
Abstract
Glycans, nucleic acids and proteins are three major classes of natural biopolymers. The extremely high diversity of isomerization makes structural elucidation of glycans the most challenging job among three classes. In the past few years, the single molecule sensing technique based on nanopores has achieved great success in sequencing of DNA. Inspired by this, it is potential to sequence glycans in the similar manner. Herein, SiNx nanopores were used to identify nine common monosaccharides in mammals. Each monosaccharide showed characteristic blockage current, which roughly increased with the increase of its molecular weight. In order to distinguish nine monosaccharides, several machine learning models were trained and tested, of which the highest F1 value was 1. These results illustrated that nine common monosaccharides in mammals could be clearly identified and discriminate by our method combining solid-state nanopores and machine learning. As far as we know, this is the first report that monosaccharides can be sensed and distinguished by solid-state nanopores. Our work showed the great potential of solid-state nanopores in glycan sequencing, and would lay the foundation for solid-state nanopore-based glycan sequencing.
Similar content being viewed by others

Introduction
Glycans, nucleic acids and proteins are three major classes of natural biopolymers1. Besides their traditionally recognized roles as energy sources for living organisms, it is now well known that glycans play important signaling roles in a variety of physiological and pathological processes, including cell growth and proliferation2, immune responses3, angiogenesis and tumor cell metastasis4, protein folding and degradation5, cell-cell communications6, and cell-pathogen interactions7 etc. Identifying links between glycan structures and functions8, monitoring glycosylation in disease diagnosis and prognosis9, and elucidating molecular mechanisms of glycans with structural differences involved in pathogenesis10 are highlighted in current glycan-related studies. Therefore, developing precise, robust and sensitive methodologies for the analysis of glycans with definite structures is critical.
However, the extremely high diversity of isomerization makes structural elucidation of glycans a challenging job. The most frequently used methods for the structural analysis of glycans include capillary electrophoresis (CE)11, nuclear magnetic resonance spectroscopy (NMR)12, mass spectrometry (MS)13 and liquid chromatography (LC)14, etc., which are often combined with each other when being applied. Nevertheless, the limitations of above mentioned techniques are obvious. For instance, although it has been reported that glycan isomers can be distinguished by mass spectrometry, it still has some limitations15. CE and LC can’t provide structural information directly and require standard samples to obtain standard chromatogram16. NMR requires samples with high purity at milligram scale, but in most cases, it is difficult to obtain of pure glycan samples at milligram scale17. Recently, ion mobility chromatography combined with mass spectrometry (IM-MS) has made some progress in identification of carbohydrate isomers, but the resolving power of IM-MS remains to be improved18.
In the past few years, the single molecule sensing technique based on nanopores has achieved great success in DNA sequencing19 and peptide sequencing20. Inspired by this, it is potential to sequence glycans in a similar manner. At present, some preliminary attempts have been made to identify and sequence glycans based on nanopores. For example, polysaccharides like xylan21 and heparin22 were characterized by solid-state nanopores. In addition, it was reported that a series of human milk oligosaccharides (HMOs) modified with an aromatic group-containing tag were identified by a protein nanopore23. In order to realize de novo sequencing of glycans like nucleic acids, it is essential to discriminate different monosaccharides by nanopores. In 2018, an engineered α-hemolysin (α-HL) nanopore modified with a boronic acid was used to distinguish the individual sugar in a mixture of D-maltose, D-glucose, and D-fructose24. Afterwards, Huang et al. reported a hetero-octameric Mycobacterium smegmatis porin A nanopore modified with phenylboronic acid, which was able to clearly identify several monosaccharide types including D-fructose, D-galactose, D-mannose, D-glucose, L-sorbose, D-ribose, D-xylose, L-rhamnose and N-acetyl-D-galactosamine25. To our knowledge, so far there has been no precedent for using solid-state nanopores to identify and distinguish nine common mammal monosaccharides.
In this study, we characterized nine common monosaccharides in mammals through SiNx nanopores and utilized machine learning to identity and discriminate these monosaccharides. This work demonstrated here would lay the foundation for realizing solid-state nanopores-based de novo sequencing of glycans.
Materials and methods
Materials
Unless specified, all chemicals were of analytical grade. D-Glucose, D-galactose, D-N-acetyl-D-glucosamine, L-fucose, N-acetyl-D-neuraminic acid, D-mannose, D-glucuronic acid, D-xylose, D-N-acetylgalactosamine were purchased from Aladdin (Shanghai, China). KCl and Tris-EDTA buffer (pH = 8) were purchased from Sangon Biotech (Shanghai, China). Sodium hypochlorite was purchased from Sigma Aldrich (St. Louis, Missouri, USA). Twelve nm-thick free-standing SiNx membranes were purchased from Norcada, Canada.
Fabrication of solid-state nanopores
In the nanopore experiments, SiNx membranes were used. The nanopore capacitance is about 10 pF by coating PDMS on the chip. The SiNx membrane was first thinned by local electrochemical reaction assisted by a focused laser beam. Then chemically-tuned controlled dielectric breakdown (CT-CBD) was used for fabrication of nanopores26 in a mixture of 2:9 (v : v) sodium hypochlorite : 1 M KCl. After fabrication, the content was exchanged with pH 8.0 buffer (10 mM Tris-EDTA, 1 M KCl), and current-voltage (I-V) curves were obtained to check the quality of nanopores. I-V curves were generated by ramping the voltage from − 100 mV to + 100 mV and the pore size was estimated using the Equation.
In our experiments, the resistance of the nanopores was approximately 100 MOhm (Fig. S1). Polydimethylsiloxane gaskets were used to mount each nanopore chip between two custom-built polytetrafluoroethylene flow half-cells. All electrical signals were obtained using Ag/AgCl electrodes.
Detection of monosaccharides on solid-state nanopores
Once a single solid-state nanopore was fabricated, the monosaccharide in a pH 8.0 buffer (10 mM Tris-EDTA, 1 M KCl) was added into the cis compartment with a final concentration of approximately 3 µM (Fig. 1a). The traces of ionic current were recorded by a homemade preamplifier with bandwidth of about 30 kHz. The signal was then digitized at a rate of 1 MHz through an FPGA analog acquisition port, followed by a low-pass digital filter (bandwidth ~ 30 kHz) to further reduce the high-frequency noise. Unless otherwise stated, the applied voltage during all experiments was + 200 mV. Separate fresh nanopore device setups were used for each type of monosaccharide to physically exclude any cross contaminations and ensure that each data set is for a single type of monosaccharide.
Data analysis
All events were detected by custom-coded LabVIEW (version 2019, National Instruments) program. The algorithm for data processing referred to the previously published article27. Events with less than 30 µs or more than 100 ms in the dwell time or less than 10 pA in the blockade current were excluded, which were considered as noise or abnormal blockage. Subsequent analyses, including histogram plotting, scatter plot generation and curve fitting were performed by Origin 2021. For each class, results of three independent measurements were included. From the raw time-current trace, the start and the end time of each event was identified by our custom-coded LabVIEW (version 2019, National Instruments) program. The start and the end time acted as the marker to segment an event from the raw trace and was used to derive the dwell time of each event.
Extraction of event features
Extraction of event features was performed using MATLAB R2019a. The workflow was shown in Fig. S4. First, all events of monosaccharides were plotted together in terms of blockage current and dwell time and were divided into 9 bins using the equal frequency binning. The frequency of events of in each bin was calculated as the feature of each monosaccharide. The heat map was drawn according to above features of different monosaccharides. Secondly, the events of each monosaccharide were randomly divided into several subsets with an equal number of events. Jensen-Shannon divergence (JSD) was measured in order to evaluate the similarity between the distribution of subsets and total database when events were divided into subsets of different sizes. Finally, all subsets were normalized to the same nine states as above and the features of these subsets were obtained. Plotting in this part was performed by Origin 2021.
Machine learning
ML (machine learning)-based classifications were performed using Orange data-mining software (version 3.34.0). Seven machine learning algorithms were used, including AdaBoost, Gradient Boosting, kNN, Naive Bayes, Random Forest, SVM and Tree. For AdaBoost, the base estimator, classification algorithm, regression loss function were tree, SAMME.R. and linear respective. For Gradient Boosting, the number of trees, learning rate, limit depth of individual trees, split limit and fraction of training instances were 100, 0.1, 3, 2 and 1 respectively. For kNN, the number of neighbors was five, with a Euclidean metric and uniform weight. For Naive Bayes, the algorithm was typical. For Random Forest, the number of trees was 10 and the split limit was 5. For SVM, the cost, kernel, numerical tolerance, and iteration limit were 1, RBF, 0.001, and 100 respectively. For Tree, the minimal number of instance, split limit, maximal tree depth limitation and stop threshold were 2, 5, 100 and 95% respectively. The input data was randomly split into a training set (80% of the labelled dataset) for model training and a testing set (20% of the labelled dataset) for model testing. To avoid bias, 10-fold cross validation was applied during model training and evaluation. Following model development, the performance of ML models on unseen test datasets was evaluated and compared using the F1 value. In addition, the AUC, precision, and recall were calculated as well. Finally, the confusion matrixes of models were obtained.
Results and discussions
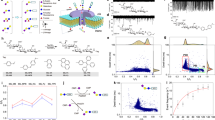
Considering the fact that N-acetyl-D-neuraminic acid (Neu5Ac), the dominant type of sialic acid, is a very common acidic nonose with negative charge and is a structurally complex monosaccharide (Fig. 1b), Neu5Ac was first chosen to verify the feasibility of detection of monosaccharides through solid-state nanopores. The measurement was performed with SiNx nanopore in a 1 M KCl, 10 mM Tris-EDTA, pH 8.0 buffer with the continuous application of a + 200 mV bias. The addition of 2 µM Neu5Ac to cis resulted in the consecutive appearance of resistive pulse events (Fig. 1c). Then the blockage events were processed to extract the blockage current ΔI and the dwell time Δt, which were used to characterize the blockage events of Neu5Ac statistically. Events with less than 50 µs or more than 100 ms in the dwell time were excluded. The blockage currents were fitted to single peak Gaussian distribution. Neu5Ac was characterized by a mean blockage current of 179.0 pA (Fig. 1d). Considering the fact that the SiNx membrane was first thinned by local electrochemical reaction assisted by a focused laser beam before nanopore was fabricated by the controlled dielectric breakdown (CDB) method, the effective thickness of the nanopore fabricated by CDB method may be much smaller than the thickness of the membrane. The effective diameter and thickness of the nanopore can be estimated as of 2.9 nm and 5.6 nm respectively (detailed calculation in Note 1 in the supporting information). In addition, the data showed no apparant signature of several molecules simultaneously in the nanopore during translocation. This is consistent with the low possibility of two molecules simultaneously in the nanopore during translocation, as estimated based on a Poisson distribution model for capture of molecules (detailed calculation in Note 2 in the supporting information).

Detection of N-acetyl-D-neuraminic acid (Neu5Ac) and D-glucose (Glc) with SiNx nanopores. (a) Schematic of the solid-state nanopore measurement. (Glc: Glucose; Gal: Galactose; GlcNAc: N-acetyl-glucosamine; Fuc: Fucose; Neu5Ac: N-acetyl-neuraminic acid). (b) The chemical structure of Neu5Ac. (c) The typical trace of Neu5Ac. (d) The scatter plot of ΔI-Δt and the histogram of ΔI of Neu5Ac. (e) The chemical structure of D-glucose. (f) The typical trace of D-glucose. (g) The scatter plot of ΔI-Δt and the histogram of ΔI of D-glucose.
In the same way, as a comparison, another very common uncharged monosaccharide – D-glucose (Glc) (Fig. 1e) as a representative of neutral monosaccharides was also tested by solid-state nanopores. After adding 3 µM D-glucose to cis, consecutive appearance of resistive pulse events was observed too (Fig. 1f). The blockage events were processed as above and fitted to single peak Gaussian distribution. D-Glucose was characterized by a mean blockage current of 92.1 pA (Fig. 1g), which was significantly different from that of Neu5Ac (179.0 pA). For the mechanism of charge neutral monosaccharides like glucose passing through nanopores, the contribution of diffusion to translocation of glucose is the dominant driving force instead of electroosmotic flow (detailed calculation in Note 3 in the supporting information). Since SiNx nanopores fabricated through chemically-tuned controlled dielectric breakdown had less negative charge on the surface26, the contribution of electroosmotic flow to molecular motion is negligible compared with diffusion, even though the direction of electroosmotic flow was opposite to the direction of molecular motion.
These results proved that both acidic monosaccharides such as Neu5Ac with negative charges and neutral monosaccharides like D-glucose without charges can be sensed and distinguished by SiNx nanopores. The feasibility of acidic and neutral monosaccharides sensed by SiNx nanopores was successfully demonstrated with Neu5Ac and D-glucose. Encouraged by these, we expected that the same principle could also be applied to sense other monosaccharides.
Human milk oligosaccharides (HMOs) are important components in human milk, which have important impact on infant survival, such as preventing pathogen attachment, reducing the infection risk, promoting brain development of infant, cultivating healthy gastrointestinal function, and so on28. HMOs are composed of five monosaccharides, including D-glucose, D-galactose (Gal), N-acetyl-D-glucosamine (GlcNAc), L-fucose (Fuc) and N-acetyl-D-neuraminic acid29.
Inspired by above results, the other three monosaccharides in HMOs were also tested by SiNx nanopores. The measurement was carried out as above in the presence of 3 µM of different monosaccharides. Just like Neu5Ac and D-glucose, resistive pulse events of D-galactose, N-acetyl-D-glucosamine and L-fucose were also observed, which were processed as above and fitted to single peak Gaussian distributions respectively (Fig. 2). D-Galactose, N-acetyl-D-glucosamine and L-fucose showed mean characteristic blockage currents of 108.9 pA, 127.6 pA and 86.8 pA respectively. Among the five monosaccharides of HMOs, their mean blockage currents showed the following order: Neu5Ac > GlcNAc > Gal > Glc > Fuc, suggesting that the characteristic blockage currents of monosaccharides roughly increased with the increase of their monosaccharide size or their molecular weight, while the dwell time didn’t show similar correlation (Fig. S2). For example, the blockage current of Neu5Ac was higher than those of the other four monosaccharides, while the blockage current of L-fucose was lower than those of the other four monosaccharides. But for isomers like D-glucose and D-galactose, there was also a slight difference in their blockage currents.

Detection of D-galactose (Gal), N-acetyl-D-glucosamine (GlcNAc) and L-fucose (Fuc) with SiNx nanopores. (a) The chemical structure of D-galactose. (b) The scatter plot of ΔI-Δt and the histogram of ΔI of D-galactose. (c) The chemical structure of N-acetyl-D-glucosamine. (d) The scatter plot of ΔI-Δt and the histogram of ΔI of N-acetyl-D-glucosamine. (e) The chemical structure of L-fucose. (f) The scatter plot of ΔI-Δt and the histogram of ΔI of L-fucose.
Inspection of the scatter plots of five monosaccharides also revealed the difference among them. However, a number of overlaps were observed in scatter plots (Fig. S3), leading to the difficulty in definitely identifying five monosaccharides by naked eyes. In recent years, machine learning, aiming to build computerized algorithms which can learn from data instead of focusing on the programming30, has been increasingly used as powerful tools to definitely identify analytes based on data obtained through solid-state or biological nanopores with subtle differences22,23,25. Thus, the machine learning-based classification approach was used to identify and discriminate monosaccharides based on the scatter plots of blockage current and dwell time. The process of machine learning contained feature extraction, model training and model testing.

Discrimination of five monosaccharides in HMOs by machine learning. (a) Equal frequency binning of the scatter plot from all events of five monosaccharides. (b) The normalized heat map of nine features of five monosaccharides. (c) Evaluation results of seven models in terms of AUC, F1, Precision and Recall scores. (d) Confusion matrix of Naive Bayes model.
In order to extract features of different monosaccharides, all events of five monosaccharides were plotted together in terms of blockage current and dwell time and divided into 9 bins using the equal frequency binning (Fig. 3a). With this approach, all events were classified into 9 total states: by dwell time as slow, intermediate, and fast events, and by blockage current as weak, moderate, and strong events. Thus, 9 features were generated by counting the frequency of events in each bin. The heat map of all features indicated a significant difference among five monosaccharides, which suggested that the extracted features can be used to distinguish five monosaccharides (Fig. 3b). Next, the events of each monosaccharide were randomly divided into several subsets with an equal number of events. Jensen-Shannon divergence (JSD) was measured in order to evaluate the similarity between the distribution of subsets and total database when all events were divided into subsets of different numbers (Fig. S5). Considering the event number of subsets and JSD, the events of each monosaccharide were divided into 10 subsets. Finally, the 50 subsets were normalized to the same nine states as above and the features of these subsets were obtained (Fig. S6).
Seven commonly used machine learning models were trained and tested, including AdaBoost, Gradient Boosting, kNN, Naive Bayes, Random Forest, SVM and Tree. During the process of model training and testing, the database was randomly split into two sets: 80% of data as a training set, and the remaining 20% used as a test set. Ten-fold cross validation was applied to avoid bias. According to the test scores of different models, most models gave very good performance. Among the seven models, kNN and Naive Bayes gave the highest F1 value as 100% (Fig. 3c). The confusing matrix of Naive Bayes model was produced (Fig. 3d), in which the accuracies of each monosaccharide were all 100%. In addition, these trained machine learning models were used to predict the measurement of Neu5Ac by another nanopore. Except for Tree with the lowest F1 value, all other models successfully predicted this measurement as Neu5Ac (Fig. S13). These results indicated that definite identification and discrimination of five monosaccharides in HMOs using our database measured with SiNx nanopores could be achieved by machine learning.

Detection of D-mannose (Man), D-glucuronic acid (GlcA), D-xylose (Xyl) and N-acetyl-D-galactosamine (GalNAc) with SiNx nanopores. (a) The chemical structure of D-mannose. (b) The scatter plot of ΔI-Δt and the histogram of ΔI of D-mannose. (c) The chemical structure of D-glucuronic acid. (d) The scatter plot of ΔI-Δt and the histogram of ΔI of D-glucuronic acid. (e) The chemical structure of D-xylose. (f) The scatter plot of ΔI-Δt and the histogram of ΔI of D-xylose. (g) The chemical structure of N-acetyl-D-galactosamine. (h) The scatter plot of ΔI-Δt and the histogram of ΔI of N-acetyl-D-galactosamine.
In addition to five monosaccharides in HMOs, there are another four common monosaccharides in mammals, including D-mannose (Man), D-glucuronic acid (GlcA), D-xylose (Xyl), N-acetyl-D-galactosamine (GalNAc). These four monosaccharides were also tested with single SiNx nanopores. Likewise, resistive pulse events of these four monosaccharides were also observed, and each monosaccharide exhibited a characteristic mean blockage current after resistive pulse events were processed as above (Fig. 4). The mean blockage events of these four monosaccharides further confirmed the previous observation about the rough relationship between the blockage current and the molecule weight of monosaccharides. As the smallest monosaccharide among these nine monosaccharides, the pentose – D-xylose had the minimal blockage current as 82.3 pA. For monosaccharide isomers, the blockage current of D-mannose (88.4 pA) was close to that of D-glucose (92.1 pA). And the blockage current of N-acetyl-D-galactosamine was 156.4 pA, which was slightly higher than that of N-acetyl-D-glucosamine (127.6 pA). While the molecular weight of D-glucuronic acid was higher than that of D-glucose and was negatively charged, the blockage current of D-glucuronic acid (99.9 pA) was slightly more than that of D-glucose (92.1 pA).
Like the above process of machine learning, the sensing data of these four monosaccharides were used to extract features, train model and evaluate model. All events of nine monosaccharides were plotted together in terms of blockage current and dwell time and divided into 9 bins using the equal frequency binning (Fig. 5a). The heat map of features demonstrated a significant difference among nine monosaccharides (Fig. 5b). The above seven models were evaluated again with a larger database containing events of nine monosaccharides. Among the seven models, SVM gave the highest F1 value as 100% (Fig. 5c). The confusing matrix of SVM model was produced, in which the accuracies were all 100% (Fig. 5d). Therefore, these events of nine monosaccharides can be fully discriminated by machine learning even though there were overlaps in the scatter plot. As far as we know, this would be the first discovery that nine common monosaccharides in mammals have been identified and discriminated by solid-state nanopores.

Discrimination of nine monosaccharides in mammals by machine learning. (a) Equal frequency binning of the scatter plot from all events of nine monosaccharides. (b) The normalized heat map of nine features of nine monosaccharides. (c) Evaluation results of seven models in terms of AUC, F1, Precision and Recall scores. (d) Confusion matrix of SVM model.
Summary
In summary, nine common monosaccharides in mammals showed characteristic blockage currents respectively on solid-state nanopores, which roughly increased with the increase of their molecular weights. For the first time, the current study demonstrated that identification and distinguishment of nine common monosaccharides in mammals with high accuracy using solid-state nanopores can be achieved with the help of machine learning. This work would lay the foundation for sequencing glycans in mammals using solid-state nanopores.
Data availability
All data in the manuscript is available through the responsible corresponding author.
References
Wen, L. et al. Toward automated enzymatic synthesis of oligosaccharides. Chem. Rev. 118, 8151–8187 (2018).
Varki, A. Biological roles of glycans. Glycobiology 27, 3–49 (2017).
Crocker, P. R., Paulson, J. C. & Varki, A. Siglecs and their roles in the immune system. Nat. Rev. Immunol. 7, 255–266 (2007).
Lou, Y. W. et al. Stage-specific embryonic antigen-4 as a potential therapeutic target in glioblastoma multiforme and other cancers. Proc. Natl. Acad. Sci. U.S.A. 111, 2482–2487 (2014).
Parodi, A. J. Role of n-oligosaccharide endoplasmic reticulum processing reactions in glycoprotein folding and degradation. Biochem. J. 348, 1–13 (2000).
Cannon, K. S. & Helenius, A. Trimming and readdition of glucose to n-linked oligosaccharides determines calnexin association of a substrate glycoprotein in living cells. J. Biol. Chem. 274, 7537–7544 (1999).
Kato, K. & Ishiwa, A. The role of carbohydrates in infection strategies of enteric pathogens. Trop. Med. Health. 43, 41–52 (2015).
Dennis, J. W., Nabi, I. R. & Demetriou, M. Metabolism, cell surface organization, and disease. Cell 139, 1229–1241 (2009).
Peracaula, R., Barrabes, S., Sarrats, A., Rudd, P. M. & De Llorens, R. Altered glycosylation in tumours focused to cancer diagnosis. Dis. Markers. 25, 207–218 (2008).
Freeze, H. H. & Aebi, M. Altered glycan structures: the molecular basis of congenital disorders of glycosylation. Curr. Opin. Struct. Biol. 15, 490–498 (2005).
Guttman, A. Multistructure sequencing of n-linked fetuin glycans by capillary gel electrophoresis and enzyme matrix digestion. Electrophoresis 18, 1136–1141 (1997).
Wyss, D. F. et al. Conformation and function of the n-linked glycan in the adhesion domain of human cd2. Science 269, 1273–1278 (1995).
Morelle, W. & Michalski, J. C. Analysis of protein glycosylation by mass spectrometry. Nat. Protoc. 2, 1585–1602 (2007).
Royle, L. et al. HPLC-based analysis of serum n-glycans on a 96-well plate platform with dedicated database software. Anal. Biochem. 376, 1–12 (2008).
Lee, J. et al. Deciphering mouse brain spatial diversity via glyco-lipidomic mapping. Nat. Commun. 15, 13 (2024).
Marino, K., Bones, J., Kattla, J. J. & Rudd, P. M. A systematic approach to protein glycosylation analysis: a path through the maze. Nat. Chem. Biol. 6, 713–723 (2010).
Emwas, A. H. M. The strengths and weaknesses of nmr spectroscopy and mass spectrometry with particular focus on metabolomics research. Methods Mol. Biology (Clifton N J). 1277, 161–193 (2015).
Hofmann, J., Hahm, H. S., Seeberger, P. H. & Pagel, K. Identification of carbohydrate anomers using ion mobility-mass spectrometry. Nature 526, 241– (2015).
Chen, K. K., Gularek, F., Liu, B. Y., Weinhold, E. & Keyser, U. F. Electrical DNA sequence mapping using oligodeoxynucleotide labels and nanopores. ACS Nano. 15, 2679–2685 (2021).
Brinkerhoff, H., Kang, A. S. W., Liu, J. Q., Aksimentiev, A. & Dekker, C. Multiple rereads of single proteins at single-amino acid resolution using nanopores. Science 374, 1509– (2021).
Cai, Y. et al. A solid-state nanopore-based single-molecule approach for label-free characterization of plant polysaccharides. Plant. Commun. 2, 9 (2021).
Im, J., Lindsay, S., Wang, X. & Zhang, P. M. Single molecule identification and quantification of glycosaminoglycans using solid-state nanopores. ACS Nano. 13, 6308–6318 (2019).
Li, M. M. et al. Identification of tagged glycans with a protein nanopore. Nat. Commun. 14, 12 (2023).
Ramsay, W. J. & Bayley, H. Single-molecule determination of the isomers of d-glucose and d-fructose that bind to boronic acids. Angew. Chem.-Int. Ed. 57, 2841–2845 (2018).
Zhang, S. Y. et al. A nanopore-based saccharide sensor. Angew Chem. -Int Edit. 61, 11 (2022).
Bandara, Y. et al. Beyond nanopore sizing: improving solid-state single-molecule sensing performance, lifetime, and analyte scope for omics by targeting surface chemistry during fabrication. Nanotechnology 31, 11 (2020).
Plesa, C. & Dekker, C. Data analysis methods for solid-state nanopores. Nanotechnology 26, 7 (2015).
Bode, L. et al. Overcoming the limited availability of human milk oligosaccharides: challenges and opportunities for research and application. Nutr. Rev. 74, 635–644 (2016).
Chen, X. In Advances in Carbohydrate Chemistry and Biochemistry. Vol. 72, 113–190 (eds Baker, D. C. & Horton, D.) (Elsevier Academic Press Inc, 2015).
Carral, A. D., Ostertag, M. & Fyta, M. Deep learning for nanopore ionic current blockades. J. Chem. Phys. 154, 10 (2021).
Acknowledgements
This work was financially supported by the National Natural Science Foundation of China (No. 21877114, No. 92353304, No. 91753136, and No. 21961142021).
Author information
Authors and Affiliations
Contributions
Y.D. and X.L. conceived the project. Y.S., Z.M., and X.C. performed the measurements. Y.S. designed the machine-learning algorithms. Z.M. set up the instruments. Y.S. and J.L. wrote the manuscript. S.L., and X.S. provided inspiring discussions. All authors have given approval to the final version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Sun, Y., Mi, Z., Chen, X. et al. Identification of nine mammal monosaccharides by solid-state nanopores. Sci Rep 14, 32000 (2024). https://doi.org/10.1038/s41598-024-83690-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-83690-z
