, J. & Wu, J. C. Shifting machine learning for healthcare from development to deployment and from models to data. Nat. Biomed. Eng. 6, 1330–1345 (2022).
Friedman, J. H. Greedy function approximation: a gradient boosting machine. Ann. Stat. 29, 1189–1232 (2001).
Breiman, L. Random forests. Mach. Learn 45, 5–32 (2001).
Ke, G. et al. LightGBM: a highly efficient gradient boosting decision tree 20173149–3157 (Last accessed 7 February 2025) https://papers.nips.cc/paper_files/paper/2017.
Chen, D. et al. Deep learning and alternative learning strategies for retrospective real-world clinical data. NPJ Digit. Med. 2, 43 (2019).
Wornow, M. et al. The shaky foundations of large language models and foundation models for electronic health records. NPJ Digit. Med. 6, 135 (2023).
Bousquette, I. A Clamor for generative AI (even if something else works better). Wall Street J. (Accessed 24 July 2024) https://www.wsj.com/articles/a-clamor-for-generative-ai-even-if-something-else-works-better-d9bd0257 (2024).
Rajendran, S. et al. Automatic ploidy prediction and quality assessment of human blastocysts using time-lapse imaging. Nat. Commun. 15, 7756 (2024).
Illingworth, P. J. et al. Deep learning versus manual morphology-based embryo selection in IVF: a randomized, double-blind noninferiority trial. Nat Med. https://doi.org/10.1038/s41591-024-03166-5 (2024).
Diakiw, S. M. et al. Development of an artificial intelligence model for predicting the likelihood of human embryo euploidy based on blastocyst images from multiple imaging systems during IVF. Hum. Reprod. 37, 1746–1759 (2022).
ESHRE Add-ons working group, Lundin, K. et al. Good practice recommendations on add-ons in reproductive medicine†. Hum. Reprod. 38, 2062–2104 (2023).
Richard-Davis, G. & Morris, J. No longer separate but not close to equal: navigating inclusivity in a burgeoning field built on injustice. Fertil. Steril. 120, 400–402 (2023).
Ekechi, C. Addressing inequality in fertility treatment. Lancet 398, 645–646 (2021).
Curchoe, C. L., Tarafdar, O., Aquilina, M. C. & Seifer, D. B. SART CORS IVF registry: looking to the past to shape future perspectives. J. Assist. Reprod. Genet. 39, 2607–2616 (2022).
Practice Committee of the American Society for Reproductive Medicine and the Practice Committee for the Society for Assisted Reproductive Technologies. Guidance on the limits to the number of embryos to transfer: a committee opinion. Fertil. Steril. 116, 651–654 (2021).
Practice Committee of the American Society for Reproductive Medicine and the Practice Committee for the Society for Assisted Reproductive Technologies. Guidance on the limits to the number of embryos to transfer: a committee opinion. Fertil. Steril. 107, 901–903 (2017).
Virtanen, P. et al. SciPy 1.0 Contributors. SciPy 1.0: fundamental algorithms for scientific computing in Python. Nat Methods. 17, 261–272 10.1038/s41592-019-0686-2 (2020). Erratum in: Nat Methods. 2020 Mar;17(3):352. https://doi.org/10.1038/s41592-020-0772-5
Robin, X. et al. pROC: an open-source package for R and S+ to analyze and compare ROC-curves. BMC Bioinforma. 12, 77 (2011).
R Core Team. R: A Language and Environment for Statistical Computing. https://www.R-project.org/ (R Foundation for Statistical Computing, Vienna, Austria, 2021).
Society for Assisted Reproductive Technology (Last accessed 10 May 2024). www.sart.org.
Pedregosa, F. et al. Scikit-learn: machine learning in Python. JMLR 12, 2825–2830 (2011).
Acknowledgements
The authors thank the following individuals for their assistance, editing, advisory, insightful comments and contributions to the present research: Faith Ripley, BS, CPC (PREG); Patrick McCarthy, MBA (Poma Fertility); Amanda McCarthy, MBA (Poma Fertility); Brijinder S. Minhas, PhD, HCLD, MBA (NewLIFE); Wing H. Wong, PhD (Advisor); Vincent Kim, B.Sc. (Univfy Inc.); Marco Menabrito, MD (Univfy Inc.); Anjali Wignarajah, M.Sc. (Univfy Inc.); Candice Ortego, RN, BSN (Univfy Inc.); Athena T. R. Wu (editing). Each organization funded its own participation. No external funding was used.
Author information
Authors and Affiliations
Contributions
E.T.N. and M.W.M.Y. contributed to the original study conceptualization, design, methodology, preparation of data subsets for analyses, statistical analyses, data interpretation and visualization; writing of the original manuscript drafts and revisions. E.T.N., T.S., X.C. contributed to code development, data processing, modeling, and methodologies related to those processes. E.T.N., M.W.M.Y., T.S., X.C. contributed to curation of processed data. M.G.R., L.A.G., J.E.N., J.F.P., B.A.R., M.O., J.G., R.B., L.N., G.N., J.A. contributed to conceptualization of study, data collection, curation of data, interpretation of data processing and modeling results, review and revision of manuscript. All authors approved submission of the manuscript for publication.
Corresponding author
Ethics declarations
Competing interests
All researchers who meet authorship criteria are listed as authors; individuals who assisted and contributed to the research but do not meet authorship criteria are acknowledged under Acknowledgements. M Yao is employed as CEO by Univfy Inc. and is board director, shareholder and stock optionee of Univfy; she is inventor or co-inventor on Univfy’s issued and pending patents and receives payment from patent licensor (Stanford University). ET Nguyen, T Swanson, X Chen are employed by and received stock options from Univfy Inc. M Retzloff performs paid consulting work as Nexplanon trainer for Organon and is Treasurer for the Society for Reproductive Technology (SART). The remaining authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Max H J M Curfs and the other anonymous reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yao, M.W.M., Nguyen, E.T., Retzloff, M.G. et al. Machine learning center-specific models show improved IVF live birth predictions over US national registry-based model. Nat Commun 16, 3661 (2025). https://doi.org/10.1038/s41467-025-58744-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-025-58744-z
