
Abstract
This study aims to address the shortage of manpower and resources in the medical engineering departments of healthcare institutions while efficiently executing medical equipment maintenance and achieving controllable maintenance costs. In the absence of historical maintenance data, this research uses multi-parameter monitors as a case study. The methodology integrates Fault Tree Analysis (FTA) with the Fuzzy Analytic Hierarchy Process (FAHP) to combine expert judgments and address uncertainties in failure data. The results of this integration are then converted into a Bayesian Network (BN) for probabilistic reasoning and failure analysis. This comprehensive approach enables both qualitative and quantitative analysis of monitor failures across different usage stages (early, mid-term, and late). The analysis encompasses determining the failure probability at each stage, identifying high-risk components, examining the transition of failure modes, gaining insights into the aging characteristics of components, and developing preventive maintenance strategies. A cost-benefit analysis is conducted based on specific practical cases. This methodology successfully identified the failure probability of each component of the monitor at various stages, accurately pinpointed high-risk components, and provided a clear analysis of the transition of failure modes. Following one year of practical application, a significant reduction in costs was observed after implementing this method. The proposed approach effectively addresses the issue of low maintenance efficiency of medical equipment stemming from inadequate manpower and resources. It is particularly advantageous for healthcare institutions in developing countries and smaller medical facilities, significantly enhancing maintenance efficiency while controlling maintenance costs.
Similar content being viewed by others

Introduction
The growing complexity of medical devices has significantly improved clinical outcomes1,2, however, it also presents substantial maintenance challenges, particularly in resource-limited settings3,4. Predictive and condition-based maintenance strategies have increasingly replaced traditional preventive approaches to minimize downtime and reduce costs5. Nevertheless, their implementation in developing countries faces systemic barriers6. For instance, 70% of donated medical equipment in Sub-Saharan Africa is non-functional due to a lack of trained personnel and unavailable spare parts7, while 50% of medical devices in low-income regions remain out of service8. These issues, compounded by fragmented manufacturer support and lengthy logistical delays9, highlight the urgent need for cost-effective and innovative solutions to balance maintenance quality and affordability.
In the field of medical equipment management, numerous studies have concentrated on the critical issue of medical equipment maintenance. Many prior investigations have conducted in-depth analyses of specific medical devices, yielding a series of valuable findings. For instance, Pinho, M. et al.10 proposed a multi-criteria ranking method for ventilators, thereby opening new avenues for their maintenance management. Li, J. et al.11utilized information fusion technology to deliver effective solutions for the maintenance and quality control of large medical equipment. Mellado-Silva, R. et al.12 designed a flow shop scheduling program aimed at addressing the challenge of arranging maintenance plans for medical equipment in public hospitals, with the primary goal of eliminating equipment downtime and minimizing total downtime. Hunte, J. L. et al.13employed a hybrid bayesian network to perform risk management on defibrillators. Lu, Q.P. et al.14 introduced the quality control circle to reduce both the downtime and frequency of linear accelerators. Verma, A. et al.15 conducted a comprehensive assessment of the failure probabilities of automatic blood analyzers throughout their life cycles. Additionally, beyond the application of specific technologies to analyze historical data, some researchers have also assessed medical equipment failures by drawing on expert experience. For example, 16 biomedical engineering technicians evaluated the failure modes and impacts of anesthesia machines16. Ayres-de‐Campos, D. et al.17collected information from various clinical and commercial sources to gain a comprehensive understanding of the availability of affordable basic obstetric equipment with low maintenance costs. They then conducted a systematic analysis of the maintenance costs associated with obstetric and gynecological medical equipment, providing a valuable reference for optimizing the allocation of maintenance resources. Taghipour, S. et al.18 precisely classified the failure types of infusion pumps and constructed an effective data analysis strategy at both the system and component levels, which aids in accurately identifying failure patterns of infusion pumps and implementing targeted maintenance measures. Despite the fruitful outcomes of the aforementioned studies, they do have certain limitations. On one hand, they did not fully address the issues of insufficient historical maintenance data and the excessive subjectivity inherent in expert judgments19,20. On the other hand, most studies tended to employ qualitative and quantitative analysis methods in isolation, failing to achieve comprehensive integration, which resulted in an incomplete understanding of the failure mechanisms21. Additionally, many studies overlooked the changes that occur at different stages of the medical equipment life cycle, where failure modes and probabilities may vary significantly22.
In light of these limitations, this study proposes a medical equipment maintenance strategy that effectively integrates qualitative and quantitative analysis methods, closely aligned with the actual operating conditions of medical institutions. This strategy aims to mitigate the subjectivity in expert judgments while considering the characteristics of different stages of the equipment life cycle, thereby enhancing the understanding of failure mechanisms and developing more effective maintenance strategies.
This study plans to adopt the analytic hierarchy process (AHP)23 and the fuzzy set method24, both of which have demonstrated effectiveness in various fields, to integrate diverse expert opinions and minimize uncertainties25,26. Specifically, by assigning weights to expert opinions based on their educational backgrounds, work experiences, and professional ranks, a more accurate aggregation of insights can be achieved. To address the subjectivity in expert judgment and the absence of sufficient historical data, this study combines fault tree analysis (FTA) and fuzzy AHP(FAHP), followed by a transformation into a Bayesian Network (BN)27. This integrated approach combines the system decomposition capabilities of FAHP-FTA28,29,30, the probabilistic reasoning advantages of BN, and the uncertainty management capabilities of fuzzy logic, thereby enabling effective handling of complex failure data and the uncertainties associated with expert judgments31,32,33.Furthermore, by examining different stages of the equipment life cycle (early, mid, and late stages), this study aims to formulate targeted maintenance strategies that optimize maintenance work and allocate resources effectively, ensuring the reliable operation of the equipment throughout its entire life cycle.
This paper presents a comprehensive analysis of strategies aimed at enhancing the maintenance of medical equipment. Utilizing the multi-parameter monitor at 3201 hospital as a case study, the research addresses practical aspects, including the integration of expert opinions through the application of the FAHP method. The study thoroughly considers expert perspectives from various dimensions, such as education and professional background, to improve the consistency and reliability of judgments. The integrated FAHP -FTA-BN method involves constructing a FTA model, which is then converted into a BN. This approach effectively tackles the challenges posed by uncertainty and imprecise data, thereby offering a more comprehensive and accurate pathway for analyzing failure probabilities. Additionally, the analysis based on life cycle stages entails a detailed investigation of the unique failure modes and probabilities associated with medical equipment at different stages of its life cycle, facilitating the development of more precise maintenance strategies. The formulation of these strategies is grounded in the analytical results derived from the life cycle stages, with the aim of enhancing efficiency and reducing costs while specifically addressing particular failure modes and resource constraints. Finally, empirical studies conducted in actual medical environments seek to validate the practicality and effectiveness of this method in minimizing maintenance costs and improving equipment reliability. By establishing a systematic analysis framework, this study aspires to provide feasible practical solutions for medical institutions facing limitations in equipment maintenance resources, thereby laying a solid foundation for the future advancement of medical equipment maintenance.
Methods
To provide a clearer understanding of the research steps, a flowchart of the research steps, as shown in Fig. 1, is presented in this paper.

Flowchart of Research Steps.
Structure of multi-parameter monitors
Multi-parameter monitors are essential emergency medical devices widely used in hospitals. They continuously monitor vital signs in real time, including electrocardiograms (ECG), blood oxygen saturation, non-invasive blood pressure (NIBP), respiration, pulse, and body temperature. In addition to monitoring, they offer storage, display, analysis, and alarm functions. These devices significantly enhance the efficiency of medical staff and help maintain a high standard of medical care.
The main components of a multi-parameter monitor include signal acquisition, analog signal processing, digital signal processing, signal display, recording, and alarm systems. The signal acquisition components gather critical physiological signals via bioelectrodes and sensors, such as ECG, NIBP, and blood oxygen saturation, converting them into electrical signals. Analog signal processing components then refine these signals using circuits for impedance matching, filtering, and amplification, which effectively reduce noise and interference, thereby enhancing the signal-to-noise ratio.
The digital signal processing components primarily consist of an analog-to-digital converter, a microprocessor, and memory units. The analog-to-digital converter transforms analog signals into digital form. The memory stores operating programs, configuration data, and temporary data, while the microprocessor receives control information from the control panel and executes corresponding programs. Signal display, recording, and alarm components provide a user-friendly interface for information exchange between the device and medical staff. Medical professionals input monitoring parameters and requirements via the control panel, and the display presents monitored physiological parameters and waveforms. The recording section archives these parameters. When monitored parameters exceed preset ranges, the audio-visual alarm alerts medical staff to perform timely inspections or interventions.
AHP-FTA-BN framework
Analytic hierarchy process
AHP is a structured decision-making method that decomposes complex problems into a hierarchical framework comprising objectives, criteria, and alternatives23. By performing pairwise comparisons at each level, AHP assigns relative weights to criteria and alternatives, ensuring consistency through eigenvector-based calculations. This approach is particularly effective in integrating expert judgments while minimizing subjectivity.
Fault tree analysis
FTA serves as a fundamental tool for assessing system reliability. It constructs a fault tree comprising events and logic gates, identifying the most critical system failure, referred to as the top event. This method traces back through events to uncover root causes, known as basic events34. Logic gates delineate the logical relationships between events, forming an inverted tree structure. Through quantitative calculations, analysts can determine the probability of occurrence for the top event. While the process of constructing a fault tree is straightforward, complex system architectures can result in intricate fault trees, complicating the calculations. Furthermore, FTA does not accommodate multi-state events.
Bayesian networks
BN offer a probabilistic graphical framework for modeling the relationships among random variables. Utilizing a directed acyclic graph, BN visually represent these relationships35. For example, a directed arc from X1 to X2 (X1 → X2) indicates a causal relationship, with X1 serving as the parent node and X2 as the child node. In this context, nodes represent variables, while directed edges illustrate dependencies, typically oriented from parent to child. Conditional probability tables articulate the logical interdependencies and facilitate the representation of multi-state events. BNs are adept at computing system reliability in a forward manner and assessing the influence of specific components in a backward direction. However, the construction of the network architecture and the process of data learning can often be complex.
Synergizing fault tree analysis and bayesian networks
FTA and BN each offer distinct advantages for reliability analysis. The integration of these methods can be especially advantageous for complex systems. Initially, a fault tree is constructed, which is subsequently translated into a BN for computational analysis. This integration circumvents the labor-intensive quantitative assessments typically associated with fault trees and streamlines the establishment of BN. Furthermore, BN is capable of accommodating various system states, and their bidirectional computation capabilities facilitate more comprehensive and precise reliability evaluations. Once the fault tree is developed, it can be transformed into a BN using specified mapping relationships, as illustrated in Table 1. In this transformation, events in the fault tree become nodes in the BN, with basic events represented as root nodes, intermediate events as intermediary nodes, and the top event as a leaf node. The logic gates are converted into conditional probability tables, while the occurrence probabilities of basic events in the FTA serve as the prior probabilities in the BN. Table 1 presents the mapping relationships between the fault tree and the BN.
fault identification and fault tree construction
Based on the structural principles of multi-parameter monitors, the top event (T) identified as “multi-parameter monitor not functioning properly” was determined through analysis of common failures. This analysis established eight common failure categories as secondary intermediate events (M1-M8). The failure causes are systematically analyzed layer by layer until all relevant basic events (BE1-BE32) are identified. Figure 2 illustrates the established fault tree, while Table 2 lists the corresponding fault codes and fault description.

FTA model for Monitor.
Estimation of BEs probabilities
Historical data is typically utilized to quantify the probabilities of BE failure36. However, the predominance of qualitative case analyses over systematic and quantitative research in previous studies has resulted in a deficiency of failure data. Consequently, this study employs the expert judgment method. To address potential subjective differences arising from the experts’ varying educational backgrounds, work experiences, and professional ranks, the AHP is implemented to better integrate these perspectives. Weights are assigned to the ten participating experts based on their educational background (1–5 points), work experience (1–5 points), and professional rank (1–5 points). The weight table for the experts is presented in Table 2.
Triangular fuzzy quantification of BEs
Recognizing that fuzzy set theory effectively deals with uncertain and ambiguous information24, this study applies it to the quantification of BEs. The quantification process for BE probabilities includes four steps.
Triangular fuzzy quantification of BEs
To streamline the modeling process, the study utilizes the common triangular membership function for natural language representation, enabling quantitative assessment. The linguistic variables used are Very Low (VL), Low (L), Medium (M), High (H), and Very High (VH), with values depicted in Fig. 3. The triangular fuzzy numbers (a1, a2, a3) and their corresponding membership function are shown in formula (1).

Corresponding numerical values for linguistic variables.
Normalization of expert opinions
Experts’ varied backgrounds in monitor management may result in differing event failure judgments. To reconcile these differences, linguistic assessments expressed as fuzzy numbers across different experts must be combined into one unified fuzzy number. Traditional methods like those by Zhu37 depend on intersections within fuzzy sets of expert opinions. To overcome these constraints, this study introduces a new method for consistency aggregation, described in the steps that follow.
-
(1)
Calculate the degree of recognition between any two experts \(\:{R}_{ij}\), which is computed using the formula below:
In this formula, \(\:{\theta\:}_{i}=\left({a}_{i1,}{a}_{i2,}{a}_{i3,}\right)\) and \(\:{\theta\:}_{j}=\left({a}_{j1,}{a}_{j2,}{a}_{j3,}\right)\) are the fuzzy numbers corresponding to experts \(\:{E}_{i}\) and \(\:{E}_{j}\), respectively. It is also easy to see that when \(\:i=j\), \(\:{R}_{ij}=1\).
-
(2)
Calculate the recognition matrix M for all experts and the average recognition degree \(\:A\left({E}_{i}\right)\) for each expert. The recognition matrix consists of elements \(\:{R}_{ij}=R\left({\theta\:}_{i},{\theta\:}_{j}\right)\). The matrix M is shown as follows:
The average recognition degree for each expert:
-
(3)
Calculate the Relative Agreement Degree (RAD) for each expert:
In the formula above, n represents the number of experts, which is 10 in this study.
-
(4)
Calculate the Importance Measure IM(Ei) for each expert:
In this formula, score(i) is the importance score of Ei, as referenced in Table 2.
-
(5)
Calculate the Weight Coefficient W (Ei) for each expert:
The weight coefficient of an expert is a combined representation of IM and RAD, expressed by the following formula:
In this formula, α (0 ≤ α ≤ 1) is a relaxation factor that indicates the relative importance of importance measure compared to relative agreement degree. Based on the actual needs of this study, α = 0.5.
-
(6)
Comprehensive result of expert judgments:
In this formula, Pj is the comprehensive fuzzy result for basic event j, Pij is the fuzzy number corresponding to expert Ei, and m is the number of basic events.
Defuzzify the fuzzy possibility of BEs
The purpose of defuzzification is to transform expert opinions into fuzzy numbers, facilitating an efficient approximation of real-world systems. This study introduces the Left-Right fuzzy ranking method38, which is a widely adopted defuzzification technique in fuzzy mathematics. This method converts triangular fuzzy numbers into precise numerical values by considering both the left and right spreads, which represent pessimistic and optimistic uncertainties, respectively. Through a weighted aggregation of these spreads alongside the most probable value of the fuzzy number, the method calculates a defuzzified score that balances conservative and optimistic perspectives. For triangular fuzzy numbers, the calculation process can also be derived based on both the numerical characteristics and graphical representation of the fuzzy set. This detailed explanation not only provides clarity on the theoretical foundation of the Left-Right fuzzy ranking method but also highlights its practical computational framework, ensuring a comprehensive understanding of its implementation.
Convert fuzzy numbers into fuzzy possibility scores (FPS), expressed as follows:
FPS is derived from FPSL and FPSR:
Convert FPS into fuzzy probability value of each BEs
The approximated efficiency score obtained after defuzzification can be converted to an approximate probability of failure using the following empirical formula:
In this formula, P(BEi) represents the approximate failure probability of BE i.
Conversion of fault tree to bayesian network model
A BN is an effective graphical model for representing and reasoning about uncertainties. By transforming a fault tree into a BN, we can efficiently calculate and analyze fault probabilities. In this transformation, each basic event in the fault tree corresponds to a node in the BN, as does the top event. Directed edges are established in the BN according to the logical gate relationships from the fault tree. When an AND gate connects multiple basic events to an intermediate or top event, directed edges for that event node in the BN will stem from all involved basic event nodes. For an OR gate, the directed edges will emanate from each basic event node linked to the OR gate. Conditional probability distributions for the BNs are then specified. Basic event nodes rely on prior probabilities for their distributions, while intermediate and top event nodes are calculated based on the fault tree’s logical gate relationships and basic event probabilities.
In this section, we provide a detailed explanation of the methodology for calculating the posterior probabilities of each BE given the failure of the monitor (P(T) = 1). This process involves two stages: (1) forward propagation to compute the prior probabilities of intermediate events (M) and the top event (T) and (2) backward propagation to determine the posterior probabilities of basic (BE) and intermediate (M) events conditioned on P(T = 1).
Forward propagation: prior probability calculation
(1) Basic Events (BEi):
The prior probabilities of the basic events (BEi) are determined based on observational data or expert knowledge. These probabilities serve as the input to the Bayesian network and are assumed to be independent, i.e.:
(2)Intermediate Events(Mj):
Each intermediate event (Mj) depends probabilistically on a subset of basic events (BEi). The prior probability of Mj is computed using the conditional probability table (CPT) for Mj and the joint probabilities of its related basic events. Through logical relationships such as OR gates, the conditional probability table of node M8 is established in Table 4, where P(M8=1) and P(M8=0) represent the occurrence and non-occurrence probabilities, respectively. Given the substantial number of intermediate nodes, the probability tables for other nodes are omitted.
Where:
\(\:P\left({M}_{j}=1|BE=b\right)\) is given in the CPT for \(\:{M}_{j}\); b = [b1, b2,\(\:\:\cdots\:\), br] is the binary state vector of the r basic events affecting \(\:{M}_{j}\); P(BEk = bk) is know prior probability of BEk. This calculations performed for each intermediate event(M1, M2, \(\:\cdots\:\), Mq) in the network.
(3)Top Event(T):
The top event (T) represents the monitor failure and is probabilistically influence by all intermediate events (Mj) in the network. The prior probability of T is computed marginalizing over all possible states of the intermediate events:
Where: \(\:P\left(T=1|M=m\right)\)is the condition probability that T = 1 given a special configuration of the intermediate events m=[m1, m2, \(\:\cdots\:\), mq]. P(Mj = mj) is the prior probalility of Mj that was computed in formula (14).
Through this process, the probabilities of all nodes are propagated forward, allowing for the prior probabilities of intermediate and top events to be determined.
Backward propagation: posterior probability calculation
When the top event,T,is observed as T = 1 (indicating monitor failure), Bayes’ theorem is applied to compute the posterior probabilities of the intermediate events(Mj) and basic events(BEi). This represents backward inference within the Bayesian network.
-
(1)
Posterior probabilities of intermediate events (Mj).
The posterior probability of each intermediate event (Mj)is calculate as:
Where:
\(\:P\left(T=1|{M}_{j}=1\right)\) is obtained from the conditional probality table of T. \(\:P\left({M}_{j}=1\right)\) is the prior probability of Mj derived from formula (14). P(T = 1) is the prior probability of T derived from formula (15).
The posterior probability \(\:P\left({M}_{j}=0|T=1\right)\) is calculated as :
-
(2)
Posterior probabilities of Basic Events (BEi).
The posterior probability of each basic events (BEi) is computed based on its relationship with the intermediate events. Using the law of total probability, the posterior probability is given by:
Where:
\(\:P\left({BE}_{i}=1|{M}_{j}=1\right)\) and \(\:P\left({BE}_{i}=1|{M}_{j}=0\right)\) are know from CPT of\(\:{\:M}_{j}\). \(\:P\left({M}_{j}=1|T=1\right)\) is the posterior probability of \(\:{\:M}_{j}\) calculated in formula (16). This calculation accounts for all intermediate events(\(\:{\:M}_{j}\)) that influence a given basic events (\(\:{BE}_{i}\)).
Application of posterior probabilities
After calculating the posterior probabilities of basic events (\(\:P\left({BE}_{i}=1|T=1\right)\)), these probabilities are employed to identify and rank the failure-inducing factors across different lifecycle stages of the monitor. This ranking enables a systematic, dynamic determination of the dominant causes of failures at each stage, without relying on fixed thresholds to classify events as “high” or “low” impact. By focusing on the highest-ranked basic events within each stage, key failure mechanisms can be identified, guiding targeted interventions such as preventative maintenance, operational adjustments, or design optimizations tailored to specific lifecycle phases.
Implementation
Calculate the prior probabilities of BEs
As detailed in Sect. 2.3, information regarding monitor failures was obtained through consultations with 10 experts. These experts included engineers from the hospital’s medical equipment management department and product after-sales service teams. Their assessments varied due to differences in education, experience, and professional rank. To address these subjective variations, a weighting scheme, as presented in Table 2, was employed to better integrate the expert judgments. The experts evaluated monitors based on their years of use, categorized as follows: group A (1–5 years), group B (6–10 years), and group C (11–15 years). This method ensures a comprehensive assessment covering all hospital monitors. Table 5 details the expert profiles along with their respective weighting scores.
This study uses group B’s BE1 to illustrate the expert opinion normalization process in detail. Drawing from expert evaluations of BE1 failure alongside linguistic variable quantification, the insights from 10 experts are translated into the following fuzzy numbers: (0, 0.1, 0.3), (0.3, 0.5, 0.7), (0, 0.1, 0.3), (0.1, 0.3, 0.5), (0.7, 0.9, 1.0), (0, 0.1, 0.3), (0, 0.1, 0.3), (0, 0.1, 0.3), (0.3, 0.5, 0.7), and (0, 0.1, 0.3).
The relaxation factor, which balances the importance of experts against the relative agreement degree, is obtained from formulas (4) to (7). This facilitates the computation of each expert’s average recognition degree, relative agreement degree, importance, and weight coefficient, as outlined in Table 5.
Using formula (8), the normalized expert judgment results for all component failures are illustrated in Table 6. The Left-Right fuzzy ranking method is employed for defuzzification, enabling the calculation of defuzzification scores and failure rates for each component in group B, based on formulas (11) and (12). These failure rates are used as prior probabilities in subsequent research, as listed in Table 7.
Construction of the bayesian network for the multi-parameter monitor
The fault tree of the multi-parameter monitor was converted into a BN, as shown in Fig. 4. Using the previously derived prior probabilities from the research data, failure probabilities for the monitor were calculated and visualized with Netica (Version 7.01, Norsys Software Corp.), as illustrated in Fig. 5. The failure probability for monitors used 1–5 years is 3.18%, for those used 6–10 years it is 13.2%, and for those used 11–15 years it rises to 64.5%. These results align logically with expectations, as failure rates increase over time. Particularly, once monitors surpass the manufacturer-recommended lifespan (e.g., beyond 10 years), the probability of failure escalates significantly.
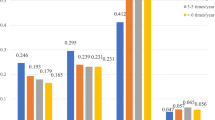
Figure 5; Table 8 illustrate the tendencies of failure probabilities for different monitor components over various usage periods. In group A (1–5 years), components M1 and M2 are noteworthy; in group B (6–10 years), M5 and M6 stand out; and in group C (11–15 years), M2, M4, and M5 are prominent. By analyzing the failure rate trends across three operational periods, M3 (0.29%, 0.7%, 4.47%) and M7 (0.53%, 0.58%, 2.65%) demonstrate consistently low failure rates and minimal variability. This significant performance advantage compared to other components strongly validates their exceptional stability and reliability throughout the product lifecycle.

Bayesian network of the multi-parameter monitor.
To examine the main causes of monitor failures at each stage, the model assumes a 100% monitor failure rate, as shown in Fig. 6. Bayesian networks calculate the posterior probabilities of each basic event occurring when the top event happens. Figure 7 displays the basic event distributions causing monitor failures for groups A (1–5 years), B (6–10 years), and C (11–15 years).

Calculation results of leaf node occurrence probabilities for multi-parameter monitors at different usage stages. This figure shows the prior probabilities of basic events (BE), intermediate events (M), and the top event (T) for multi-parameter monitors at three usage stages, calculated using the method in Sect. 2.4.1 (Forward Propagation: Prior Probability Calculation). Probabilities were derived from expert judgments based on original data collected in this study, calculated and visualized using the FAHP-FTA-BN framework and Netica (Version 7.01, Norsys Software Corp.). No external data or database was used. Panel A: Monitors (1–5 years). Panel B: Monitors (6–10 years). Panel C: Monitors (11–15 years). “Fault” indicates failure probability, and “Work” indicates normal operation probability. These results highlight failure trends across life-cycle stages, supporting targeted maintenance planning.

Posterior probabilities of events for the root node of multi-parameter monitors at different usage stages. This figure illustrates the posterior probabilities of basic events (BE), intermediate events (M), and the top event (T) for multi-parameter monitors under the failure condition (P(T = 1)) across three usage stages, calculated using the method in Sect. 2.4.2 (Backward Propagation: Posterior Probability Calculation). Probabilities were derived from expert judgments based on original data collected in this study, calculated and visualized using the FAHP-FTA-BN framework and Netica (Version 7.01, Norsys Software Corp.). No external data or database was used. Panel A: Monitors (1–5 years).Panel B: Monitors (6–10 years).Panel C: Monitors (11–15 years).“Fault” indicates failure probability, and “Work” indicates normal operation probability. These results reveal how failure conditions propagate through the system at different life-cycle stages, providing insights for system reliability assessment.

Posterior probability distribution comparison chart of basic events in failure of three groups of monitors.
Group A (1–5 years) exhibits an average failure rate of 3.22%, with a median of 2.83%. Group B (6–10 years) has an average failure rate of 3.29%, with a median of 1.77%. Group C (11–15 years) presents an average failure rate of 4.79%, with a median of 2.53%. The average failure rate generally rises with usage, though the median doesn’t entirely reflect this increase. There’s a slight average failure rate rise from 1 to 5 to 6–10 years (3.22–3.29%) and a notable increase from 6 to 10 to 11–15 years (3.29–4.79%).
Analysis of high-risk components indicates:
-
(1)
Group A (1–5 years): Highest failure rates in BE3, BE4, BE6, BE7, and BE18.
-
(2)
Group B (6–10 years): Highest failure rates in BE22, BE23, BE24, BE29, and BE30.
-
(3)
Group C (11–15 years): Highest failure rates in BE20, BE22, BE23, BE24, and BE27.
These high-risk components should receive more frequent inspections and maintenance. The correlation between groups A and B is low (0.11), suggesting different early-to-mid stage failure patterns. There’s a higher correlation between groups B and C (0.68), indicating some similarity in mid-to-late stage failure patterns, while the correlation between groups A and C is very low (−0.07), highlighting significant early-to-late stage differences. Analyzing failure rate changes shows that 17 components increased failure rates over time, and 15 decreased, with no components maintaining completely stable failure rates, indicating that most components’ failure rates change with usage, though the direction varies.
Practice and application
After the theoretical research, a one-year practical study was conducted in 3201 hospital to verify its feasibility concerning maintenance costs. When a monitor malfunctions, the probabilities of different basic events guide the advance preparation of spare components, allowing for immediate maintenance and replacement. Maintenance costs encompass: (1) part procurement costs; (2) downtime loss costs; (3) expedited procurement costs; (4) inventory management costs. The average cost for parts is 200 RMB, with downtime costing 10 RMB per hour; repairs take approximately one hour per component. Temporary parts take about three days to arrive, with expedited procurement incurring costs about 20% higher than normal. The hospital operates around 457 monitors, with 179 in the 1–5 year stage, 190 in the 6–10 year stage, and 88 in the 11–15 year stage. Based on the posterior probability analysis, spare parts were organized, as shown in the accompanying Table 9.
The specific calculation steps are as follows:
Step 1: Calculate the stock of spare parts (SSP) based on the quantity of monitors in each group and the posterior probability (PP).
For example:
Then, the number of spare parts prepared in accordance with BE1 is 14. The number of spare parts corresponding to other events can all be obtained by this calculation.
Step 2: Calculate the cost.
(1)With FAHP -FTA-BN:
In this equation, 536 represents the quantity of spare parts prepared, and 64 stands for the number of spare parts procured through expedited procurement.
In this equation, 577 is the number of spare parts actually used, and 64 is the number of spare parts procured through expedited procurement.
(2)Without FAHP -FTA-BN (No Spares):
It can be known from calculations that after employing the FAHP -FTA-BN method and preparing spare parts in advance, the total cost will be significantly reduced by 66%. While downtime losses are challenging to quantify precisely, the estimated hourly loss, derived from clinical practice, serves as a reference point. Prompt repairs are crucial, as delays following a monitor failure can disrupt clinical operations, contributing to increased downtime costs. In the scenario where spare parts are available, the loss cost caused by downtime constitutes 27.2% of the total cost. Conversely, when there are no spare parts, it accounts for 75.5% of the total cost. Moreover, with adequate preparation, the unnecessary expenses associated with expedited procurement can be minimized, further optimizing maintenance budgets. After practical application, using FAHP -FTA-BN to determine the failure rates of various monitor components and preparing spare parts in advance can significantly reduce maintenance costs.
Discussion
In this study, the multi-parameter monitor was selected as the research object, and its entire life cycle was divided into three stages. In the absence of historical maintenance data, the FAHP -FTA-BN method was utilized to explore the failure probabilities of the monitor at different usage stages, clarify the differences in failures at each stage, and analyze the key failure causes that should be prioritized in each stage. Subsequently, the analysis results were applied to practical maintenance work. A comparison of maintenance costs revealed that the method proposed in this study effectively reduces maintenance costs, thereby demonstrating its practical applicability. The obtained results provide valuable insights and have been further confirmed through empirical verification. The details are as follows:
(1) Precise Quantification of Failure Probabilities. The application of the FAHP -FTA-BN method enables precise quantification of failure probabilities, providing crucial data for formulating maintenance plans tailored to the different usage stages of the monitor. Such detailed data is vital for developing targeted maintenance strategies.
(2) Accurate Identification of High-Risk Components. Through in-depth analysis, distinct high-risk components have been accurately identified within each usage age group. This finding underscores the necessity of formulating customized maintenance plans for these high-risk components, which may involve more frequent inspections and preventive replacements to mitigate the risk of potential failures.
(3) Dynamic Changes in Failure Modes. This study reveals significant differences in failure modes during the early, mid, and late stages of the monitor’s life cycle. These findings clearly indicate the need to develop adaptive maintenance strategies that can flexibly respond to such changes, thereby enhancing the effectiveness of maintenance efforts.
(4) In-depth Analysis of Component Aging Characteristics. Over time different components exhibit varying failure rates. Special attention should be directed towards those components that demonstrate gradually increasing failure rates. It may be necessary to modify their designs or utilize high-performance materials to ensure the reliability of both the components and the overall device.
(5) Detailed Consideration of Cost-Benefit Analysis. This study conducted a comprehensive cost-benefit analysis by considering the replacement costs of components alongside their impact on the overall performance of the device. The results indicate that an optimal replacement strategy can be developed to achieve a delicate balance between maintenance expenditures and equipment reliability.
The scheme proposed in this study demonstrates its superiority over existing maintenance practices in several respects. In the absence of historical data, the method effectively leverages expert experience. Unlike previous studies that primarily employed qualitative or quantitative analyses in isolation39,40, this approach integrates both aspects, thereby providing a more holistic understanding of the failure mechanism. This integration is particularly evident in the more accurate identification of high-risk components and the formulation of targeted maintenance strategies. Additionally, in contrast to studies that did not adequately consider the changes occurring at different stages of the equipment life cycle41, this research underscores the importance of developing adaptive maintenance strategies informed by the observed variations in failure modes throughout the life cycle. This enables a more effective response to the unique challenges presented at each stage, thereby optimizing the maintenance process.
In contrast to some existing studies that may have overlooked the cost-benefit analysis aspect42, this study conducts a comprehensive analysis of the replacement costs of components and their impact on device performance. This approach facilitates the design of an optimal replacement strategy that achieves an ideal balance between maintenance expenditures and equipment reliability, which is a crucial factor in ensuring the long-term viability of medical equipment maintenance.
The empirical results of this study, particularly the high degree of alignment between projected and actual spare parts requirements, further validate the effectiveness of the FAHP -FTA-BN method. Consistent with findings reported in related studies8,43, this research confirms the feasibility of utilizing this method to reduce maintenance costs through optimized inventory and procurement processes. However, it is important to note that the method employed in this study may introduce a degree of subjectivity, potentially affecting the accuracy of the results. For instance, when identifying high-risk components based on expert opinions, variability in outcomes may arise due to differences in the professional knowledge and practical experience of the participating experts. Therefore, careful consideration of this subjectivity is essential when interpreting the results of this study.
In the field of medical equipment maintenance, particularly concerning predictive maintenance, future research holds significant potential for further advancements. Building on the findings and limitations of this study, it is noteworthy that numerous researchers have proposed the concept of predictive maintenance5,44, which aims to forecast the future condition of medical equipment using data-driven methods to facilitate planned and targeted maintenance. By leveraging fault trees in conjunction with historical maintenance data, it is possible to expand the fault knowledge base and develop an expert system that integrates data-driven insights with experiential knowledge. This system seeks to enhance the accuracy and reliability of diagnostics through the optimal fusion of historical data and expert input. For instance, by combining machine learning algorithms with expert rules, the expert system may more accurately identify complex fault patterns and provide tailored maintenance recommendations. Furthermore, continuous improvement of the cost-benefit analysis in medical equipment maintenance is essential. Future research could focus on developing more sophisticated models that consider additional factors, such as the impact of equipment downtime on patient care, the costs associated with lost productivity due to equipment failures, and the long-term financial implications of various maintenance strategies. Incorporating these factors into the cost-benefit analysis will enable the design of more comprehensive and accurate maintenance strategies, ensuring the economic feasibility and effectiveness of medical equipment maintenance.
Conclusion
Using the multi-parameter monitor as a case study, this research analyzed the fault conditions of the monitor across various trial stages by FAHP -FTA-BN, despite the absence of maintenance historical data. The following conclusions were drawn:
-
(1)
This method has been demonstrated to be both practical and feasible. It is particularly beneficial for medical institutions in developing countries and many small medical facilities, as it effectively manages the maintenance costs of medical equipment within the constraints of limited resources.
-
(2)
This approach has facilitated both qualitative and quantitative analyses of medical equipment faults. It has accurately assessed fault probabilities at different usage stages, identified high-risk components, tracked changes in fault modes, understood the aging characteristics of components, formulated preventive maintenance strategies, and conducted cost-benefit analyses. Collectively, these elements provide essential technical support for maintenance modes and plans, thereby enhancing maintenance efficiency.
-
(3)
Through a combination of practical experience and theoretical research, ensuring the availability of necessary spare parts in advance can significantly lower maintenance costs, thereby supporting the high-quality development of hospitals.
This study also opens new avenues for research into the maintenance of medical equipment in future medical institutions, including intelligent fault diagnosis, enhancement of the hybrid model, and improvement of cost-benefit analysis. These initiatives aim to further increase the effectiveness and economic viability of medical equipment maintenance, building on the foundation established by this study.
Data availability
The data presented in this study are available on request from the corresponding author. The data are not publicly available due to privacy and ethical.
References
de Araujo, M. S., da Silva, L. D., Sobrinho, Á., Cunha, P. & Montecchi, L. Reliability analysis of multi-parameter monitoring systems for intensive care units. Reliab. Eng. Syst. Saf. 226 https://doi.org/10.1016/j.ress.2022.108638 (2022).
Ma, G., Zhang, J., Liu, J., Wang, L. & Yu, Y. A. Multi-Parameter fusion method for cuffless continuous blood pressure Estimation based on electrocardiogram and photoplethysmogram. Micromachines 14 https://doi.org/10.3390/mi14040804 (2023).
Alhussaini, K. et al. Evaluation of medical equipment maintenance and skilled manpower requirement among private dental centres in Riyadh, Saudi Arabia: A pilot study. Technol. Health Care. 32, 2409–2419. https://doi.org/10.3233/thc-231177 (2024).
Aunión-Villa, J. & Gómez-Chaparro, M. García Sanz-Calcedo, J. Assessment of the maintenance costs of electro-medical equipment in Spanish hospitals. Expert Rev. Med. Dev. 17, 855–865. https://doi.org/10.1080/17434440.2020.1796635 (2020).
Rahman, N. H. A. et al. Medical device failure predictions through AI-Driven analysis of multimodal maintenance records. IEEE Access. 11, 93160–93179. https://doi.org/10.1109/access.2023.3309671 (2023).
Miguel Cruz, A., Maria, R. & Rincon, A. Medical device maintenance outsourcing: have operation management research and management theories forgotten the medical engineering community? A mapping review. Eur. J. Oper. Res. 221, 186–197. https://doi.org/10.1016/j.ejor.2012.02.043 (2012).
Webber, C. M. et al. Developing strategies for sustainable medical equipment maintenance in Under-Resourced settings. Annals Global Health. 86 https://doi.org/10.5334/aogh.2584 (2020).
Hillebrecht, M. et al. Maintenance versus replacement of medical equipment: a cost-minimization analysis among district hospitals in Nepal. BMC Health Serv. Res. 22 https://doi.org/10.1186/s12913-022-08392-6 (2022).
Zhou, S. Inventory control and durability analysis of medical equipment maintenance accessories. Biomedical Eng. Clin. Med. 27, 517–522. https://doi.org/10.13339/j.cnki.sglc.20230626.004 (2023).
Pinho, M., Costa, A. S., Meneses, M. & Manso, J. A multiple criteria sorting method for supporting the maintenance management of medical ventilators: the case of hospital Da Luz Lisboa. Socio-Economic Plann. Sci. 86 https://doi.org/10.1016/j.seps.2022.101458 (2023).
Li, J., Mao, Y., Zhang, J. & Ye, J. Maintenance and quality control of medical equipment based on information fusion technology. Comput. Intell. Neurosci. 2022, 1–11. https://doi.org/10.1155/2022/9333328 (2022).
Mellado-Silva, R., Cubillos, C., Cabrera-Paniagua, D. & Urra, E. Flow-Shop Scheduling Problem Applied to the Planning of Repair and Maintenance of Electromedical Equipment in the Hospital Industry. Processes 10 (2022). https://doi.org/10.3390/pr10122679
Hunte, J. L., Neil, M. & Fenton, N. E. A hybrid bayesian network for medical device risk assessment and management. Reliab. Eng. Syst. Saf. 241 https://doi.org/10.1016/j.ress.2023.109630 (2024).
Lu, Q. P. et al. Continuous quality improvement project to reduce the downtime of medical linear accelerators: A case study at Zhejiang Cancer hospital. Heliyon 10 https://doi.org/10.1016/j.heliyon.2024.e30668 (2024).
Verma, A. et al. Failure rate prediction of equipment: can Weibull distribution be applied to automated hematology analyzers? Clin. Chem. Lab. Med. (CCLM). 56, 2067–2071. https://doi.org/10.1515/cclm-2018-0569 (2018).
Rosen, M. A. et al. Failure mode and effects analysis applied to the maintenance and repair of anesthetic equipment in an austere medical environment. Int. J. Qual. Health Care. 26, 404–410. https://doi.org/10.1093/intqhc/mzu053 (2014).
Ayres-de‐Campos, D., Stones, W. & Theron, G. Affordable and low‐maintenance obstetric devices. Int. J. Gynecol. Obstet. 146, 25–28. https://doi.org/10.1002/ijgo.12838 (2019).
Taghipour, S., Banjevic, D. & Jardine, A. K. Reliability analysis of maintenance data for complex medical devices. Qual. Reliab. Eng. Int. 27, 71–84. https://doi.org/10.1002/qre.1084 (2011).
Miguel Cruz, A. & Guarín, M. R. Determinants in the number of staff in hospitals’ maintenance departments: a multivariate regression analysis approach. J. Med. Eng. Technol. 41, 151–164. https://doi.org/10.1080/03091902.2016.1243168 (2016).
Amran, M. E. et al. Critical assessment of medical devices on reliability, replacement prioritization and maintenance strategy criterion: case study of Malaysian hospitals. Qual. Reliab. Eng. Int. 40, 970–1001. https://doi.org/10.1002/qre.3447 (2023).
Gao, Q. & Ge, Y. Maintenance interval decision models for a system with failure interaction. J. Manuf. Syst. 36, 109–114. https://doi.org/10.1016/j.jmsy.2015.04.012 (2015).
Clermont, P. & Kamsu-Foguem, B. Experience feedback in product lifecycle management. Comput. Ind. 95, 1–14. https://doi.org/10.1016/j.compind.2017.11.002 (2018).
Lee, M. Strategies for promoting the medical device industry in Korea: an analytical hierarchy process analysis. Int. J. Environ. Res. Public Health. 15 https://doi.org/10.3390/ijerph15122659 (2018).
Wang, Q. et al. A reliability analysis method for fuzzy multi-state system with common cause failure based on improved the weakest T-norm. J. Franklin Inst. 361 https://doi.org/10.1016/j.jfranklin.2024.106940 (2024).
Qin, G. et al. Failure probability Estimation of natural gas pipelines due to hydrogen embrittlement using an improved fuzzy fault tree approach. J. Clean. Prod. 448 https://doi.org/10.1016/j.jclepro.2024.141601 (2024).
Roozbahani, A. & Ghanian, T. Risk assessment of inter-basin water transfer plans through integration of fault tree analysis and bayesian network modelling approaches. J. Environ. Manage. 356 https://doi.org/10.1016/j.jenvman.2024.120703 (2024).
He, L. et al. A Case Study of Accident Analysis and Prevention for Coal Mining Transportation System Based on FTA-BN-PHA in the Context of Smart Mining Process. Mathematics 12 (2024). https://doi.org/10.3390/math12071109
Ragan, J., Riviere, B., Hadaegh, F. Y. & Chung, S. J. Online tree-based planning for active spacecraft fault Estimation and collision avoidance. Sci. Rob. 9 https://doi.org/10.1126/scirobotics.adn4722 (2024).
Kwag, S., Choi, E., Hahm, D., Kim, M. & Eem, S. Computationally efficient Complete-Sampling-based fault tree analyses for seismic probabilistic safety assessment of nuclear facilities. Expert Syst. Appl. 260 https://doi.org/10.1016/j.eswa.2024.125341 (2025).
Senol, Y. E. Assessment of human factor contribution to risk analysis of chemical cargo shortage incidents by using intuitionistic fuzzy integrated fault tree analysis. Ocean Eng. 301 https://doi.org/10.1016/j.oceaneng.2024.117559 (2024).
Meng, H. et al. Risk analysis of lithium-ion battery accidents based on physics-informed data-driven bayesian networks. Reliab. Eng. Syst. Saf. 251 https://doi.org/10.1016/j.ress.2024.110294 (2024).
Feng, Y. et al. A bayesian network for simultaneous keyframe and landmark detection in ultrasonic cine. Med. Image. Anal. 97 https://doi.org/10.1016/j.media.2024.103228 (2024).
Syed, F. A., Fang, K. T., Kiani, A. K., Shoaib, M. & Raja, M. A. Z. Design of Neuro-Stochastic bayesian networks for nonlinear chaotic differential systems in financial mathematics. Comput. Econ. https://doi.org/10.1007/s10614-024-10587-4 (2024).
Liu, Z. et al. Risk assessment and alleviation of regional integrated energy system considering cross-system failures. Appl. Energy. 350 https://doi.org/10.1016/j.apenergy.2023.121714 (2023).
Zhou, K., Xing, W., Wang, J., Li, H. & Yang, Z. A data-driven risk model for maritime casualty analysis: A global perspective. Reliab. Eng. Syst. Saf. 244 https://doi.org/10.1016/j.ress.2023.109925 (2024).
Khan, F., Yarveisy, R. & Abbassi, R. Risk-based pipeline integrity management: A road map for the resilient pipelines. J. Pipeline Sci. Eng. 1, 74–87. https://doi.org/10.1016/j.jpse.2021.02.001 (2021).
Zhu, B. & Xu, Z. Consistency measures for hesitant fuzzy linguistic preference relations. IEEE Trans. Fuzzy Syst. 22, 35–45. https://doi.org/10.1109/tfuzz.2013.2245136 (2014).
Yu, V. F., Chi, H. T. X., Dat, L. Q. & Phuc, P. N. K. Shen, C.-w. Ranking generalized fuzzy numbers in fuzzy decision making based on the left and right transfer coefficients and areas. Appl. Math. Model. 37, 8106–8117. https://doi.org/10.1016/j.apm.2013.03.022 (2013).
Crapanzano, F., Luschi, A., Satta, F., Sani, L. & Iadanza, E. Evidence based management of medical devices: A follow-up experiment. Biomed. Signal Process. Control. 99 https://doi.org/10.1016/j.bspc.2024.106867 (2025).
Liao, H., Cade, W. & Behdad, S. Markov chain optimization of repair and replacement decisions of medical equipment. Resour. Conserv. Recycl. 171 https://doi.org/10.1016/j.resconrec.2021.105609 (2021).
Iadanza, E., Gonnelli, V., Satta, F. & Gherardelli, M. Evidence-based medical equipment management: a convenient implementation. Med. Biol. Eng. Comput. 57, 2215–2230. https://doi.org/10.1007/s11517-019-02021-x (2019).
Li, J., Zhang, Y., Gu, W., Wang, T. & Zhou, Y. Diagnosis, management, and prevention of malfunctions in anesthesia machines. Technol. Health Care. 31, 2235–2242. https://doi.org/10.3233/thc-230191 (2023).
Khalaf, A., Djouani, K., Hamam, Y. & Alayli, Y. Maintenance strategies and Failure-Cost model for medical equipment. Qual. Reliab. Eng. Int. 31, 935–947. https://doi.org/10.1002/qre.1650 (2014).
Qiu, H., Wang, J., Wang, D. & Yin, Y. Service-oriented multi-skilled technician routing and scheduling problem for medical equipment maintenance with sudden breakdown. Adv. Eng. Inform. 57 https://doi.org/10.1016/j.aei.2023.102090 (2023).
Acknowledgements
We sincerely thank the experts who contributed their valuable insights to our study. Their input was vital in shaping our research. We also express our gratitude to Genertec Medical Scientific Research Fund (grant number: TYYLKYJJ-2022-013) for their financial support, which made this study possible.
Funding
This research was funded by Genertec Medical Scientific Research Fund, grant number TYYLKYJJ-2022-013 and “The APC was funded by Genertec Medical Scientific Research Fund (grant number: TYYLKYJJ-2022-013)”.
Author information
Authors and Affiliations
Contributions
For research articles with several authors, a short paragraph specifying their individual contributions must be provided. The following statements should be used “Conceptualization, K.L. and X.M.; methodology, K.L.; software, K.L.; validation, Y.S., L.S. and X.M.; investigation, K.L.; resources, X.M.; data curation, L.S.; writing—original draft preparation, K.L.; writing—review and editing, K.L.; visualization, J.C.; project administration, X.M.; funding acquisition, K.L.. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, K., Su, L., Cheng, J. et al. Improving maintenance efficiency and controlling costs in healthcare institutions through advanced analytical method. Sci Rep 15, 18377 (2025). https://doi.org/10.1038/s41598-025-02176-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-02176-8
