
Abstract
Rapid and accurate assessment of flood extent is important for effective disaster response, mitigation planning, and resource allocation. Traditional flood mapping methods encounter challenges in scalability and transferability. However, the emergence of deep learning, particularly convolutional neural networks (CNNs), revolutionizes flood mapping by autonomously learning intricate spatial patterns and semantic features directly from raw data. DeepFlood is introduced to address the essential requirement for high-quality training datasets. This is a novel dataset comprising high-resolution manned and unmanned aerial imagery and Synthetic Aperture Radar (SAR) imagery, enriched with detailed labels including inundated vegetation, one of the most challenging areas for flood mapping. DeepFlood enables multi-modal flood mapping approaches and mitigates limitations in existing datasets by providing comprehensive annotations and diverse landscape coverage. We evaluate several semantic segmentation architectures on DeepFlood, demonstrating its usability and efficacy in post-disaster flood mapping scenarios.
Similar content being viewed by others

Background & Summary
Flooding, recognized as one of the most frequent and devastating natural disasters globally, poses significant risks to human lives, infrastructure, and the environment1. Over the past five decades, there has been a notable acceleration in property loss and loss of life, increasing at rates of 6.3% and 1.5% per year, respectively, in 2016 alone, flooding affected over 74 million people, resulting in 4720 fatalities and economic losses exceeding $57 million2. Rapid and accurate assessment of flood extent and severity is crucial for effective disaster response, mitigation planning, and resource allocation3. Different flood mapping methodologies have been proposed that leverage the advancements in earth observation technologies to become indispensable tools for flood rescue operations and disaster assessment. Early methodologies built upon the global threshold method have shown efficiency in flood mapping using SAR images, where a specific threshold – a numerical value - is used to differentiate between flooded and non-flooded regions based on reflectance values4. However, accurately detecting floods through image segmentation with a single threshold remains challenging due to SAR’s complex characteristics5. To address this challenge, various threshold algorithms have been explored, including those based on regional differences or automatic approaches like Otsu and entropy thresholding6,7,8,9. Furthermore, the integration of change detection methods with the threshold approach has demonstrated enhanced flood detection effectiveness, especially for large-scale, near-real-time applications10,11. Despite these advancements, it’s important to note that both thresholding and change detection methods heavily rely on expert knowledge and require extensive satellite image preprocessing12,13,14. While these methodologies have shown success in specific flood events, they often lack transferability and reusability across different scenarios. However, with the advent of deep learning techniques, there has been a paradigm shift in flood mapping methodologies. Deep learning models, particularly convolutional neural networks (CNNs), have demonstrated remarkable capabilities in automatically learning complex spatial patterns and semantic features directly from raw data15. By leveraging large-scale labeled datasets, deep learning algorithms can effectively extract discriminative features and accurately classify flood-affected areas with minimal human intervention. The emergence of deep learning has revolutionized flood mapping by significantly improving accuracy, scalability, and efficiency compared to traditional approaches16,17. The ability to automatically learn hierarchical representations of flood features enables deep learning models to adapt to diverse environmental conditions, sensor characteristics, and temporal dynamics, thus enhancing the robustness and generalization capabilities of flood mapping systems. The success of deep learning-based flood mapping crucially depends on the availability of high-quality training datasets. These datasets serve as the foundation for training and evaluating deep learning algorithms, providing them with the necessary knowledge to accurately recognize flood patterns from remote sensing data18. The importance of a comprehensive and well-annotated flood dataset cannot be overstated, as it directly influences the performance and reliability of deep learning models in real-world applications.
Existing Dataset
In the realm of flood mapping, a variety of datasets have been proposed tailored for the training and validation of deep learning models specifically proposed for flood segmentation. In general, remote sensing data used for flood mapping consists of space-borne and airborne imageries. As for the former, optical and radar data have been widely adopted to extract inundation areas with high accuracy17,18,19,20,21,22,23,24,25,26 Optical satellite imagery, as proposed in several studies19,20,21,22, provides true-color (RGB) images enabling visual interpretation and automatic segmentation/classification to identify flooded areas. For instance, the European Flood Dataset20 comprises 3710 flood images related to the May/June 2013 Central Europe Floods. Among these, 3435 street view images were retrieved from the Wikimedia Commons Category, supplemented by an additional 275 manually collected water pollution images sourced from various social media platforms. The dataset includes annotations for three classes: flooding, depth, and pollution. The study presents an interactive image retrieval approach, evaluating baseline retrievals and relevant feedback methods such as query point movement, classification, metric learning, and feature weighting. Notably, the European Flood dataset lacks georeferencing and exhibits limited diversity in flood scenarios, potentially restricting its applicability to various flood types and severity levels. Addressing these limitations, Garcia et al. (2021) introduced the WorldFloods Dataset19, comprising flood extent maps trained on several convolutional neural network (CNN) architectures for flood segmentation. The dataset includes 422 flood extent maps and raw 13-band Sentinel-2 images at 10-meter resolution, covering 119 flood events occurring between November 2015 and March 2019. Additionally, rasterized reference labels for cloud, water, and land classes are provided. However, this dataset is not multi-source and suffers from inconsistent labeling of flood extents due to cloud cover, hindering its effectiveness for training accurate flood mapping models. To overcome these challenges, the Global Flood Database21 was introduced as a multi-source database providing global spatial flood event data derived from daily satellite imagery at 250-meter resolution. This database estimates flood water extent and population exposure for 913 large flood events occurring between 2000 and 2018 but the spatial and temporal resolution of the flood data is not sufficiently high to accurately capture localized or rapidly evolving flood events.
SAR data has emerged as a valuable alternative to optical data in flood mapping due to its ability to penetrate clouds, overcoming the limitations of optical sensors. Space-borne radar datasets utilized in17,23,24 employ visual interpretation, SAR backscattering value thresholding, change detection, and supervised SAR image-based approaches, along with region-growing methods and object-oriented image analysis techniques for flood segmentation. This characteristic renders radar a valuable option for distinguishing between flooded and non-flooded areas, providing an effective alternative to optical sensors.
Bonafilia et al.23 introduced the Sen1Floods11 dataset for training and validating deep learning algorithms for flood detection using Sentinel-1 imagery. The dataset comprises 4,831 chips measuring 512 x 512 pixels with a resolution of 10 meters, covering 11 distinct flood events. The ground truth of the dataset is represented by a binary mask indicating flooded and non-flooded areas.
Similarly, the dataset presented in17 is purposely designed for flood delineation, comprising 95 flood events distributed across 42 countries. It includes 1,748 Sentinel-1 acquisitions, pixel-wise DEM maps, hydrography information, and binary annotations of delineated flooded and non-flooded areas. The dataset offers images with input dimensions ranging from 531 × 531 pixels to 1944 × 1944 pixels.
Although both optical and radar satellite remote sensing have been proven effective in extracting flooded areas, they have inherent limitations in urban flood mapping. First, satellite remote sensing imagery of flooded areas may not always be available due to revisit limitations. Second, commonly used data sources such as Landsat and Sentinel-2 often fail to capture the details of complex urban landscapes due to their relatively lower spatial resolution. While high-resolution images like HISEA-1 SAR can provide richer information than Sentinel-1, their long revisit cycle and high-cost limit their application in urban flood monitoring. Additionally, processing radar data requires specialized knowledge and algorithms, adding complexity to the workflow. In contrast, aerial remote sensing offers distinct advantages for flood monitoring. It bypasses issues related to extensive cloud cover and limitations in revisit frequency, making it an ideal tool for this purpose. Moreover, aerial imagery provides higher resolution, capturing detailed information at decimeter and sub-decimeter levels, surpassing satellite data. For instance, the FloodNet dataset proposed by Rahmemoonfar, M. et al. in18 includes post-Hurricane UAV images of Hurricane Harvey. This dataset provides pixel-wise labeled images for semantic segmentation tasks, classification, and questions for visual question answering. It comprises video and imagery taken from several flights conducted between August 30 to September 04, 2017. However, this dataset is not geo-referenced, which makes it difficult to integrate with other sources of data for comprehensive flood mapping and analysis.
In contrast to the existing referenced datasets, our DeepFlood dataset offers high-resolution manned and unmanned aerial georeferenced images. with detailed labels beyond simple binary distinctions, such as identifying inundated vegetation, dry vegetation, open water, and others. This comprehensive labeling scheme significantly enhances the dataset’s applicability for flood mapping and analysis across diverse landscapes. Additionally, our dataset stands out for including SAR imagery alongside optical images, enabling a multi-modal approach to accurately delineate flooded areas. This study focused on vegetated areas stems from their critical role in flood dynamics and ecological impact assessment. Mapping inundated vegetation is essential for understanding flood impacts on agricultural lands, natural ecosystems, and water quality. These areas can influence flood propagation and contribute to long-term environmental recovery efforts. While detecting flooded infrastructure is crucial for immediate emergency response, our study addresses a complementary challenge by focusing on inundated vegetation, which is often underexplored but equally important for resource management and ecological assessments.
Additionally, it is very challenging to detect floods underneath the dense vegetation canopies (inundated vegetation) due to the limitations of optical sensors. since these flooded areas are simply not visible on the imagery. For flood-prone areas that are mostly covered by vegetation (e.g., North Carolina), it is essential to detect these areas to estimate the extent of the floods and to avoid the unseen floods that come from these areas protecting both human life and property. By focusing on this challenging task, our study aims to improve detection methodologies and address a key gap in flood mapping research27.
To summarize, the main contribution of our article is the introduction of a high-resolution (optical) and SAR imagery dataset named DeepFlood for post-disaster flood mapping. Our dataset, provided as big maps, can be tiled into tiles of preferred sizes by users. With our dataset, it is possible to create up to 20593 tiles with a tile size of 256 × 256 pixels. Additionally, we compare the performance of several semantic segmentation architectures on our dataset to demonstrate its usability. To our knowledge, this is the first dataset that contains labeling for inundated vegetation for both high-resolution optical and SAR imagery.
Methods
The success of any data-driven research endeavor heavily relies on the quality and relevance of the datasets utilized. In this section, we present the methodology employed for creating our dataset. The dataset creation process involves several steps, including data collection, preprocessing, and labeling. Each step is carefully designed to ensure the integrity, accuracy, and suitability of the dataset for our specific research tasks.
Study area
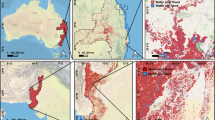
This study primarily focuses on North Carolina, a region highly susceptible to flooding events, particularly in areas with inundated vegetation. It examines six distinct areas in North Carolina that were significantly impacted by two major hurricanes: Grifton (Lenoir and Pitt Counties), Kinston (Lenoir County), and Princeville (Edgecombe County), affected by Hurricane Matthew; and Elizabethtown (Bladen County), Washington (Beaufort County), and Lumberton (Robeson County) impacted by Hurricane Florence. These study areas are illustrated in Fig. 1. Hurricanes Matthew and Florence serve as significant case studies for flood segmentation due to their severe impacts on the southeastern United States. Hurricane Matthew, which occurred in 2016, notably affected Haiti, Cuba, and the southeastern United States, including Florida, Georgia, South Carolina, and North Carolina28. Similarly, Hurricane Florence in 2018 brought record-breaking rainfall to North Carolina, with some areas receiving over 30 inches of rain. This resulted in widespread flooding, with floodwaters remaining for several weeks due to the storm’s slow-moving nature, significantly impacting various areas in the United States29. The extended flood duration and extensive flood extents from these hurricanes highlight the critical need for accurate flood segmentation techniques in disaster response and mitigation efforts.

Shows the six study areas with an Orthomap Generated by aerial Images.
Data collection
Our study utilized high-resolution post-disaster aerial imagery, sourced from both manned and unmanned platforms, covering multiple study areas affected by Hurricanes Matthew and Florence.
Town of Princeville, Edgecombe County:UAV imagery was collected during the flooding event caused by Hurricane Matthew in October 2016. This data was captured by North Carolina Emergency Management (NCEM) using a Trimble UX5 fixed-wing UAV. Each image consisted of three bands (RGB) with a remarkable spatial resolution of 2.6 cm and covered 10,816 m2 of land.
Grifton and Kinston: The National Oceanic and Atmospheric Administration (NOAA) Remote Sensing Division captured aerial photos covering more than 1,200 square miles of flooding and damage to support NOAA homeland security and emergency response requirements during Hurricane Matthew between October 7–16, 2016. From this data, we retrieved 14 images from the Grifton study area and 28 images from the Kinston study area. These aerial images caprysyred using a Trimble Digital Sensor System (DSS) at altitudes between 2,500 and 5,000 feet. The resulting imagery, with a ground sample distance (GSD) of 25 cm per pixel.
City of Lumberton, Robeson County: UAV imagery was collected immediately following the flooding event caused by Hurricane Florence in September 2018. This data was captured using a DJI M600 UAV. Each image consisted of three bands (RGB) with an exceptional spatial resolution of 1.5 cm, covering 1,159 m2 of land.
Elizabethtown and Washington: NOAA’s National Geodetic Survey collected damage assessment imagery from these areas in coordination with FEMA and other state and federal partners between September 15–22, 2018. We retrieved 90 image tiles for the Elizabethtown study area and 48 image tiles for the Washington study area. These images were captured using specialized remote-sensing cameras aboard NOAA’s King Air aircraft, flying at altitudes between 2,500 and 5,000 feet. With a GSD of approximately 25 cm per pixel, these images are available online via the NGS aerial imagery viewer and provide essential data for assessing damage to coastal areas, including ports, waterways, critical infrastructure, and coastal communities.
In addition to high-resolution optical imagery, we also retrieved optical images from Sentinel-2 and SAR (Synthetic Aperture Radar) images from Sentinel-1 Ground Range Detection (GRD) for the same events and selected areas. These images were acquired and downloaded from the Google Earth Engine platform, providing complementary data sources to enhance the comprehensiveness and utility of our dataset for flood mapping and analysis. Moreover, Sentinel -1A Single Look Complex (SLC) data with VV+VH polarization in Interferometric Wide Swath mode with a spatial resolution of 10m were acquired from the Alaska Satellite Facility30 to generate SAR Decomposition images. To ensure data relevance and coverage, both Sentinel-1 radar imagery and coincident Sentinel-2 optical imagery had to be captured on the same day or within a 2-day window of the aerial image acquisition. This strict criterion ensures temporal consistency and enhances the reliability of our dataset for subsequent analysis and modeling efforts Table 2.
Pre-processing
In the preprocessing step of our methodology, we undertake distinct steps tailored to the input type. Specifically, for Optical images, our initial step involves generating the orthophoto. The generation of orthophoto is vital as it provides a geometrically corrected representation of the aerial RGB images onto a uniform scale, ensuring accurate spatial analysis. This step facilitates precise measurements and enhances the interpretability of the data, laying a solid foundation for further analysis. Subsequently, in the case of SAR images, we filter corresponding Sentinel-1 SAR VV and SAR VH bands for pre and post-images of each hurricane event. This step ensures consistency and comparability in SAR data processing, facilitating accurate analysis of changes over time. Then, we implement Speckle filtering. This step enhances the quality of the SAR data, enabling more accurate analysis and extraction of meaningful information. Additionally, SAR Decomposition, using the Sentinel-1 SLC images provided detailed information about different scattering mechanisms within flood-affected areas. Preprocessing of the SLC images in the Sentinel Application Platform (SNAP) included importing data, applying orbit file, radiometric and terrain correction31, and applying the Refined Lee filter32 to obtain data in the required format. For optical Sentinel-2 images, our preprocessing includes cloud masking which helps to mitigate the impact of cloud cover on the analysis. By accurately identifying and masking cloud-covered areas, this preprocessing step ensures that only reliable and cloud-free pixels are included in subsequent analyses.
Semi-Automatic mask generation
The final step in creating our dataset is the mask generation step. The labeling aims to classify each pixel in the RGB images into one of four key classes, each contributing to a comprehensive assessment of the post-hurricane terrain. The classes include:
-
Open water - Areas characterized by visible water bodies, such as rivers, lakes, or standing floodwaters.
-
Dry Vegetation - Areas displaying vegetation that has not been affected by inundation, retaining its pre-event characteristics.
-
Inundated Vegetation - Vegetation zones visibly impacted by floodwaters, exhibiting signs of submersion or saturation.
-
Other - Areas encompassing all non-water and non-vegetation features, including built structures, roads, and other land cover types.
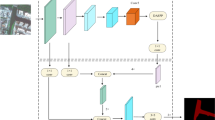
The mask generation step contains two main steps as shown in Fig. 2. The first one is auto mask generation based on pre-trained deep learning models. The second step is the manual correction step by experts. The use of semi-auto mask generation processes is crucial as it significantly reduces the time required to label pixels individually. By employing pre-trained deep learning models for automatic mask generation, large portions of the image can be classified rapidly, streamlining the labeling process and increasing efficiency. This semi-automatic approach not only saves time but also minimizes human error and ensures consistency in the labeling process. However, the manual correction process remains essential despite the efficiency gained from semi-auto mask generation. Manual correction allows for fine-tuning and validation of the automatically generated masks. It enables human expertise to address nuanced or ambiguous areas that may not have been accurately classified by the automated model. This manual intervention ensures the accuracy and reliability of the final labeled dataset, particularly in inundated vegetation areas Fig. 3.

Illustration depicting the two-step process of mask generation. The first step involves auto mask generation using pre-trained deep learning models, followed by manual correction.

Segmented Classes from the Deep Learning Model merged into Intended Individual Classes.
Auto mask generation
A high-resolution land cover classification segmentation model in ArcGIS Pro was employed for the auto mask generation step to initially segment the Optical image into 9 classes. This model utilizes the UNet architecture, trained on the 2013/2014 NAIP landcover dataset created by the Chesapeake Conservancy33 as well as other high-resolution imagery. The model requires 3-band high-resolution imagery, generating an output raster containing 9 classes with an overall accuracy of 86.5% for classifying the classes. The accuracy for each class is shown in the Table 3. Subsequently, individual classes were reclassified into 4 classes based on the study’s intended purpose. Upon inspecting the visual and spectral characteristics of the 9 classes, wetlands were reclassified as Inundated Vegetation (Class 0), Tree Canopy, Shrubland, and Low Vegetation were reclassified as Dry Vegetation (Class 1), Water was reclassified as Open Water (Class 2), and Barren, Structures, Impervious Surfaces, and Impervious Roads were reclassified as Other (Class 3).
Manual segmentation
To ensure high-quality annotations, we adopted an iterative annotation process, utilizing additional images as necessary for validation and evaluation across all classes. Our methodology incorporated a combination of Sentinel-1 VH and VV bands, SAR decomposition, and Water Index to highlight water features. During validation and evaluation, we found that inundated vegetation and Dry Vegetation classes were prone to misclassification, warranting concentrated effort in their manual annotation. In our manual correction process, we leveraged the Editing toolbox of ArcGIS Pro, employing tools such as create, modify, reshape, and split to enhance efficiency and precision in labeling.
Figure 4 shows the masks before and after the correction and highlights a specific region where the initial mask misclassified areas as open water and dry vegetation. The corrected mask accurately reclassifies these areas as inundated vegetation, demonstrating the improvements made through the correction process. Following polygon annotation for each class, we used the Dissolve tool in ArcGIS Pro’s Data Management Tools to aggregate geometries based on common value attributes. This facilitated the creation of a final raster mask spatially aligned with the optical image while preserving its pixel resolution. Each of the four classes was also exported as individual shapefiles for further analysis and integration into the dataset Fig. 5.

Masks before and after correction:. a) high-resolution imagery; b) the initial pre trained Unet segmentation mask (with areas misclassified as open water and dry vegetation); c) the corrected mask where these areas are accurately labeled as inundated vegetation.

Example of segmentation masks for two study areas. The first row shows an orthomap generated by optical images for the two study areas, while the second row displays their corresponding segmentation masks.
Data Records
The DeepFlood dataset and its auxiliary data features are openly accessible and available for download from the figshare cloud storage34. Each item within the repository follows a standardized naming convention:
“TrainingAreaName_HurricaneName_Day(00)_Month(00)_Year(00)_TileNum(00)”.
The repository’s contents and navigation guidelines are elucidated below and illustrated in Fig. 6.
-
Optical Folder: This folder contains the post-flood optical aerial images from Hurricanes Matthew and Florence with a spatial resolution of 25 cm and 15 cm.
-
GEOTIFF MASK Folder: This folder contains geo-referenced TIFF images representing label masks for all sites. The masks assign the following labels: 0 for inundated vegetation, 1 for dry vegetation, 2 for open water, and 3 for others.
-
SENTINEL_1 Folder: This folder includes the SAR decomposition, SAR_VH and VV bands, and the water index.
-
DEM Folder: The DEM folder encompasses Digital Elevation Model data for each site of the labeled data collection. The DEM data was obtained from the USGS 3DEP Lidar Explorer35with a spatial resolution of 1 meter.
-
SLOPE Folder: The SLOPE folder hosts generated Slope images for each training area, derived from the DEM data. These slope images maintain the same spatial resolution as the DEM (1 meter).
-
SHAPEFILES Folder: The SHAPEFILES folder houses label polygon shapefiles. Each area comprises three polygon shapefiles, including the polygon boundary, the final label shapefile, and individual label shapefiles. These shapefiles are organized within the ‘SHAPEFILES’ folder in the ‘DEEPFLOOD DATA’ directory. Sub-folders, named according to the training areas, contain three sub-folders each, hosting distinct polygon shapefiles:
-
Boundary Folder: Contains boundary shapefiles for each training area.
-
Final_label Folder: Holds label polygon shapefiles for each training area.
-
Individual_labels Folder: Contains individual label polygon shapefiles for each training area.
-
-
SENTINEL_2 Folder: This folder contains Optical Sentinel 2 imagery for each area with a spatial resolution of 10 meters.
-
Tiles Folder: This folder contains the tiles generated from the maps and is divided into the following subfolders:
-
Optical: Contains tiles of optical imagery.
-
Mask: Contains tiles of label masks.
-
SAR VV: Contains tiles of SAR VV band imagery.
-
SAR VH: Contains tiles of SAR VH band imagery.
-

Data repository navigation infogram.
Technical Validation
To further evaluate the quality of our datasets, we quantitatively assessed the final label masks for Hurricane Matthew and Hurricane Florence using reference flood extent maps created by the Nature Conservancy and the Arizona State University Center for Biodiversity Outcomes36. These reference data, developed in 2018, estimate the inland flood extent from both hurricanes to support sustainable planning and resilience efforts. The datasets comprise two classes: flooded and non-flooded regions, delineated from high-resolution NOAA aerial photography and other spatial datasets.
To compare our datasets with the reference maps, we reclassified the labels into two main classes; flooded (inundated vegetation and open water), and non-flooded (dry vegetation and other). We then overlaid the flooded regions from our datasets onto the reference flooded regions and estimated the overlay percentage coverage between the two datasets (see Table and Fig. 7. Our results indicated that the overlay percentage between the two datasets for the various study areas ranged between 87% and 96%, indicating a strong spatial accuracy

Illustration of the overlay accuracy estimation for the Kinston area.
Dataset robustness and reliability are pivotal factors in ensuring the efficacy of machine learning models. In the context of flood semantic segmentation, accurate delineation of inundated areas is vital for disaster response and mitigation efforts. In this section, we present the technical validation process undertaken to assess the quality of our proposed flood semantic segmentation dataset.
Dataset utility
To validate the dataset’s utility, we trained various deep-learning models using different input representations. Our validation process aimed to ensure that the dataset adequately represented numerous flood scenarios and verified the consistency of annotations. We explored different input representations to assess the dataset’s adaptability to diverse sensor modalities commonly encountered in flood monitoring applications. Through experimentation, we evaluated the performance of the trained models and gained insights into the strengths and weaknesses of different input representations. This analysis provided valuable information for optimizing the design of flood segmentation systems tailored to specific operational requirements.
The analysis of semantic segmentation models, presented in Table 1, is complemented by an evaluation of dataset usability, reflecting its efficacy for remote sensing applications. The dataset encompasses classes representing Inundated Vegetation (IV), Dry Vegetation (DV), Open Water (OW), and Other (Oth).
Across different architectures and input configurations, the dataset demonstrates varied usability, as reflected by segmentation performance metrics. Notably, UNet and UNet++ consistently exhibit superior segmentation accuracy compared to PSPNet, VNet, and AttUNet. The addition of Synthetic Aperture Radar (SAR) data (SARS1) alongside Red-Green-Blue (RGB) imagery notably enhances segmentation performance, particularly for UNet and UNet++ models.
The dataset’s efficacy is evident from the achieved mean Intersection over Union (mIoU) values, ranging from approximately 43.2% to 72.4%. The highest mIoU values are consistently observed with UNet and UNet++ models incorporating SAR data, indicating the dataset’s suitability for multi-modal data fusion tasks.
Furthermore, class-specific Intersection over Union (IoU) values provide insights into the dataset’s ability to accurately represent different land cover classes. The “IV” class exhibits varying IoU values across models and configurations, indicating the dataset’s capability to capture the complexities of inundated vegetation regions. For instance, with UNet and UNet++ models, IoU values for “IV” range from approximately 43.6% to 79.1%, showcasing the dataset’s effectiveness in delineating inundated vegetation.
Conversely, the “OW” class demonstrates lower IoU values, suggesting potential challenges in accurately delineating open water areas. IoU values for the “OW” class range from approximately 39.0% to 66.9%, indicating areas for dataset refinement to improve the representation of open water regions Table 4.
Precision and Recall values highlight the dataset’s ability to support accurate classification and detection of land cover classes. UNet and UNet++ models consistently achieve higher precision values, indicating fewer false positives, and favorable recall values, indicating fewer false negatives. For instance, precision values for UNet and UNet++ models range from approximately 75.8% to 93.9%, and recall values range from approximately 73.0% to 93.6%, underscoring the dataset’s effectiveness in training robust semantic segmentation models.
In summary, the evaluation of dataset usability alongside segmentation model performance emphasizes the dataset’s efficacy in facilitating accurate and reliable semantic segmentation tasks in remote sensing. The dataset’s multi-modal nature, incorporating both RGB and SAR data, enhances its utility for capturing diverse land cover characteristics, thereby contributing to advancements in remote sensing research and applications. Further refinements and annotations could enhance the dataset’s comprehensiveness and applicability for a wider range of remote sensing tasks. To better understand the utilization of the proposed dataset, we provide a comprehensive analysis of its components and examine the distribution of land cover types across the study areas. We utilize the National Land Cover Database (NLCD), which offers spatial data on land cover and land cover change across the United States, using a 16-class legend based on a modified Anderson Level II classification system37,38.
The chart in Fig. 8a represents the overall area percentage for each land cover class across all study areas. Woody wetlands (inundated vegetative areas) and forests dominate with 35% and 13% of the total area, respectively, representing the natural and semi-natural environments. These are followed closely by cultivated crops, which account for 22%, indicating the prevalence of agricultural activities. Developed, built-up areas cover 14% of the study areas, reflecting significant human influence. A detailed breakdown of land cover distribution among the four study areas is shown in Fig. 8b. The analysis reveals significant variation in land cover across the four areas (Grifton, Elizabethtown, Kinston, and Washington). Woody wetlands are most prevalent in Elizabethtown (approximately 55%), while they are less common in Washington (about 18%). Elizabethtown in Bladen County is well-known for its wetland areas, such as the Carolina Bays and riparian wetlands39. Washington has the highest percentage of open water (about 45%), substantially more than in other areas. Cultivated crops are most common in Grifton (around 36%), suggesting that agriculture is a primary land use in this region40, followed closely by Kinston (about 25%). Developed, built-up areas are most significant in Kinston (approximately 20%), indicating it may be the most urbanized of the four areas. Forest cover is highest in Elizabethtown (about 21%) and lowest in Washington (around 8%). Grifton and Kinston exhibit more balanced distributions of land cover types compared to Elizabethtown and Washington Table 5.

Land cover analysis: (a) Overall area percentage for each land cover class for all study areas; (b) Land cover distribution by area percentage across specific regions.
Applications: the Deepflood includes high-resolution raw images, annotations supplemental data(DTM, Water Index, Sentinel-1 SAR Decomposition, Sentinel-2 RGB, and Slope Map), and a detailed description of algorithms that were used to generate the data and tables. This provides transferability and reusability across different scenarios and for many other applications including:
-
Post-Disaster Assessment: Rapidly map flood extents to support emergency response, resource allocation, and damage assessment.
-
Urban Planning and Infrastructure Management: Identify flood-prone areas to improve planning and implement effective flood mitigation strategies.
-
Environmental Monitoring: Track changes in vegetation, water bodies, and topography over time to understand the long-term impacts of flooding.
-
Risk Assessment: Predict areas at high risk of flooding to enable preventive measures.
-
Evacuation Planning: Design effective evacuation plans and routes to ensure resident safety in flood-prone areas.
In addition, the dataset can serve as a benchmark for developing and testing new semantic segmentation algorithms and machine learning models in remote sensing and flood mapping. Two specific applications of the dataset have been demonstrated in our published works for identifying inundated vegetation and 3D flood mapping. Identifying inundated vegetation areas is critical for environmental monitoring and resource management. This helps assess the extent of flood impact on vegetation, affecting ecosystem health, agricultural productivity, and habitat stability. Accurate segmentation of these areas enables more precise flood response measures and long-term planning for vegetation recovery and management. 3D flood mapping also is very helpful in comprehensive flood impact assessment and mitigation planning. While the DeepFlood dataset offers a valuable benchmark for many applications, it is important to consider the discrepancy in spatial resolution between Sentinel-1 SAR images (10 meters) and RGB images (25 cm per pixel) when using the dataset, especially when the alignment and integration of these multi-modal and multi-resolution data sources are required. In addition, the mixed-class areas, such as transitions between dry and inundated vegetation, offer opportunities for refining segmentation techniques.Finally, We would like to mention that our current study did not include a separate evaluation of the dataset based on specific landscape coverage types or flood severity levels, as detailed information on these factors have not been available to the study.
Code availability
The code used to generate the initial mask for the datasets is based on the ArcGIS open-source high-resolution land cover classification deep neural network model. The instructions for use are available at the Geospatial and Remote Sensing Research Lab.
References
Jonkman, S. N. Global perspectives on loss of human life caused by floods. Natural Hazards 34, 151–175, https://doi.org/10.1007/s11069-004-8891-3 (2005).
Paterson, D. L., Wright, H. & Harris, P. N. A. Health Risks of Flood Disasters. Clinical Infectious Diseases 67, 1450–1454, https://doi.org/10.1093/cid/ciy227 (2018).
Di Baldassarre, G., Schumann, G., Brandimarte, L. & Bates, P. Timely low resolution sar imagery to support floodplain modeling: a case study review. Surveys in Geophysics 32, 255–269, https://doi.org/10.1007/s10712-011-9111-9 (2011).
Wangchuk, S., Bolch, T. & Robson, B. Monitoring glacial lake outburst flood susceptibility using sentinel-1 sar data, google earth engine, and persistent scatterer interferometry. Remote Sensing of Environment 271, 112910, https://doi.org/10.1016/j.rse.2022.112910 (2022).
Zhao, J. et al. A large-scale 2005-2012 flood map record derived from envisat-asar data: United kingdom as a test case. Remote Sensing of Environment 112338, https://doi.org/10.1016/j.rse.2021.112338 (2021).
Chen, S., Huang, W., Chen, Y. & Feng, M. An adaptive thresholding approach toward rapid flood coverage extraction from sentinel-1 sar imagery. Remote Sensing 13, 4899, https://doi.org/10.3390/rs13234899 (2021).
Nakmuenwai, P., Yamazaki, F. & Liu, W. Automated extraction of inundated areas from multi-temporal dual-polarization radarsat-2 images of the 2011 central thailand flood. Remote Sensing 9, 3607–3614, https://doi.org/10.3390/rs9010078 (2017).
Martinis, S. & Twele, A. A hierarchical spatio-temporal markov model for improved flood mapping using multi-temporal x-band sar data. Remote Sensing 2, https://doi.org/10.3390/rs2092240 (2010).
Lu, J. et al. Automated flood detection with improved robustness and efficiency using multi-temporal sar data. Remote Sensing Letters 5, 240–248, https://doi.org/10.1080/2150704X.2014.898190 (2014).
Chini, M., Hostache, R., Giustarini, L. & Matgen, P. A hierarchical split-based approach for parametric thresholding of sar images: Flood inundation as a test case. IEEE Transactions on Geoscience and Remote Sensing PP, 1–14, https://doi.org/10.1109/TGRS.2017.2737664 (2017).
Landuyt, L. et al. Flood mapping based on synthetic aperture radar: An assessment of established approaches. IEEE Transactions on Geoscience and Remote Sensing PP, 1–18, https://doi.org/10.1109/TGRS.2018.2860054 (2018).
Lin, L. et al. Improvement and validation of nasa/modis nrt global flood mapping. Remote Sensing 11, 205, https://doi.org/10.3390/rs11020205 (2019).
Shen, X., Anagnostou, E., Allen, G., Brakenridge, R. & Kettner, A. Near-real-time non-obstructed flood inundation mapping using synthetic aperture radar. Remote Sensing of Environment 221, 302–315, https://doi.org/10.1016/j.rse.2018.11.008 (2019).
Tiwari, V. et al. Flood inundation mapping-kerala 2018; harnessing the power of sar, automatic threshold detection method and google earth engine. PLoS ONE 15, https://doi.org/10.1371/journal.pone.0237324 (2020).
Chai, J., Zeng, H., Li, A. & Ngai, E. W. Deep learning in computer vision: A critical review of emerging techniques and application scenarios. Machine Learning with Applications 6, 100134, https://doi.org/10.1016/j.mlwa.2021.100134 (2021).
Bentivoglio, R., Isufi, E., Jonkman, S. N. & Taormina, R. Deep learning methods for flood mapping: a review of existing applications and future research directions. Hydrology and Earth System Sciences 26, 4345–4378 (2022). Copyright - © 2022. This work is published under https://creativecommons.org/licenses/by/4.0/ (the “License”). Notwithstanding the ProQuest Terms and Conditions, you may use this content in accordance with the terms of the License; Last updated - 2023-11-24.
Montello, F., Arnaudo, E. & Rossi, C. Mmflood: A multimodal dataset for flood delineation from satellite imagery. IEEE Access 10, 96774–96787, https://doi.org/10.1109/ACCESS.2022.3205419 (2022).
Rahnemoonfar, M. et al. Floodnet: A high resolution aerial imagery dataset for post flood scene understanding. CoRR abs/2012.02951 (2020). 2012.02951.
Mateo-Garcia, G. et al. Towards global flood mapping onboard low cost satellites with machine learning. Scientific Reports 11, https://doi.org/10.1038/s41598-021-86650-z (2021).
Barz, B. et al. Enhancing flood impact analysis using interactive retrieval of social media images. CoRR abs/1908.03361 (2019). 1908.03361.
Tellman, B. et al. Satellite imaging reveals increased proportion of population exposed to floods. Nature 596, 80–86, https://doi.org/10.1038/s41586-021-03695-w (2021).
Intizhami, N. S., Nuranti, E. Q. & Bahar, N. I. Dataset for flood area recognition with semantic segmentation. Data in brief 51, 109768 (2023).
Bonafilia, D., Tellman, B., Anderson, T. & Issenberg, E. Sen1floods11: a georeferenced dataset to train and test deep learning flood algorithms for sentinel-1. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 835–845, https://doi.org/10.1109/CVPRW50498.2020.00113 (2020).
Lv, S. et al. High-performance segmentation for flood mapping of hisea-1 sar remote sensing images. Remote Sensing 14, https://doi.org/10.3390/rs14215504 (2022).
Zhang, Y. et al. A new multi-source remote sensing image sample dataset with high resolution for flood area extraction: Gf-floodnet. International Journal of Digital Earth 16, 2522–2554 (2023).
Rambour, C. et al. Sen12-flood: a sar and multispectral dataset for flood detection. IEEE: Piscataway, NJ, USA (2020).
Hashemi-Beni, L. & Gebrehiwot, A. A. Flood extent mapping: An integrated method using deep learning and region growing using UAV optical data. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 14, 2127–2135, https://doi.org/10.1109/JSTARS.2021.3064325 (2021).
NOAA. National hurricane center tropical cyclone report, hurricane matthew https://www.nhc.noaa.gov/data/tcr/AL142016_Matthew.pdf (2017). Published Date April 7, 2017, accessed August 7, 2024.
NOAA. National hurricane center tropical cyclone report, hurricane florence https://www.nhc.noaa.gov/data/tcr/AL062018_Florence.pdf (2018). Published Date October 1, 2018, accessed August 7, 2024.
Facility, A. S. Sentinel-1 synthetic aperture radar (sar) data. https://asf.alaska.edu/datasets/daac/sentinel-1/ (2024). Accessed on March 1, 2024.
Small, D. Flattening gamma: Radiometric terrain correction for sar imagery. IEEE Transactions on Geoscience and Remote Sensing 49, 3081–3093, https://doi.org/10.1109/TGRS.2011.2120616 (2011).
Lee, J.-S. Refined filtering of image noise using local statistics. Computer Graphics and Image Processing 15, 380–389, https://doi.org/10.1016/S0146-664X(81)80018-4 (1981).
Esri. Deep learning model - land cover classification. https://www.arcgis.com/home/item.html?id=a10f46a8071a4318bcc085dae26d7ee4 (2024). Published Date December 7 2021, Accessed: July 25, 2024.
Fawakherji, M.Blay, J.Anokye, A.Hashemi-Beni, L., Dorton, J. DeepFlood High Resolution Dataset for Accurate Flood Mapping and Segmentationhttps://doi.org/10.6084/m9.figshare.26791243. (2024)
U.S. Geological Survey (USGS). 3DEP Lidar Explorer. https://apps.nationalmap.gov/3depdem (2023). Data accessed from the USGS 3DEP Lidar Explorer platform.
OneMap. Hurricane matthew flood extent across the piedmont and coastal plain of north carolina. Published Date 23 April 2018 Accessed: July 7, 2024, https://www.nconemap.gov/datasets/nconemap::hurricane-matthew-flood-extent-across-the-piedmont-and-coastal-plain-of-north-carolina/about
OneMap. National land cover database (nlcd) 2019 products https://data.usgs.gov/datacatalog/data/USGS:60cb3da7d34e86b938a30cb9 Version 3.0, accessed February 2024 (2021).
Hashemi-Beni, L., Kurkalova, L. A., Mulrooney, T. J. & Azubike, C. S. Combining multiple geospatial data for estimating aboveground biomass in north carolina forests. Remote Sensing 13, https://doi.org/10.3390/rs13142731 (2021).
WRAL. Thousands of acres of wetland forest being preserved in bladen county https://www.wral.com/story/2890876/ (2008). Accessed: 2024-07-29.
Blankenship, J.Understanding Residents’ Perceptions of FEMA Buyout Programs in Small Rural Municipalities: A Case Study of Grifton, North Carolina (East Carolina University, 2023).
Ronneberger, O., Fischer, P., Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. CoRR, abs/1505.04597, http://arxiv.org/abs/1505.04597 (2015).
Zhao, H., Shi, J., Qi, X., Wang, X., Jia, J. Pyramid Scene Parsing Network. CoRR, abs/1612.01105, http://arxiv.org/abs/1612.01105 (2016).
Milletari, F., Navab, N., Ahmadi, S. A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. CoRR, abs/1606.04797, http://arxiv.org/abs/1606.04797 (2016).
Zhou, Z., Siddiquee, M. M. R., Tajbakhsh, N., Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, pp. 3–11 (Springer International Publishing, Cham, 2018).
AL Qurri, A. & Almekkawy, M. Improved UNet with Attention for Medical Image Segmentation. Sensors 23, Article 8589, https://doi.org/10.3390/s23208589 (2023).
Acknowledgements
This work was supported in part by NOAA award NA21OAR4590358, NASA award 80NSSC23M0051, and NSF grant 1800768.
Author information
Authors and Affiliations
Contributions
M.F.: Conceptualization, Coordination, Methodology, Data handling and collection, Labeling review and verification, Technical validation, and Manuscript writing; J.B.: Methodology, Data handling and collection, Data Labeling, Labeling review and verification, Data analysis, and Manuscript writing; M.A.: Methodology, Data handling and collection, Data Labeling, Labeling review and verification, Data analysis, and Manuscript writing; L.H.-B.: Conceptualization, Coordination, Manuscript review, Funding acquisition, and Project administration; J.F.: Manuscript review.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Fawakherji, M., Blay, J., Anokye, M. et al. DeepFlood for Inundated Vegetation High-Resolution Dataset for Accurate Flood Mapping and Segmentation. Sci Data 12, 271 (2025). https://doi.org/10.1038/s41597-025-04554-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-025-04554-3
