
Abstract
Retinal image registration is vital for diagnostic therapeutic applications within the field of ophthalmology. Existing public datasets, focusing on adult retinal pathologies with high-quality images, have limited number of image pairs and neglect clinical challenges. To address this gap, we introduce COph100, a novel and challenging dataset known as the Comprehensive Ophthalmology Retinal Image Registration dataset for infants with a wide range of image quality issues constituting the public “RIDIRP” database. COph100 consists of 100 eyes, each with 2 to 9 examination sessions, amounting to a total of 491 image pairs carefully selected from the publicly available dataset. We manually labeled the corresponding ground truth image points and provided automatic vessel segmentation masks for each image. We have assessed COph100 in terms of image quality and registration outcomes using state-of-the-art algorithms. This resource enables a robust comparison of retinal registration methodologies and aids in the analysis of disease progression in infants, thereby deepening our understanding of pediatric ophthalmic conditions.
Similar content being viewed by others

Background & Summary
Retinal image registration plays a pivotal role in disease diagnosis1,2, image-guided surgery3, monitoring of disease progression4, and image fusion5. The primary objective of image registration is to spatially align a query (source) image with a reference (target) image by determining a geometric transformation that accurately matches the corresponding features or structures between the two images. In the realm of ophthalmology, retinal image registration has become an indispensable tool, facilitating precise tracking of temporal changes in retinal anatomy and the alignment of different imaging modalities, which is crucial for evaluating disease evolution and treatment outcomes6,7.
In the field of ophthalmology, various imaging modalities are used, including color fundus (CF), optical coherence tomography (OCT), fluorescein angiography (FA). The integration of these diverse imaging modalities via registration enhances the comprehensive analysis of retinal pathologies. Numerous studies have been dedicates to proposing retinal image registration algorithms, thereby propelling the advancement of this domain. As delineated in several review papers6,7, these algorithms can be categorized into multi-modal and single modal image registration based on the input image modality. The corresponding datasets are summarized in Table 1, all of which come with the ground truth data for registration purposes. Datasets such as RODREP8 (http://www.rodrep.com/data-sets.html), TeleOphta9 (https://www.adcis.net/en/third-party/e-ophtha/), and VARIA10 (http://www.varpa.es/research/biometrics.html), which were originally created for application other than registration, are excluded from the table.
Recent advancements in retinal imaging have led researchers to propose various multi-modal image registration datasets. For instance, Lee et al.11 introduced a private dataset in 2015, which includes CF and OCT images. In 2020, Almsasi et al.12 presented a FA-scanning laser ophthalmoscopy (FA-SLO) dataset, from patients with diabetic retinopathy. The PRIME-FP20 dataset13 (https://ieee-dataport.org/open-access/prime-fp20-ultra-widefield-fundus-photography-vessel-segmentation-dataset), introduced in 2021, comprises ultra-wide-field fluorescence angiography (FA) and fundus photography (FP) images. FOCTAIR14 (http://www.varpa.es/research/ophtalmology.html) contains FA and optical coherence tomography angiography (OCTA) images from retinal vein occlusion (RVO) patients. In 2024, MEMO15 (https://chiaoyiwang0424.github.io/MEMO/) was introduced, which consists of Erythrocyte-mediated Angiography(EMA) and OCTA images from normal patients.
While additional imaging modalities such as OCT and FA are employed as necessary for diagnostic or therapeutic purposes, color fundus photography is still the most frequently utilized data type in clinical settings. For example, FLoRI2116 (https://ieee-dataport.org/open-access/flori21-fluorescein-angiography-longitudinal-retinal-image-registration-dataset)includes ultra-wide-field fundus photography from 15 patients, presenting a significant challenge for registration due to its extensive field of view. The LSFG dataset17, from 2024, encompasses images from 15 patients with uveal melanoma. Given that color fundus photography remains the most commonly used imaging modality in hospitals, the FIRE dataset18 (https://projects.ics.forth.gr/cvrl/fire/) has been predominantly evaluated. It is categorized into three classes based on the extent of image overlap and the presence or absence of anatomical features. The majority of image pairs within the FIRE dataset are utilized for super-resolution and mosaicking purposes. Only 14 image pairs were acquired from different examinations of retinopathy, yet they exhibit significant overlap. All images in the FIRE dataset are of high resolution. With the integration of deep learning algorithms into fundus image registration, the accuracy of the dataset has already achieved a high level, with a reported 0.85 mean Area Under the Curve (mAUC) and RMSE less than 2.919. Consequently, in response to current demands, we construct a challenging monomodal fundus image registration dataset COph100, which contains 100 eyes and 491 pairs of images from Retinopathy of Prematurity (ROP) infants. Given the current publicly available ROP datasets1 (https://doi.org/10.6084/m9.figshare.c.6626162.v1), this paper primarily discusses how to utilize these existing public datasets to further pursue research of one’s interest.
To the best of our knowledge, the COph100 dataset is the first retinal registration dataset specifically focused on disease progression in infants. Its potential impact, which addresses several existing limitations, can be outlined as follows: First, Minimal apprarance variablity: A common limitation of most retinal image registration datasets is the lack of significant appearance variation, which does not adequately reflect the diversity encountered in clinical practice. The COph100 dataset, however, includes image pairs with substantial appearance differences resulting from variations in acquisition time, patient condition, and imaging environments. This diversity enhances the generalizability of registration algorithms, enabling them to perform more robustly in real-world clinical settings where image characteristics vary widely. Second, Pediatric pathologies focus: Existing datasets primarily focus on adult retinal pathologies, thereby neglecting the distinct features and challenges of pediatric retinal diseases. The COph100 dataset addresses this gap by concentrating on pediatric retinal pathologies, expanding the clinical relevance and applicability of registration algorithms beyond the adult population. Third, Scalability and population diversity: Current retinal image registration datasets are limited in scale, often involving fewer than 52 eyes, which can introduce bias in algorithm performance. In contrast, the COph100 dataset offers greater scalability and includes a more diverse patient population. This increased diversity provides a more robust basis for developing algorithms that are generalizable across different demographic groups, leading to improved clinical outcomes. Therefore, our proposed COph100 dataset represents a significant advancement in retinal image registration by providing a more diverse, pediatric-focused, and scalable dataset that improves the robustness and clinical applicability of registration algorithms.
Methods
Data Preparation
Image datasets
In this study, we aim to utilize publicly available retinal datasets to construct a comprehensive retinal image registration dataset. Our first step involves identifying datasets that include image pairs, varying poses or follow-up examinations, such as RODREP8, TeleOphta9, and a dataset proposed by Timkovic et al.1 (https://doi.org/10.6084/m9.figshare.c.6626162.v1). Certain datasets, like the 2021 Retinopathy of Prematurity (ROP) dataset20, which only contains images from different poses, are not considered for this study. We compare these dataset with FIRE, as shown in Table 2. The RODREP dataset, proposed in 2015, consists of fundus images from 70 diabetic patients with two examinations. TeleOptha, introduced in 2013, includes images from one or both eyes of healthy and diabetic retinopathy patients, with one or two examinations. The dataset proposed by Timkovic et al.1 in 2024 contains 2-9 examinations of premature infants with ROP. It includes images captured at three different resolutions by various devices, providing a diverse set of eyes. The image resolution for RODREP, TeleOphtha and two sections (1240 × 1240 and 1440 × 1080) of the Timkovic et al. dataset1 is relatively high.
Several factors were considered in selecting a suitable dataset for our challenging COph100 dataset. First, the dataset should include a large number of patient eyes. Second, it should contain images from patients with at least two examinations. Finally, the image resolution should not be excessively high, as high-quality retinal images are not always obtainable in clinical practice. Based on these criteria, we have decided to construct the challenging COph100 dataset using the lower-resolution images (640 × 480) from the dataset proposed by Timkovic et al.1.
Inclusion-exclusion criteria
Our study primarily focuses on image registration across multiple examinations, aiming to analyze disease progression over time. The specific selection criteria are outlined in Fig. 1. The original ROP grading dataset includes 396 eyes from 188 patients. To construct a more challenging registration dataset than FIRE, we deliberately selected images with greater appearance differences, such as variations in image resolution, illumination, compared to those in the FIRE dataset. Additionally, to assess disease progression effectively, we excluded patients with only a single examination, ultimately narrowing the dataset down to 118 eyes.

Summary diagram of inclusion-exclusion criteria.
Capturing retinal images from infants, unlike adults, poses significant challenges. Infants cannot follow instructions such as maintaining fixation on a point or keeping their eyes still, which complicates the process of obtaining high-quality fundus images. The resulting images often suffer from large occlusions caused by diseases or eyelids, poor focus, or significant rotation and translation between examinations, leading to limited image overlap. Furthermore, since physicians need to monitor changes in lesion areas over time during diagnosis, we made efforts to select image pairs that consistently include the lesion area at different time points. This selection process is intended to facilitate future analysis of disease progression. Ultimately, we obtained 100 eyes with 491 image pairs for our COph100 dataset.
Data processing
Registration Groundtruth
In image registration research, the evaluation of methods is typically conducted using both quantitative and qualitative metrics. Quantitative assessments often rely on either manually designated or automatically detected control points, which enable a concise representation of registration error as a single numerical value. Other quantitative methods, such as those that compute a transformation matrix, express error in terms of multiple parameters. On the other hand, qualitative evaluations focus primarily on the visual inspection of vessel alignment within the images, which necessitates expert input and lacks the ability to provide objective, quantitative comparisons across different registration techniques.
In the proposed COph100 dataset, we offer the actual corresponding points needed to compute registration errors, which are termed as control points, as illustrated in Fig. 2. For each eye, the location of a control point j in the image of first examination is denoted as E1j, and the corresponding point in the image of other examination i as Eij. The registration process uses the point Eij as input and transforms it to the new set of coordinates referred to as Mij. Thus, the Mij coordinates represent the post-registration positions of the Eij points. Ideal registration results in the points Mij and Eij being indistinguishable, with a pixel distance of 0 between them. In Fig. 2, each point corresponds to each other in all 9 examinations. The ground truth points are primarily marked around the vessel intersections.

Image from patient with 9 examinations. The challenges include blur, obstruction, large lesions, illumination and color changes.
Retinal Vessel Segmentation
The vessel structure plays a crucial role in analyzing the condition of the retina. To extract the vessel structure, we developed a vessel segmentation model based on SS-MAF21 (https://github.com/Qsingle/imed_vision). Following prior research22, we selected the green channel from the RGB image format as the input for the model, and we trained the model using the publicly available FIVES dataset23 (https://doi.org/10.6084/m9.figshare.19688169.v1). The training settings were consistent with21, where the 600 images in the training dataset were split with a 4:1 ratio for training and validation purposes. Upon training, the model achieved performance metrics of 91.56% in Dice score, 89.81% in sensitivity (SE), and 89.32% in bookmaker informedness (BM) at the test set of the FIVES dataset. The segmentation results are visualized in Fig. 3, demonstrating that the model successfully captures nearly all of the vessel structures. The collaborating opthalmologists also evaluated the segmentation results and concluded that they are sufficient for disease progression analysis. Since the original grading dataset proposed by Timkovic et al.1 includes a section on lesion segmentation, we did not extract the lesion areas separately in our study.

Visualization samples of Retinal vessel segmentation results.
Formulations for the evaluation metrics are as follows:
where TP, TN, FP, and FN are the true positive, true negative, false positive, and false negative respectively.
Data Records
The files available on Figshare24 (https://doi.org/10.6084/m9.figshare.27061084) and Github (https://gaiakoen.github.io/yanhu/research/Retinal_Image_Registration) include image folders, a data summary in xlsx format and a Python script for extracting corresponding images from the original dataset. Our COph100 dataset stands apart from the original classification dataset1 in three significant ways: Firstly, it is tailored for image registration to monitor disease progression, rather than for classification. Secondly, we have carefully selected a subset of images (325 out of 6,004) from the original dataset, following strict inclusion-exclusion criteria. Finally, we provide 10 point pairs for each image pair, complete with segmented vessel data, making this the largest publicly available retinal image registration dataset for infants to date.
The published dataset comprises 100 eyes, with a total of 491 pairs of images. The details of the examinations are listed in Table 3. There are 33 eyes containing 2 examinations, 43 eyes containing 3 examinations, 14 eyes containing 4 examinations, and so on. For the folder name, the folders labeled ‘003’ and ‘003-1’ indicate that we selected two eyes from the same patient. The folder labeled ‘04’ suggests that one of the patient’s eyes was not suitable for registration according to our inclusion and exclusion criteria. The structure of the files within our COph100 dataset is illustrated in Fig. 4. Taking the ‘005’ folder as an example, each patient undergoes three examinations, resulting in three distinct images. For each image, the corresponding data includes point pairs (stored in .json files), segmented vessel data (stored in .nii.gz files), vessel masks (stored in .png files), and vessel overlay images (also stored in .png files).

The details of our COph100 dataset files.
Technical Validation
Image quality evaluation
In order to compound the complexity of image registration tasks, certain artifacts are present in fundus images, which can significantly impact the training phase of registration algorithms. Research on color fundus image quality assessment exists25,26,27. However, these algorithms cannot be applied to our dataset due to unavailable code, privacy constraints, or differences between their datasets and our infant images. Consequently, our research team, in collaboration with professional ophthalmologists, has undertaken the evaluation of image quality. This study focuses on three primary challenges: (1) Blur, which is induced by eye movement or out-of-focus conditions; (2) Obstruction, caused by occlusion from disease-related lesions, hemorrhages, patient non-cooperation, probe rotation issues during capture, or turbid refractive media; and (3) Changes, encompassing disease progression, anatomical variations in the visual field, shifts in illumination and color, as well as spatial overlap.
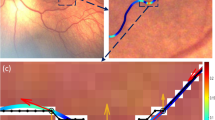
In our dataset of 100 eyes with 325 images, we assessed the quality of each image with respect to blur and obstruction, as well as variations within each eye. Many images presented with multiple challenges. Figure 5 provides statistics and examples illustrating the issues of blur and obstruction present in our dataset. Out of the 325 images, 213 images were affected by obstruction, and 100 images suffered from blur. A total of 82 images experienced both challenges simultaneously, with only 21 images being relatively clear. Consequently, we believe that overcoming the low accuracy of registration caused by obstruction and blur will be an important research challenge for the future. Figure 5(a),(b) depict images obstructed by turbid refractive media and hemorrhages, respectively. Figure 5(c) represents images affected by both blur and obstruction, while Fig. 5(d) illustrates the challenge of blur alone.

Statistics and examples of the challenge involving blur and obstruction.
Figure 6 presents the statistics and examples of the challenges related to changes observed in our COph100 dataset. Over half of the eyes exhibit various changes. In Fig. 6(a), the areas of obstruction differ between the two images, and there are notable rotational changes between them. In Fig. 6(b), the regions marked by arrows show differences. Prominent hemorrhages are present in the left image during the first examination, but they have almost resolved in the right image by the third examination.

Statistics and examples of the challenge involving changes.
Registration evaluation
To assess the registration performance of existing methods on our dataset, we follow the approach outlined in paper28 and report on three categories of results: the ratios of failed, inaccurate and acceptable registrations. For each pair of images in our dataset, the early examination image Iq is used as the query image, while the late examination image acts as the reference Ir. A registration attempt is classified as failed if the number of feature matches is less than 4. For successful registrations that obtain a homography, the quality is evaluated using two metrics: the Median Error (MEE) and the Maximum Error (MAE) of the distances between the matched points Mq in the query image and their corresponding estimated positions Er in the reference image. Registrations are deemed acceptable if both MEE is less than 20 and MAE is less than 50; otherwise, they are labeled as inaccurate. In addition to these measures, we report the Root Square Error (RMSE) for corresponding points after transformation within the acceptable category. Furthermore, we include the Area Under the Curve (AUC) metric18 to provide a comprehensive reflection of each method’s overall performance.
To comprehensively assess the performance of existing algorithms on our dataset, we conducted experiments based on traditional machine learning and deep learning based algorithms. Traditional algorithms include SIFT29, GDB-ICP30 (https://vision.cs.rpi.edu/gdbicp/exec/), REMPE31 (https://projects.ics.forth.gr/cvrl/rempe/). Deep learning-based algorithms include a multitude of algorithms trained on natural scene images (Superpoint32, GLAMpoints28, R2D233, SuperGlue34, LoFTR35) and specifically trained on fundus images (SuperRetina36, Swin U-SuperRetina37, LK-SuperRetina37, and SuperJunction19). We adopted the same testing method as the FIRE dataset, which involves using all the pre-trained models from the official platforms to test on the COph100 dataset.
Moreover, in light of the recent focus on vascular information in image registration studies, we have adopted a similar approach in our experiments. We utilize the segmentation results of image pairs as the query and reference images to specifically assess the performance of existing registration methods on vascular segmentation images. This choice allows us to evaluate the methods’ effectiveness in contexts where vascular alignment is crucial. Note that all our evaluations are conducted at the original image resolution of 640 × 480 pixels.
Table 4 summarizes the test results, where the values inside and outside the parentheses represent the results with and without segmentation information, respectively. For traditional methods, GDB-ICP demonstrates strong performance with the lowest failure rate (0%) and an inaccuracy rate of 22.20% when no segmentation is applied. It further enhances its performance on vascular segmentation images, achieving a low failure rate of 1.22% and decreasing the inaccuracy rate to 2.24%. When segmentation is used, its performance even surpasses that of the deep learning-based methods. SIFT shows a moderate improvement with segmentation, reducing both the failure rate (from 0.61% to 0%) and the inaccuracy rate (from 86.35% to 59.47%). In contrast, the REMPE method, which depends on 3D modeling of the fundus for registration, fails completely when segmentation information is used, as the segmentation data does not support the necessary 3D modeling process.
Deep learning methods such as SuperPoint, SuperGlue, LoFTR, and SuperJunction have delivered impressive results across all metrics. In contrast, methods including SuperRetina, Swin U-SuperRetina, and LK-SuperRetina have shown higher failure rates and inaccuracies, leading to poor overall performance. When segmentation results are incorporated, the performance of these models further declined, suggesting that models trained exclusively on the fundus dataset may lack robustness when applied to different datasets. Generally, methods trained in natural image environments have demonstrated improved accuracy with the addition of segmentation, except for SuperGlue. This discrepancy might be attributed to the fact that segmentation results can reduce the distinctiveness of descriptors in SuperGlue, which hinders effective matching. We noted that segmentation information tends to improve the registration accuracy for most methods, which underscores the potential benefits of exploring new strategies that more effectively integrate vascular segmentation data to enhance the performance of fundus image registration tasks. In Fig. 7, we present the registration results using a checkerboard mosaic visualization. It is evident that SIFT, GLAMpoints, and SuperRetina clearly failed. Even the other methods, despite performing better, still exhibit noticeable misalignments in the vascular structures compared to the ground-truth registration results. This highlights the need for registration methods to further improve accuracy and achieve complete alignment of the blood vessels in the images for more reliable outcomes. Therefore, the results from the table indicate that our proposed COph100 dataset represents certain challenges for both traditional machine learning and deep learning methods. There is considerable potential for enhancement in the future.

Mosaic visualization of registration results. (a) SIFT (b) GDB-ICP (c) REMPE (d) SuperPoint (e) GLAMpoints (f) R2D2 (g) SuperGlue (h) LoFTR (i) SuperRetina (j) Swin U-SuperRetina (k) LK-SuperRetina (l) SuperJunction.
Usage Notes
The COph100 dataset is intended to serve as a resource for researchers working in the field of medical image analysis, particularly those interested in image registration, disease progression analysis. The COph100 dataset presented in this paper can be downloaded through the link mentioned above.
Code availability
The code associated with this study are all publicly available. We do not develop any new code.SIFT detector plus RootSIFT descriptor, using OpenCV APIs.GDB-ICP, obtained from https://vision.cs.rpi.edu/gdbicp/exec/.REMPE, obtained from https://projects.ics.forth.gr/cvrl/rempe/.SuperPoint, trained on MS-COCO, obtained from https://github.com/rpautrat/SuperPoint.GLAMpoints, obtained from https://github.com/PruneTruong/GLAMpoints_pytorch.R2D2, obtained from https://github.com/naver/r2d2.SuperGlue, trained on ScanNet, obtained from https://github.com/magicleap/SuperGluePretrainedNetwork. LoFTR, obtained from https://github.com/zju3dv/LoFTR.SuperRetina, obtained from https://github.com/ruc-aimc-lab/superretina.Swin UNet and LK SuperRetina, obtained from https://github.com/NiharGupte/ReverseKnowledgeDistillation. SuperJunction, obtained from https://github.com/AdamWang0224/SuperJunction.SS-MAF, obtained from https://github.com/Qsingle/imed_vision.
References
Timkovič, J. et al. Retinal Image Dataset of Infants and Retinopathy of Prematurity. Scientific Data 11, 814, https://doi.org/10.1038/s41597-024-03409-7 (2024).
Avants, B. B., Epstein, C. L., Grossman, M. & Gee, J. C. Symmetric diffeomorphic image registration with cross-correlation: evaluating automated labeling of elderly and neurodegenerative brain. Medical Image Analysis 12, 26–41, https://doi.org/10.1016/j.media.2007.06.004 (2008).
Alam, F., Rahman, S. U., Ullah, S. & Gulati, K. Medical image registration in image guided surgery: Issues, challenges and research opportunities. Biocybernetics and Biomedical Engineering 38, 71–89, https://doi.org/10.1016/j.bbe.2017.10.001 (2018).
Javaid, F. Z., Brenton, J., Guo, L. & Cordeiro, M. F. Visual and ocular manifestations of Alzheimer’s disease and their use as biomarkers for diagnosis and progression. Frontiers in Neurology 7, 55, https://doi.org/10.3389/fneur.2016.00055 (2016).
James, A. P. & Dasarathy, B. V. Medical image fusion: A survey of the state of the art. Information Fusion 19, 4–19, https://doi.org/10.1016/j.inffus.2013.12.002 (2014).
Nie, Q., Zhang, X., Hu, Y., Gong, M. & Liu, J. Medical image registration and its application in retinal images: a review. Visual Computing for Industry, Biomedicine, and Art 7, 21, https://doi.org/10.1186/s42492-024-00173-8 (2024).
Pan, L. & Chen, X. Retinal OCT image registration: methods and applications. IEEE Reviews in Biomedical Engineering 16, 307–318, https://doi.org/10.1109/RBME.2021.3110958 (2021).
Adal, K. M., van Etten, P. G., Martinez, J. P., van Vliet, L. J. & Vermeer, K. A. Accuracy assessment of intra-and intervisit fundus image registration for diabetic retinopathy screening. Investigative Ophthalmology & Visual Science 56, 1805–1812, https://doi.org/10.1167/iovs.14-15949 (2015).
Decenciere, E. et al. TeleOphta: Machine learning and image processing methods for teleophthalmology. IRBM 34, 196–203, https://doi.org/10.1016/j.irbm.2013.01.010 (2013).
Ortega, M., Penedo, M. G., Rouco, J., Barreira, N. & Carreira, M. J. Retinal verification using a feature points-based biometric pattern. EURASIP Journal on Advances in Signal Processing 2009, 1–13, https://doi.org/10.1155/2009/235746 (2009).
Lee, J. A. et al. Registration of color and OCT fundus images using low-dimensional step pattern analysis. In *Medical Image Computing and Computer-Assisted Intervention - MICCAI 2015: 18th International Conference, Munich, Germany*, 214-221, https://doi.org/10.1007/978-3-319-24571-3_26 (2015).
Almasi, R. et al. Registration of fluorescein angiography and optical coherence tomography images of curved retina via scanning laser ophthalmoscopy photographs. Biomedical Optics Express 11, 3455–3476, https://doi.org/10.1364/BOE.395784 (2020).
Ding, L., Kuriyan, A. E., Ramchandran, R. S., Wykoff, C. C. & Sharma, G. Weakly-supervised vessel detection in ultra-widefield fundus photography via iterative multi-modal registration and learning. IEEE Transactions on Medical Imaging 40, 2748–2758, https://doi.org/10.1109/TMI.2020.3027665 (2020).
Martínez-Río, J., Carmona, E. J., Cancelas, D., Novo, J. & Ortega, M. Robust multimodal registration of fluorescein angiography and optical coherence tomography angiography images using evolutionary algorithms. Computers in Biology and Medicine 134, 104529, https://doi.org/10.1016/j.compbiomed.2021.104529 (2021).
Wang, C.-Y. et al. MEMO: dataset and methods for robust multimodal retinal image registration with large or small vessel density differences. Biomed. Opt. Express 15, 3457–3479, https://doi.org/10.1364/BOE.516481 (2024).
Ding, L. et al. FLoRI21: Fluorescein angiography longitudinal retinal image registration dataset. IEEE Dataport, https://doi.org/10.21227/ydp8-zf19 (2021).
Balaji Sivaraman, V. et al. RetinaRegNet: A Zero-Shot Approach for Retinal Image Registration. arXiv e-prints, https://doi.org/10.48550/arXiv.2404.16017 (2024).
Hernandez-Matas, C. et al. FIRE: fundus image registration dataset. Modeling and Artificial Intelligence in Ophthalmology 1, 16–28, https://doi.org/10.35119/maio.v1i4.42 (2017).
Wang, Y. et al. SuperJunction: Learning-Based Junction Detection for Retinal Image Registration. In *Proceedings of the AAAI Conference on Artificial Intelligence* 38, 292-300 (2024).
Agrawal, R., Kulkarni, S., Walambe, R. & Kotecha, K. Assistive framework for automatic detection of all the zones in retinopathy of prematurity using deep learning. Journal of Digital Imaging 34, 932–947, https://doi.org/10.1007/s10278-021-00477-8 (2021).
Qiu, Z. et al. Rethinking Dual-Stream Super-Resolution Semantic Learning in Medical Image Segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence 46, 451–464, https://doi.org/10.1109/TPAMI.2023.3322735 (2024).
Owler, J. & Rockett, P. Influence of background preprocessing on the performance of deep learning retinal vessel detection. Journal of Medical Imaging 8, 064001–064001, https://doi.org/10.1117/1.JMI.8.6.064001 (2021).
Jin, K. et al. Fives: A fundus image dataset for artificial Intelligence based vessel segmentation. Scientific Data 9, 475, https://doi.org/10.1038/s41597-022-01564-3 (2022).
Hu, Y. et al. COph100: A comprehensive fundus image registration dataset from infants constituting the “RIDIRP” database. figshare https://doi.org/10.6084/m9.figshare.27061084 (2024).
Fu, H. et al. Evaluation of retinal image quality assessment networks in different color-spaces. In *Medical Image Computing and Computer Assisted Intervention - MICCAI 2019*, 48-56, https://doi.org/10.1007/978-3-030-32239-7_6 (2019).
Liu, L. et al. DeepFundus: a flow-cytometry-like image quality classifier for boosting the whole life cycle of medical artificial intelligence. Cell Reports Medicine 4, 100912, https://doi.org/10.1016/j.xcrm.2022.100912 (2023).
Shen, Y. et al. Domain-invariant interpretable fundus image quality assessment. Medical Image Analysis 61, 101654, https://doi.org/10.1016/j.media.2020.101654 (2020).
Truong, P. et al. Glampoints: Greedily learned accurate match points. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 10732-10741, https://doi.org/10.1109/ICCV.2019.01083 (2019).
Lowe, D. G. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision 60, 91–110, https://doi.org/10.1023/B:VISI.0000029664.99615.94 (2004).
Yang, G., Stewart, C. V., Sofka, M. & Tsai, C. L. Registration of challenging image pairs: Initialization, estimation, and decision. IEEE Transactions on Pattern Analysis and Machine Intelligence 29, 1973–1989, https://doi.org/10.1109/TPAMI.2007.1116 (2007).
Hernandez-Matas, C., Zabulis, X. & Argyros, A. A. REMPE: Registration of retinal images through eye modelling and pose estimation. IEEE Journal of Biomedical and Health Informatics 24, 3362–3373, https://doi.org/10.1109/JBHI.2020.2984483 (2020).
DeTone, D., Malisiewicz, T. & Rabinovich, A. Superpoint: Self-supervised interest point detection and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 224–236, https://doi.org/10.1109/CVPRW.2018.00060 (2018).
Revaud, J., De Souza, C., Humenberger, M. & Weinzaepfel, P. R2D2: Reliable and repeatable detector and descriptor. Advances in Neural Information Processing Systems 32, https://doi.org/10.48550/arXiv.1906.06195 (2019).
Sarlin, P.-E., DeTone, D., Malisiewicz, T. & Rabinovich, A. SuperGlue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4938-4947, https://doi.org/10.1109/CVPR42600.2020.00499 (2020).
Sun, J., Shen, Z., Wang, Y., Bao, H. & Zhou, X. LoFTR: Detector-free local feature matching with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8922-8931, https://doi.org/10.1109/CVPR46437.2021.00881 (2021).
Liu, J., Li, X., Wei, Q., Xu, J. & Ding, D. Semi-supervised keypoint detector and descriptor for retinal image matching. In European Conference on Computer Vision, 593-609, https://doi.org/10.1007/978-3-031-19803-8_35 (2022).
Nasser, S. A., Gupte, N. & Sethi, A. Reverse knowledge distillation: Training a large model using a small one for retinal image matching on limited data. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 7778–7787, https://doi.org/10.1109/WACV57701.2024.00760 (2024).
Acknowledgements
This work was supported in part by The National Natural Science Foundation of China (82102189, 82272086 and 62401246), Shenzhen Stable Support Plan Program (20220815111736001), and Special Funds for the Cultivation of Guangdong College Students’ Scientific and Technological Innovation (“Climbing Program” Special Funds) (pdjh2024b331).
Author information
Authors and Affiliations
Contributions
Y.H. data collection and labelling, idea maker, image quality check and draft preparation; M.G. data labelling and experiments; Z.Q. image segmentation; J.L., H.S., X.Z. and H.L. data labelling, G.T. and image quality check; M.Y. and H.L. medical consultation, segmentation results and image quality check; J.L. supervision. All authors reviewed the manuscript and agreed to the submitted version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Hu, Y., Gong, M., Qiu, Z. et al. COph100: A comprehensive fundus image registration dataset from infants constituting the “RIDIRP” database. Sci Data 12, 99 (2025). https://doi.org/10.1038/s41597-025-04426-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-025-04426-w
