
Abstract
Accurate flood forecasting in advance is crucial for planning and implementing watershed flood prevention measures. This study developed the PSO–TCN–Bootstrap flood forecasting model for the Tailan River Basin in Xinjiang by integrating the particle swarm optimisation (PSO) algorithm, temporal convolutional network (TCN), and Bootstrap probability sampling method. Evaluated on 50 historical flood events from 1960 to 2014 using observed rainfall-runoff data, the model showed, under the same lead time conditions, a higher Nash efficiency coefficient, along with lower root mean square and relative peak errors in flood forecasting. These results highlight the PSO–TCN–Bootstrap model’s superior applicability and robustness for the Tailan River Basin. However, when the lead time exceeds 5 h, the model’s relative peak error remains above 20%. Future work will focus on integrating flood generation mechanisms and enhancing machine learning models’ generalisability in flood forecasting. These findings provide a scientific foundation for flood management strategies in the Tailan River Basin.
Similar content being viewed by others
Introduction
Background
With the increasing impact of climate change and the rise in extreme weather events globally, flood forecasting has become an essential requirement for many countries and regions@@@1,2,3. Effective flood forecasting not only allows for early predictions of flood timing, location, and intensity, thereby mitigating flood damage, but also improves flood management efficiency and optimises resource allocation@@@4. However, the changing global climate is shifting precipitation patterns, increasing extreme weather frequency, and altering the spatial and temporal distribution of floods@@@5, creating substantial challenges for traditional flood forecasting models. Research shows a marked increase in extreme rainfall events, complicating future predictive accuracy even further@@@6. As a result, existing flood forecasting models must adapt to these changes, including recalibrating model parameters related to input variables such as precipitation, river levels, and surface evaporation rates to account for the randomness and uncertainty brought about by climate change@@@7. Specifically, researchers should leverage the latest climate data and technologies, such as artificial intelligence and machine learning, to improve model adaptability and accuracy. Additionally, future flood forecasting systems should incorporate more climate drivers, such as changes in ocean-atmosphere circulation patterns, land use transitions, and the effects of urbanization on flood basins@@@8. For instance, urbanization may exacerbate flooding by increasing surface runoff due to hardened surfaces, which alters flood flow paths@@@9. Therefore, the focus of future research will be on developing more efficient and accurate flood forecasting models and methods to meet the challenges posed by climate change, providing more reliable support for flood prevention and mitigation.
Literature review
The origins of flood forecasting technology date back to the 1930s, primarily relying on simple empirical formulas and hydrological models. Methods such as the unit hydrograph for deriving rainfall-runoff and the Muskingum method for river flood calculation were introduced in the United States, alongside the estimation of the S-curve for rainfall-runoff@@@10,11. During this period, research mainly focused on the simple relationship between rainfall and runoff, making forecasting relatively straightforward.Since the late 1950s, with the application of computation and systems theory, scholars have proposed various conceptual methods for hydrological simulation. These methods include hydrological models based on watershed hydrological processes and river hydraulics, such as the Sacramento model in the United States@@@12, the Xin’anjiang model in China@@@13, and the TOPKAPI model in Italy@@@14. Hydrological modeling has evolved significantly over time. The SCS-CN model, developed in the 1950s, was one of the earliest approaches to quantify the rainfall-runoff relationship and remains widely used for its simplicity. However, despite its simplicity, the SCS-CN model often faces limitations in predictive accuracy. Several modifications have been proposed to enhance its predictive abilities. Later advancements in mathematics and computer science facilitated the development of more sophisticated distributed hydrological models, such as the MIKE SHE model@@@15,16. Distributed models emphasise the physical processes of precipitation, surface, and subsurface interactions, enhancing quantitative analysis of the rainfall-runoff relationship. While these models have the potential to improve computational accuracy in hydrological processes, their effectiveness hinges on factors like data quality, model calibration, and specific watershed characteristics. In cases where these conditions are suboptimal, distributed models may not yield higher accuracy. By the late 1980s, with advancements in computing, remote sensing, and information technology, integrating remote sensing with geographic information systems (GIS) flourished. Hydrologists began to consider coupled hydrological, hydraulic, and environmental processes, marking a major developmental shift@@@17. Such models have enabled effective optimisation of water resource management at larger scales, particularly for complex river basins that span broad geographical regions and include multiple sub-basins@@@18,19. These expansive river basins demand comprehensive management strategies due to varied hydrological conditions and the need for coordinated water resource management across regions@@@18,19. Since the early 21st century, rapid developments in artificial intelligence technologies, such as neural networks and support vector machines, have been applied to flood forecasting. Hydrologists now leverage extensive meteorological and hydrological data, employing deep learning to refine rainfall-runoff models@@@20,21,22. As illustrated in Fig. 1, machine learning has become central in flood forecasting research, with keywords like ‘flood forecasting,’ ‘precipitation,’ and ‘streamflow’ closely linked to ‘machine learning’. This emphasis underscores the growing reliance on machine learning models to address the complexity and nonlinearity inherent in hydrological processes. Notably, the figure highlights frequent applications of models like LSTM, ANN, and Random Forest, underscoring their importance in managing time-series data and large datasets, which are crucial for improving flood prediction accuracy. Hybrid models that combine conceptual hydrological models with deep learning have gained significant traction among hydrologists. For instance, the TdCNN model, which employs a two-dimensional hidden layer architecture to capture the spatiotemporal characteristics of hydrological data, has demonstrated improved adaptability and accuracy in flood forecasting across various lead times@@@23,24. The complexity and nonlinearity of rainfall-runoff formation over time scales are well-documented@@@1,2,3. Existing conceptual hydrological models and supervised deep learning approaches often encounter generalisation challenges, leading to significant simulation errors in flood modelling@@@25. However, unsupervised deep learning can effectively capture the complex characteristics of highly nonlinear processes like rainfall-runoff@@@26. Research indicates that commonly used deep learning models for hydrological forecasting, such as LSTM (Long Short-Term Memory)@@@27,28,29, TCN (Temporal Convolutional Network)@@@21,22,30, and Transformer@@@31,32,33, generally exhibit more advanced theoretical foundations and architectures than traditional artificial neural networks, particularly in handling complex, nonlinear processes over extended periods. These models have shown superior forecasting accuracy in multi-period flood predictions. Additionally, the MHAFFM model, which combines a multi-head attention mechanism with multiple linear regression, has yielded substantial improvements in flood forecasting accuracy and stability over benchmark models, especially in managing prediction result oscillations and maintaining interpretability@@@23,24.

Co-occurrence network diagram of high-frequency keywords on the topic of flood forecast and machine learning.
Research gap and objective
As a relatively new application of time series prediction models in flood forecasting, the TCN has demonstrated promising potential@@@5,34. While TCN models have been effectively applied in other fields, their use in hydrology—particularly for flood prediction—remains in an exploratory phase. Wang et al.@@@5 developed a TCN-Attention model to predict daily average streamflow at the Huayuankou hydrological station, incorporating multiple influencing factors. Furthermore, Wang et al.@@@5 introduced dilated convolution to enhance high-order hydrological feature extraction, successfully applying the improved TCN model to the Lushui River Basin. Zhang et al.@@@35 coupled variational mode decomposition (VMD) with TCN to construct a VMD-TCN model, which was utilised to predict monthly runoff at the Xianyang and Huaxian hydrological stations in the Weihe River Basin. Most studies have focused on refining the TCN network structure to improve performance, yet have often overlooked the influence of hyperparameters on simulation accuracy@@@7. Hyperparameter selection not only affects simulation outcomes but also plays a critical role in the model’s overall processing speed. Currently, hyperparameter selection frequently depends on human experience and extensive experimentation, resulting in significant expenditures of manpower, time, and computational resources@@@36. Therefore, effective methods are needed to optimise the hyperparameters of machine learning models. To address this need, this study makes several key contributions: we propose a novel PSO–TCN flood forecasting model, which couples the TCN with the particle swarm optimization (PSO) algorithm to effectively optimize hyperparameters, thereby enhancing model accuracy and computational efficiency in flood prediction. Furthermore, we develop the PSO–TCN–Bootstrap hybrid model by incorporating the Bootstrap method to estimate the uncertainty of the model’s predictions, allowing for the generation of confidence intervals and providing a more robust flood risk assessment. The study applies the PSO–TCN model to the Tailan River Basin in Xinjiang for validation, comparing its performance against the traditional TCN model and demonstrating its potential to improve flood prediction accuracy and enable real-time responses to flood risks. Finally, we identify avenues for future research, including the application of the model in watersheds with varied hydrological characteristics and its potential for long-term flood risk analysis and water resource management.
Methods
Particle swarm optimization
PSO is a heuristic optimisation algorithm introduced by Eberhart and Kennedy in the late 20th century. This algorithm models the cooperative and competitive behaviour of individuals within a group by simulating the foraging behaviour of birds, effectively framing the problem as a group search for the optimal solution@@@37,38. In PSO, each candidate solution is referred to as a ‘particle’, with each particle characterised by position and velocity attributes. The algorithm iteratively optimises particle positions by updating velocity and position based on each particle’s own best-known position and the best-known position in its neighbourhood. Through these directional and distance adjustments, particles iteratively converge towards the optimal solution. PSO demonstrates robust global search capabilities and convergence properties, making it well-suited for continuous and discrete optimisation problems alike@@@39. The algorithm has been applied extensively across fields, including function optimisation, machine learning, and neural network training@@@36. The algorithm’s principle is outlined below@@@36.
Assuming that m particles in an N-dimensional space form a populationet, where \(x_{i} = \left[ {x_{i1} ,x_{i2} ,...,x_{iN} } \right]\), the feature of the i-th particle at time t is represented as follows:
In the equation, Xi and \(V_{i}^{t}\) represent the position and velocity of the particle, while \(P_{i}^{t}\) and \(P_{g}^{t}\) represent the individual best solution and the global best solution.
The updated position and velocity of the particle at time t+1 are given by:
In the equation, \(wV_{id}^{t}\) as the previous velocity of the particle, \(c_{1} r_{1}^{t} (p_{id}^{t} - x_{id}^{t} )\) as the cognitive component, which represents the particle’s own consideration, indicating the distance between the current position i and the local optimal position, \(c_{2} r_{2}^{t} (p_{gd}^{t} - x_{id}^{t} )\) as the “social” component, referring to information sharing and cooperation between particles, indicating the distance between the current position i and the global optimal position;\(V_{id}^{t + 1}\) as the d-dimensional component of the velocity vector for particle i in the t+1 iteration; w represents the inertia weight, c1 and c2 are learning factors within the range of [0, 2], and r1 and r2 are random numbers distributed between [0, 1]. The position and velocity of the particle are constrained within the range of [−Vmax, Vmax] and [−Xmax, Xmax] respectively.
Temporal convolutional networks
Temporal Convolutional Networks (TCNs) are a deep learning model designed for time series analysis@@@35. Unlike traditional Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs), TCNs leverage convolutional operations to capture sequential dependencies, allowing them to process multiple data points in parallel, which enhances their capacity to handle larger datasets efficiently and reduces training time. By incorporating dilated convolutions and residual connections, TCNs effectively manage long-term dependencies, mitigating issues like vanishing and exploding gradients@@@5. The core of TCNs lies in building the model through stacking multiple convolutional layers, where each layer’s input derives from the output of the previous layer, thereby extracting features from the data via convolution operations. Unlike conventional Convolutional Neural Networks (CNNs), TCNs typically employ a kernel size of 1, focusing exclusively on the current timestep’s features. This approach allows the model to capture essential information for future predictions while avoiding the complexities associated with processing multiple timesteps simultaneously@@@36. TCNs integrate residual connections and dilated convolutions to enhance model performance. Residual connections allow a convolutional layer’s input to be directly added to its output, improving the model’s learning of input–output relationships. Meanwhile, dilated convolutions expand the receptive field of the convolutional layers, enabling the model to capture long-range temporal dependencies. In hydrological forecasting, TCNs have demonstrated significant potential. By extracting high-order features from time series data through convolutional layers, they provide accurate predictions of floods, runoff, and river water levels. For instance, TCN models surpass traditional Artificial Neural Networks (ANNs) and LSTM models in flood forecasting, offering higher predictive accuracy and faster convergence speeds. In runoff prediction, TCN models have shown strong performance in studies on California watersheds, accurately reflecting the physical relationships between input variables and runoff@@@40.
In TCN, causal convolutions in one-dimensional form are used to ensure that the output has the same length as the input. For an input sequence q, the calculation formula@@@36 of the causal convolution F(T) at time step T is as follows:
In the equation, T represents the T-th time step, q is the input one-dimensional sequence, f is the convolution kernel, k represents the size of the convolution kernel, s represents the current time step or index of the input sequence q. Specifically, s serves as the reference point for the convolution operation, starting from the current time step T and qs-i represents the value in the sequence on which the convolution kernel operates.
The formula for dilated convolution is as follows:
In the equation, F(T) represents the dilated convolution operation on the sequence element s, q is the input one-dimensional sequence, d is the dilation factor, f is the filter, k represents the size of the filter, and s-d·i represents the past information direction.
From Fig. 2, it can be observed that the TCN network is composed of multiple residual blocks. Each residual block consists of two causal dilated convolutions, followed by weight normalization to accelerate the convergence speed of gradient descent. The calculation formula is as follows:

TCN network architecture.
In the equation, w represents the weight size, v represents a multi-dimensional vector, and g represents a scalar. The rectified linear unit (ReLU) activation function is then applied to introduce non-linearity between layers. The calculation formula is as follows:
Finally, dropout is added for regularization, randomly dropping neurons from the network with a certain probability to prevent overfitting. The calculation formula is as follows:
In Eq. (12), pf represents a composite function, where p refers to a dropout regularization operation to prevent overfitting, and f refers to an activation function such as ReLU, applied after the linear transformation wx. This helps introduce non-linearity into the model and regularize the network.
There are several reasons for applying PSO to the hyperparameter optimization of TCN in deep learning.Global Optimization Capability: PSO effectively explores the entire search space, avoiding local optima, which is an advantage over traditional methods like grid search or random search. Fast Convergence: PSO can quickly find suitable hyperparameter combinations through group cooperation and information sharing, accelerating the optimization process.Strong Adaptability: PSO demonstrates good adaptability when dealing with high-dimensional and complex problems, flexibly responding to various types of hyperparameters.Reduced Human Intervention: Automated hyperparameter optimization lowers the subjectivity of parameter selection, enhancing model performance.Suitable for Dynamic Environments: PSO can update and optimize hyperparameters in real time, adapting to data changes in scenarios that require frequent parameter adjustments.
Bootstrap method
The Bootstrap method is a interval prediction method proposed by American statistics professor Efron, which can effectively overcome the limitation of traditional point displacement prediction that can only obtain deterministic predicted values@@@41. This method is easy to calculate and implement, and is widely used in quantifying uncertainty interval predictions related to given estimates. The basic principle of Bootstrap is to perform equally probable repeated sampling with replacement on the original sample. By estimating the parameters from each resampled dataset, we can infer the approximate form of the empirical distribution. In this context, the term “empirical distribution” refers to the distribution inferred from the repeated samples, which approximates the underlying population distribution based on the original dataset@@@42. Given a set of samples: X1, X2,...,Xn from an unknown distribution F, with observed values x1, x2,...,xn, and \(\theta\) is a random variable dependent on X and F. Now, randomly sample with replacement from X, that is, the probability of a certain sample being selected for each sampling is 1/N, repeat sampling B times, generate B mutually independent Bootstrap samples, which can be represented as X*1, X*2,…, X*B, and construct the empirical distribution \(\overline{F}^{1}\), \(\overline{F}^{2}\),…, \(\overline{F}^{B}\) based on this; for the random variable \(\theta\), calculate the estimated values of B groups of Bootstrap samples \(\overline{\theta }_{1}\), \(\overline{\theta }_{2}\),…, \(\overline{\theta }_{B}\), then the estimate value is:
The estimate value of the Bootstrap sample variance is:
PSO–TCN–Bootstrap flood forecasting model.
The PSO–TCN–Bootstrap model involves three primary steps in the flood forecasting process, as illustrated in Fig. 3. The modelling steps are as follows: (1) Define the range for each hyperparameter, which includes six key parameters: the number of neurons, the number of hidden layers, the learning rate, block size, time step, and number of iterations. (2) Randomly initialise the position of each particle. Each particle’s position represents a multidimensional variable encompassing all hyperparameter dimensions. The NSE on the validation set serves as the objective function@@@43. At each iteration, update the particle positions until the maximum iteration count is reached to identify the optimal NSE of the TCN model. (3) Apply the Bootstrap-based uncertainty estimation method, coupling it with the output layer of the PSO-TCN model to form the second-layer output for flood forecasting. This step estimates the uncertainty in the model’s predictions by incorporating the Bootstrap method. By generating multiple resampled predictions, the Bootstrap method creates a distribution of predicted outcomes, which allows us to estimate prediction intervals and quantify the uncertainty in the flood forecasting results. This approach provides a probabilistic forecast rather than a single deterministic value, which helps to reflect the variability and uncertainty inherent in flood prediction.

PSO–TCN–Bootstrap model structure.
Model evaluation indicator selection
We evaluate the forecasting performance of TCN and PSO-TCN models using the Nash-Sutcliffe efficiency coefficient (NSE), root mean squared error (RMSE), and relative error (RE) for the runoff process@@@44,45. NSE serves as a holistic reflection of the flood prediction effectiveness, making it suitable as the objective function for parameter calibration, which is supported by numerous references, RMSE represents the error of runoff process simulation, and RE represents the error of peak flow simulation. The mathematical representations are as follows:
where \(Q_{{\text{ t}}}^{O}\) and \(Q_{t}^{S}\) represent the observed discharge and simulated discharge values, \(Q_{t - \max }^{O}\) and \(Q_{t - \max }^{S}\) represent the observed and forecasted peak floods, respectively. n represents the total number of hydrological sample data, and t represents the t-th time step. The NSE value ranges from (−∞, 1), with a higher value indicating higher prediction accuracy and the range of RMSE and RE is (0, +∞), and a smaller value closer to 0 indicates better prediction performance@@@46.
Case study
Study area
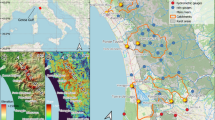
The Tailan River Basin is situated in Wensu County, Aksu region, Xinjiang, with geographic coordinates of 80° 21′ 44″~81° 10′ 14″ E and 40° 41′ 41″~42° 15′ 13″ N (Fig. 4). Originating from Tumur Peak in the southwestern Tianshan Mountains, the Tailan River has two main tributaries upstream: the Datailan River and the Xiaotailan River. These tributaries converge 8 km before the river exits the mountains, forming the main Tailan River. A hydrological station is positioned above the mountain pass, covering a watershed area of 1324 km2. The basin’s average annual temperature is 7.9 °C, with recorded extremes of 37.6 °C and −27.4 °C. The historical maximum annual precipitation reaches 336.7 mm, while the minimum is 18.7 mm, giving a rainfall extreme ratio of approximately 17@@@47. The Tailan River’s multi-year average runoff depth is 569.2 mm. Although annual runoff variability is minimal, its distribution across the year is highly uneven. The primary flood season spans June to August, with flooding events typically arising from a combination of rainfall and meltwater@@@48.

Geographical location of the study area and schematic diagram of rainfall stations distribution.
Processing of rainfall-runoff data
Rainfall-runoff data from 1960 to 2014 were collected and compiled, including rainfall data from three rain gauge stations and runoff data from the hydrological station at the outlet section of the Tailan River Basin. A total of 50 flood events were recorded, with a time interval interpolation of 1 h. All the data were extracted from the “Hydrological Yearbook of the Tailan River Basin”. The model training and validation were conducted based on a ratio of 7:3 for flood events@@@1,2,3, with 35 flood events used for training and 15 flood events used for validation. The rainfall-runoff data were normalized using the “maximum–minimum” method@@@38 to accelerate the convergence speed of the machine learning model during computation. The rainfall and flow data corresponding to each flood event were processed into a time-series feature dataset that can be recognized by the deep learning model, as shown in Table 1. \(P_{t}^{(1)}\), \(P_{t}^{(2)}\),…, \(P_{t}^{(m)}\) represent the rainfall amounts at time t in the m-th rainfall station from the first grid.
Model parameters setting
The hyperparameters of the TCN model include the number of neurons, number of hidden layers, learning rate, block size, time step, and number of iterations. In this study, the NSE was selected as the objective function, with the particle swarm optimisation algorithm applied to determine the optimal hyperparameter values for flood forecasting. Initial optimal ranges were referenced from previous literature@@@36, as follows: 16–256 (with intervals of 16) for the number of neurons, 1–5 (interval of 1) for hidden layers, 0.0001–0.1 (intervals of 0.0001, 0.001, 0.01, 0.1) for the learning rate, 16–160 (interval of 16) for block size, 4–8 (interval of 1) for time steps, and 150–350 (interval of 25) for the number of iterations. Seven lead times were set at 1 h, 2 h, 3 h, 4 h, 5 h, 6 h, and 7 h.
Lead time and model initialization settings
Parameter calibration revealed that the best predictions occur when the sliding window size is set to 6. Figure 5 illustrates the working mechanism of the TCN model with a sliding window input of 6 h and corresponding lead time settings, including 1 h, 2 h, 3 h, 4 h, 5 h, 6 h and 7 h. Q1 is predicted by \(P_{0}^{(m)}\), Q1 and \(P_{1}^{(m)}\) are then included in the new sliding window to predict Q2, and this process continues until the sliding prediction is completed.

Schematic diagram of lead time settings and Sliding window working mechanism.
Results and discussion
Overall accuracy evaluation
The results in Table 2 and Fig. 6 clearly highlight the superior performance of the PSO–TCN model over the TCN model in all evaluation metrics for flood forecasting in the Tailan River basin. Specifically, the PSO–TCN model consistently achieves higher NSE values in both the training and validation periods, with the difference becoming more pronounced at shorter lead times (e.g., 1 h, 2 h) and further widening as lead time increases. For instance, at a 1-h lead time, the NSE for the PSO–TCN model is 0.93, compared to 0.87 for the TCN model. Furthermore, the PSO–TCN model demonstrates significantly lower RE and RMSE values, reflecting its superior accuracy and lower error rates. At a 1-h lead time, the PSO-TCN model achieves an RE of 2.11%, markedly lower than the 5.66% observed for the TCN model, while the RMSE for PSO–TCN is 20.34 m3/s compared to 44.14 m3/s for TCN.

Radar chart of evaluation indicators for flood forecasting results in the Tailan River Basin.
The radar charts in Fig. 6 further strengthen this conclusion, offering a visual comparison between the models. Across all lead times, the PSO–TCN model (represented by the blue line) outperforms the TCN model (represented by the red line) in terms of NSE, RE, and RMSE during both the training and validation periods. This performance advantage is particularly evident at shorter lead times, though the PSO–TCN model maintains its superior performance even as lead times increase. These findings underscore the PSO–TCN model’s greater reliability and accuracy for flood forecasting in the Tailan River basin, especially when dealing with extended forecast periods.
Comparison results of typical flood events.
In order to further verify the forecasting performance of the model, a comparison analysis of the forecasting performance of the TCN model and the PSO–TCN model was conducted for a typical flood event with a large peak flow in the Tailan River basin (flood date: 19990714). Figure 7 and Table 3 show the evaluation metrics, including the NSE, RE, and RMSE, for the forecasted runoff process at different lead times. From the comprehensive perspective of Fig. 7 and Table 3, when the lead time is 1 h, the forecasted runoff process of the TCN and PSO–TCN models matches well with the observed runoff process, accurately reflecting the actual flood runoff process, and the accuracy of peak flow forecasting is also at a high level. The NSE is all greater than or equal to 0.85, and the RE is less than 10%. The advantage of the forecasting accuracy of the PSO–TCN model is not significant, but there is still a slight improvement. When the lead time is increased to 7 h, the forecast error of the TCN model significantly increases, especially underestimating the peak flow, with an NSE of 0.31, RE and RMSE reaching as high as 38.01% and 118.93 m3/s, respectively, while the corresponding values for the PSO–TCN model are 0.52, 24.76%, and 85.94 m3/s for these three indicators. Therefore, it is considered that the PSO–TCN model has better peak flow modeling capability, and the optimization algorithm can significantly improve the flood forecasting accuracy of the TCN model. From Fig. 7, it can be seen that the PSO-TCN model can fit the measured flow well in the 1–3 h lead time for land water basins, with the confidence intervals covering all measured flow points and narrow interval widths, indicating that the confidence intervals can effectively reflect the forecast uncertainty. The degree of fit between the forecasted and observed flood processes in the 4–7 h lead time has decreased, with significant fluctuations during the rising process. The confidence intervals gradually widen, indicating increasing forecast uncertainty, but the coverage rate still remains close to 95%.

Forecasting process of typical flood events in the verification period for TCN and PSO–TCN Models.
Advantages and limitations of the PSO–TCN–Bootstrap model
This study constructed a PSO–TCN–Bootstrap flood forecasting model by coupling the particle swarm optimization algorithm, the TCN temporal convolutional neural network, and the Bootstrap probability model, which can significantly improve the accuracy of flood forecasting under specific conditions. In particular, this method shows improved performance in short-term forecasting scenarios (1–3 h), complex flood processes characterized by non-linear hydrological responses, and when sufficient data are available to fully train the model@@@49,50. The PSO–TCN–Bootstrap model can reduce the relative error of peak flow forecasting and the root mean square error of flood process forecasting, while further enhancing the robustness of machine learning models. Based on comprehensive weighted calculations of simulation accuracy during the training period and verification period, compared with the TCN model, the PSO–TCN–Bootstrap model improves the average NSE by 0.07–0.10 and reduces the RE and RMSE by 2.85–3.67% and 19.79–20.19 m3/s, respectively, when the lead time is 1–3 h. When the lead time is 4–7 h, the PSO-TCN-Bootstrap model improves the average NSE by 0.11–0.21 and reduces the RE and RMSE by 4.01–6.45% and 22.03–23.97 m3/s, respectively. In the model calculation process, the PSO–TCN–Bootstrap model can significantly improve the calculation efficiency during the verification process and promote the convergence speed of model training, which is an important improvement in promoting advanced flood prediction. However, this study still cannot overcome the problem of decreasing accuracy of flood forecasting as the lead time increases. Future research will aim to integrate mechanisms of flood generation and improve model interpretability to further enhance the generalization ability of machine learning models in flood forecasting applications@@@51,52. To enhance the performance of the PSO–TCN–Bootstrap model over longer lead times, future research will explore the integration of numerical weather prediction models. These models will provide forecasted rainfall data as inputs to hydrological models, thereby extending the forecast period and improving the accuracy of long-term flood predictions. Furthermore, the application of data assimilation techniques, such as Kalman filtering, will be investigated to continuously adjust and update model predictions in real-time. This approach aims to mitigate the decrease in accuracy that often occurs as the lead time increases. Together, these strategies are expected to enhance the generalization capability and robustness of the model in practical flood forecasting applications. Traditional deep learning models provide only point estimates, resulting in limited uncertainty (or risk) information for flood decision-making. By adding Bootstrap to the output layer of the TCN, we achieve probabilistic interval predictions for flood forecasting, which offers more uncertainty information for flood management decisions.
Furthermore, the Bootstrap method typically requires a large number of repeated samples, and each sampling necessitates model training or computation, which can lead to significant computational overhead, especially when dealing with large datasets or complex models. Each Bootstrap sample generates a new dataset, and if the sample size is large, it may consume a lot of memory, affecting computational efficiency. In some cases, the convergence speed of Bootstrap estimates can be slow, particularly when the sample size is small or the feature dimension is high, requiring more sampling iterations to obtain reliable results. These are objective limitations of this study that need further refinement in future research.
Conclusion
This paper constructed a flood forecasting model for the Tailan River Basin by coupling particle swarm hyperparameter optimization algorithm, time-convolved Bootstrap probability sampling neural network. The model was verified based on 50 historical flood events, and the brief conclusions are as follows:
-
(1)
The overall accuracy of the PSO–TCN-Bootstrap flood forecasting model is better than that of the TCN model in the Tailan River Basin, and the peak error and root mean square error of the flood process are lower than those of the TCN model. The PSO–TCN–Bootstrap flood forecasting model has better applicability in the Tailan River Basin. PSO performs exceptionally well in handling high-dimensional and complex search spaces, effectively avoiding the local optimum issues that traditional gradient descent methods may encounter. Additionally, the parallel computing characteristics of PSO allow it to efficiently manage a large number of hyperparameters while reducing computational costs and time, significantly enhancing the model’s performance and training efficiency.
-
(2)
As the lead time increases, the flood simulation accuracy of the TCN and PSO–TCN–Bootstrap models will both decrease, but the TCN model shows a significant downward trend, while the PSO–TCN–Bootstrap model shows a slow downward trend. The PSO–TCN–Bootstrap model has better robustness than the TCN model. This study enhances flood forecasting by incorporating Bootstrap into the output layer of the TCN, enabling probabilistic interval predictions. This approach provides additional uncertainty information for flood prevention decisions, increasing the scientific basis and reliability of those decisions. However, the Bootstrap method typically requires a large number of repeated samples, with model training or computation performed after each sampling, which affects the overall computational efficiency.
-
(3)
When the lead time is 1–3 h, compared with the TCN model, the PSO–TCN–Bootstrap forecasting accuracy slightly improves; when the lead time is 4–7 h, the PSO–TCN–Bootstrap forecasting accuracy will significantly improve. However, when the lead time exceeds 5 h, the PSO-TCN-Bootstrap model’s RE will still exceed 20%. In the future, it is expected to integrate the mechanism of flood process occurrence and further improve the generalization ability of machine learning models in flood forecasting applications.
-
(4)
Future research can focus on parameter optimization algorithms and explore the application of flood process probability forecasting in scheduling, as well as study the impact of basin lag time and forecast horizon length on prediction accuracy. Additionally, it may be worthwhile to investigate the incorporation of extra constraints into the loss function of deep learning models to ensure that the performance of probability forecasts balances reliability and concentration.
Data availability
The datasets analvzed during the current study are not publiclv available but are available from the corresponding author onreasonable request.
References
Liu, C. et al. A watershed urban composite system flood forecasting model considering the spatial distribution of runoff patterns. Progress Water Sci. 34(04), 530–540 (2023).
Liu, C. et al. A rapid simulation method for urban rainfall and flood based on BIC-KMeans and SWMM. Water Resour. Protect. 39(05), 79–87 (2023).
Liu, C. et al. Study on flood forecasting model of watershed- urban complex systemconsidering the spatial distribution of runoff generation pattern. Adv. Water Sci. 34(04), 530–540. https://doi.org/10.14042/j.cnki.32.1309.2023.04.006 (2023).
Deng, C., Chen, C., Yin, X., Wang, M. & Zhang, Y. A watershed runoff simulation method that integrates data assimilation and machine learning. Adv. Water Sci. 1–11 (2024).
Wang, W., Hu, M., Zhang, R., Dong, J. & Jin, Y. An improved monthly runoff prediction model for the Lushui River Basin using time convolutional networks and long short-term memory networks. Comput. Integr. Manuf. Syst. 28(11), 3558–3575 (2022).
Beevers, L. River flashiness in Great Britain: A spatio-temporal analysis. Atmosphere 15, 1025. https://doi.org/10.3390/atmos15091025 (2024).
Du, Y. Research on Medium- and Long Term Runoff Forecasting Based on Machine Learning Combination Models (2022).
Yamamoto, K., Sayama, T. & Apip,. Impact of climate change on flood inundation in a tropical river basin in Indonesia. Progress Earth Planet. Sci. https://doi.org/10.1186/s40645-020-00386-4 (2021).
Toosi, A. S., Doulabian, S., Tousi, G., Calbimonte, G. H. & Alaghmand, S. Large-scale flood hazard assessment under climate change: A case study. Ecol. Eng. 147, 105765. https://doi.org/10.1016/j.ecoleng.2020.105765 (2020).
Cloke, H. L. & Pappenberger, F. Ensemble flood forecasting: A review. J. Hydrol. 375(3), 613–626. https://doi.org/10.1016/j.jhydrol.2009.06.005 (2009).
Lahijani, H., Leroy, S. A. G., Arpe, K. & Crétaux, J. F. Caspian Sea level changes during instrumental period, its impact and forecast: A review. Earth-Sci. Rev. 241, 104428. https://doi.org/10.1016/j.earscirev.2023.104428 (2023).
Chen, H. et al. Modeling pesticide diuron loading from the San Joaquin watershed into the Sacramento-San Joaquin Delta using SWAT. Water Res. 121, 374–385. https://doi.org/10.1016/j.watres.2017.05.032 (2017).
Zhao, J., Duan, Y., Hu, Y., Li, B. & Liang, Z. The numerical error of the Xinanjiang model. J. Hydrol. 619, 129324. https://doi.org/10.1016/j.jhydrol.2023.129324 (2023).
Sinclair, S. & Pegram, G. G. S. A sensitivity assessment of the TOPKAPI model with an added infiltration module. J. Hydrol. 479, 100–112. https://doi.org/10.1016/j.jhydrol.2012.11.061 (2013).
Pany, R., Rath, A. & Swain, P. C. Water quality assessment for River Mahanadi of Odisha, India using statistical techniques and artificial neural networks. J. Clean. Prod. 417, 137713. https://doi.org/10.1016/j.jclepro.2023.137713 (2023).
Sharma, A., Patel, P. L. & Sharma, P. J. Blue and green water accounting for climate change adaptation in a water scarce river basin. J. Clean. Product. 426, 139206. https://doi.org/10.1016/j.jclepro.2023.139206 (2023).
Martins, R., Leandro, J. & Djordjevic, S. Influence of sewer network models on urban flood damage assessment based on coupled 1D/2D models. J. Flood Risk Manag. 11, S717–S728. https://doi.org/10.1111/jfr3.12244 (2018).
Fan, Y., Ao, T., Yu, H., Huang, G. & Li, X. A coupled 1D–2D hydrodynamic model for urban flood inundation. Adv. Meteorol. https://doi.org/10.1155/2017/2819308 (2017).
Habert, J. et al. Reduction of the uncertainties in the water level-discharge relation of a 1D hydraulic model in the context of operational flood forecasting. J. Hydrol. 532, 52–64. https://doi.org/10.1016/j.jhydrol.2015.11.023 (2016).
Hader, J. D., Lane, T., Boxall, A. B. A., MacLeod, M. & Di Guardo, A. Enabling forecasts of environmental exposure to chemicals in European agriculture under global change. Sci. Total Environ. 840, 156478. https://doi.org/10.1016/j.scitotenv.2022.156478 (2022).
Xu, L., Chen, N., Chen, Z., Zhang, C. & Yu, H. Spatiotemporal forecasting in earth system science: Methods, uncertainties, predictability and future directions. Earth-Sci. Rev. 222, 103828. https://doi.org/10.1016/j.earscirev.2021.103828 (2021).
Xu, Y. et al. Application of temporal convolutional network for flood forecasting. Hydrol. Res. https://doi.org/10.2166/nh.2021.021 (2021).
Wang, Y. Y. et al. A novel strategy for flood flow prediction: Integrating spatio-temporal information through a two-dimensional hidden layer structure. J. Hydrol. 638, 131482. https://doi.org/10.1016/j.jhydrol.2024.131482 (2024).
Wang, W. et al. Prediction of flash flood peak discharge in hilly areas with ungauged basins based on machine learning. Hydrol. Res. 55, 801–814. https://doi.org/10.2166/nh.2024.004 (2024).
Castangia, M. et al. Transformer neural networks for interpretable flood forecasting. Environ. Modell. Softw. 160, 105581. https://doi.org/10.1016/j.envsoft.2022.105581 (2023).
Lara Benitez, P., Carranza Garcia, M., Luna Romera, J. M. & Riquelme, J. C. Temporal convolutional networks applied to energy related time series forecasting. Appl. Sci. Basel 10(7), 2322. https://doi.org/10.3390/app10072322 (2020).
Hu, C. H. et al. Deep learning with a long short-term memory networks approach for rainfall-runoff simulation. Water 10(11), 16. https://doi.org/10.3390/w10111543 (2018).
Sabzipour, B. et al. Comparing a long short-term memory (LSTM) neural network with a physically-based hydrological model for streamflow forecasting over a Canadian catchment. J. Hydrol. 627, 130380. https://doi.org/10.1016/j.jhydrol.2023.130380 (2023).
Sushanth, K., Mishra, A., Mukhopadhyay, P. & Singh, R. Real-time streamflow forecasting in a reservoir-regulated river basin using explainable machine learning and conceptual reservoir module. Sci. Total Environ. 861, 160680. https://doi.org/10.1016/j.scitotenv.2022.160680 (2023).
Qiao, X. et al. Metaheuristic evolutionary deep learning model based on temporal convolutional network, improved aquila optimizer and random forest for rainfall-runoff simulation and multi-step runoff prediction. Expert Syst. Appl. 229, 120616. https://doi.org/10.1016/j.eswa.2023.120616 (2023).
Xu, Y. et al. Deep transfer learning based on transformer for flood forecasting in data-sparse basins. J. Hydrol. 625, 129956. https://doi.org/10.1016/j.jhydrol.2023.129956 (2023).
Yin, H., Guo, Z., Zhang, X., Chen, J. & Zhang, Y. RR-former: Rainfall-runoff modeling based on transformer. J. Hydrol. 609, 127781. https://doi.org/10.1016/j.jhydrol.2022.127781 (2022).
Yin, H. et al. Rainfall-runoff modeling using long short-term memory based step-sequence framework. J. Hydrol. 610, 127901. https://doi.org/10.1016/j.jhydrol.2022.127901 (2022).
Wang, J., Gao, Z. & Dan, C. Multivariate Yellow River runoff prediction based on TCN attention model. People’s Yellow River 44(11), 20–25 (2022).
Zhang, S. et al. Research on monthly runoff prediction in the Wei River Basin based on VMD-TCN model. People’s Yellow River 45(10), 25–29 (2023).
Xu, Y. Research on Application of Deep Learning Based Flood Process Simulation and Forecasting (2022).
Luo, J., Zhang, X. & Jie, J. Reservoir flood control scheduling based on quantum multi-objective particle swarm optimization algorithm. J. Hydroelectr. Power Gener. 32(06), 69–75 (2013).
Li, W. et al. Construction and application of GRU Transformer flood forecasting model China Rural. Water Resour. Hydropower 11, 35–44 (2023).
Yu, Y., He, X., Zhang, X., Wan, D., Yang, Y. Research on similarity search method based on watershed daily rainfall map. J. Hohai Univ. Nat. Sci. Ed., 1–9 (2024).
Yuanhao, X. et al. Application of temporal convolutional network for flood forecasting. Hydrol. Res. https://doi.org/10.2166/NH.2021.021 (2021).
Song, S. et al. Short term photovoltaic power interval prediction based on MPA-LSTM model and Bootstrap method. J. Guangxi Univ. (Nat. Sci. Ed.) 47(04), 986–997 (2022).
Lin, P. Research on Landslide Displacement Interval Prediction Based on Bootstrap and Genetic Algorithm Optimized LSSVM (2023).
Gupta, H. V., Sorooshian, S. & Yapo, P. O. Status of automatic calibration for hydrologic models: Comparison with multilevel expert calibration. J. Hydrol. Eng. 4(2), 135–143 (1999).
Jackson, E. K. et al. Introductory overview: Error metrics for hydrologic modelling—a review of common practices and an open source library to facilitate use and adoption. Environ. Modell. Softw. 119, 32–48. https://doi.org/10.1016/j.envsoft.2019.05.001 (2019).
Moriasi, D. N. et al. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans. Asabe 50(3), 885–900. https://doi.org/10.13031/2013.23153 (2007).
Gupta, H. V., Kling, H., Yilmaz, K. K. & Martinez, G. F. Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modelling. J. Hydrol. 377(1–2), 80–91. https://doi.org/10.1016/j.jhydrol.2009.08.003 (2009).
Peng, D. Research on Land Use Change Characteristics and Ecological Effects in the Tailan River Basin of Xinjiang in the Past 15 Years (2009).
Wang, Z., Wang, X., Dan, M. & Geng, S. The impact of climate change on the annual average runoff of the Tailan River. Res. Arid Areas 31(01), 125–130 (2014).
Lin, Z. et al. Numerical simulation of flood intrusion process under malfunction of flood retaining facilities in complex subway stations. Build. Basel 12, 853. https://doi.org/10.3390/buildings12060853 (2022).
Zhou, Y. et al. Short-term flood probability density forecasting using a conceptual hydrological model with machine learning techniques. J. Hydrol. 604, 127255. https://doi.org/10.1016/j.jhydrol.2021.127255 (2022).
Lee, D. G. & Ahn, K. H. A stacking ensemble model for hydrological post-processing to improve streamflow forecasts at medium-range timescales over South Korea. J. Hydrol. 600, 126681. https://doi.org/10.1016/j.jhydrol.2021.126681 (2021).
Ni, C., Fam, P. S. & Marsani, M. F. A data-driven method and hybrid deep learning model for flood risk prediction. Int. J. Intell. Syst. 2024, 3562709. https://doi.org/10.1155/2024/3562709 (2024).
Funding
This work was funded by Major Science and Technology Project of Xinjiang Autonomous Region: Development Model and Intelligent Management and Control Technology of Ecological Agriculture in Modern Irrigation District (2023A02002-4); National Key Research Priorities Program of China, grant number 2023YFC3209303. Key Research and Development Project in the Autonomous Region: Key Technological Research on Flood Resource Utilization in Typical Basins in Xinjiang under Changing Environments (2023B02044-3); The Xinjiang Tianshan Talent Leadership Training Project (2022TSYCLJ0069).
Author information
Authors and Affiliations
Contributions
Q.Y. Conceptualization, Methodology, Formal analysis. C.L. Investigation, Data Curation, Writing—Review & Editing. Z.L. Software, Validation, Writing—Review & Editing. Y.B. Resources, Project Administration, Supervision. W.L., L.T., C.S., Y.X., B.C., J.Z., and C.H. Writing—Review & Editing. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yu, Q., Liu, C., Li, R. et al. Research on a hybrid model for flood probability prediction based on time convolutional network and particle swarm optimization algorithm. Sci Rep 15, 6870 (2025). https://doi.org/10.1038/s41598-024-80100-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-80100-2
