
Abstract
A brain tumor is regarded as one of the deadliest types of cancer due to its intricate nature.This is why it is important that patients get the best possible diagnosis and treatment options. With the help of machine vision, neurologists can now perform a more accurate and faster diagnosis. There are currently no suitable methods that can be used to perform brain segmentation using image processing recently neural network model is used that it can perform better than other methods. Unfortunately, due to the complexity of the model, performing accurate brain segmentation in real images is not feasible. The main objective is to develop a novel method that can be used to analyze brain tumors using a component analysis. The proposed model consists of a deep neural network and an image processing framework. It is divided into various phases, such as the mapping stage, the data augmentation stage, and the tumor discovery stage. The data augmentation stage involves training a CNN to identify the regions of the image that are overlapping with the tumor space marker. The DCNN’s predicted performance is compared with the test result. The third stage is focused on training a deep neural system and a SVM. This model was able to achieve a 99% accuracy rate and a sensitivity of 0.973%. It is primarily utilized for identifying brain tumors.
Similar content being viewed by others
Introduction
Brain tumors are regarded as major health threats, and they can result in significant and life-threatening outcomes if left untreated. In order to improve the prognosis of patients with brain tumors, it is important that they are detected early1. The various types of brain tumors can make diagnosis challenging. This highlights the need for accurate classification to guarantee the best possible outcome. A brain tumor can be categorized into two types: benign and malignant2.
Magnetic resonance imaging is a type of imaging that uses the combination of electrical and sound waves to visualize the brain. It is useful in diagnosing various brain tumors. Unlike other imaging techniques, which use radiation, MRI does not use radiation. Its accuracy and reliability are very important factors that make it an ideal tool for medical imaging. The size and shape of the tumor can prevent an individual from identifying it3. With the help of MRI, doctors can visualize the various parts of the brain using four slices. These images allow them to identify the tumor. In addition to the size and shape of the tumor, the images also reveal the other details about the brain’s tissues4.
A segmentation technique is utilized in the analysis of medical images to separate the parts that need to be viewed properly5. It involves identifying the characteristics and features of the tumor that are most likely to affect the treatment of the patient.
-
1.
The intensity distribution around the tumour is not uniform.
-
2.
A great deal of ambient noise;
-
3.
A complex shape;
-
4.
Fuzzy boundaries; and
-
5.
A lack of contrast between adjacent brain tissues
Due to the complexity of the MR images, it is very time consuming and challenging for experts to analyze and visualize them6. With the help of automatic segmentation techniques, it can be done in less time and improve the accuracy of the diagnosis7. The biggest challenge that the experts face when it comes to analyzing and visualizing the data collected by Magnetic Resonance Imaging is the complexity of the images8. One of the most common factors that affects the classification process is the number of planes used. This means that the images must be pre-processed before they are loaded into the neural network9. Through the use of deep learning methods, such as CNN, you can perform pre-processing and feature engineering tasks without additional time10.
The goal of this study is to analyze the performance of a small architecture when compared to a complex one when it comes to classifying three tumor types using a CNN database. We also wanted to demonstrate that using a simpler network can reduce the training and implementation time needed for the system. Due to the limited number of resources available, it is typically difficult to use a CNN system in clinical settings. This paper presents a new architecture that can be used to classify three different brain tumor types. It can be used in mobile platforms and in everyday clinical diagnostics.
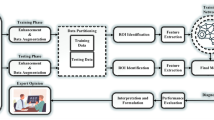
This paper aims to create a framework that will allow physicians to perform an independent assessment of brain images in order to detect tumors. It uses a combination of methods to improve its accuracy and performance. The system is made more accurate and performs better with the help of data augmentation and training procedures. Deep learning frameworks are very useful for improving the performance of systems. The paper combines the techniques used in deep learning and image processing to reduce the complexity of the collected texture features. After training and testing the system, it is equipped with CNN-SVM, which is a robust and accurate classification tool.
Literature review
Sajid et al.11—This author presented a hybrid model that takes advantage of the deep neural networks’ capabilities to perform segmentation. The proposed model was able to perform better than the existing techniques in several performance parameters. It utilizes a patch-based method to classify individual patches. It then trains on the output classes according to the distribution of labels. The paper also presented a two-phase training procedure that ensures that the learning is based on accurate representations of labels. The proposed model was also equipped with various data processing techniques, such as the N4ITK field correction. It can perform segmentation tasks such as identifying the various patches. Its performance can be improved by implementing training examples.
Almadhoun et al.12—developed a deep learning model that detected brain tumors used standard scans. The goal was to improve the accuracy of these scans by develped a method to perform quick and accurate decisions. In 2018, the World Health Organization reported that the death rate for brain cancer in Asia was higher than in other regions. The researchers have used a dataset of 10,000 images to develop the model, which was implemented using deep learning techniques. To test the model, they have used various models such as ResNet, Inception, and VGG16. Through the study, the researchers were able to demonstrate that the model was able to achieve an accuracy of 98.28 percent when compared to the previous model. They also noted that the training model’s accuracy was increasing, which means that it could be used to identify brain tumor.
Methil et al.13—The goal of this paper was to developed a method that can improved the performance of CNN’s image processing techniques when it comes to identified non-cancer and tumor images. Through various tasks, such as data augmentation and illumination, the paper was able to bring the tumor into focus. In order to improve the system’s performance, a transfer learning procedure was performed. The project started with the ResNet101v2 image processing model. Through further training, the system was able to achieve a 99.74% accuracy and a training recall of almost 99 percent. However, this method can potentially lead to errors since it relies on certain information about the tumor image. When creating an image, the size of the input should be set correctly so that it fits into the CNN model. If the input is not set correctly, it will not be able to fit into the image. In the future, the paper will perform various techniques to improve the system’s capabilities.
Alqazzaz et al.14—The paper presents a method that combines the use of brain tumor segmentation and MR images. This method improves the accuracy of the segmentation and the computational cost. This method mainly generated ROI images that only contain tumor tissues. Due to the limited capabilities of machine-learning models, we decided to use the features from the SegNet framework and the GLCM framework to create a unique feature set. The classification of the images used the combined features was performed by taking into account the sub-regions of the images. The results of the experiments revealed that the FLAIR method was more accurate than the SOTA methods when it comes to generating ROI images. The proposed SegNet-GLM_DT method outperforms the FLAIR and SOTA methods when it comes to performing whole tumor segmentation. However, its accuracy is not good enough to compete with the other methods. In 2017, our method was able to classify the whole tumor using the BRATS dataset. The complexity of the structures involved in the segmentation process is one of the main factors that prevents it from performing well in the enhanced and necrotics regions. Through the proposed method, the paper was able to improve the accuracy of this process. However, it is not enough to perform well in these regions.
Haq et al.15—The goal of this study was to classify the various types of brain tumors using the HBTC framework, we first performed the TACS scheme, which is a combination of methods such as image noise reduction, hybrid K-S-L, and histogram equalization. After extracting the textures from the tumors using different extraction techniques, a dataset was generated. The framework used a hybrid approach to improve the performance of its feature. The study analyzed the various models used in the classification of brain tumors, such as the J48, MB, and RT. It found that the MLP model was the most accurate one.
Srinivas et al.16—The study utilized a novel transformer design to improve the detection and classification of brain tumors. Through a combination of the firefly algorithm and an efficient image transformer, the model was able to achieve a 99.7% accuracy on Kaggle benchmarks. The goal of the FA was to optimize the hyperparameters of the DeiT model. This resulted in improved performance and decreased training loss. Although the results of the study are encouraging, further studies are needed to confirm its accuracy and explore the computational efficiency of the model.
Ahmed et al.17—The goal of this study was to design a Vision Transformer structure that can be used to classify different types of brain tumors. The ViT model was created by training it on its own and using advanced AI techniques to visualize its features. It performed well in a validated test, achieving a 91.61% accuracy rate, which was higher than the 83.37% of a comparable model. The ViT model was trained using various AI techniques to visualize its features. It performed well in a validated test, achieving a 91.61% accuracy rate, which was higher than the 83.37% of a comparable model.While demonstrating strong performance, the study’s limitations include the use of a single dataset, potentially limiting generalizability. Further validation on diverse datasets with varying image quality and tumor subtypes is necessary. Additionally, the computational demands of ViT models may pose challenges for real-time clinical application. Future research could explore model optimization strategies to address this limitation.
Gade et al.18—This study proposed an Optimized Lite Swin Transformer model for brain MRI analysis, addressing the limitations of CNNs in capturing global features. OLiST combined features extracted from both a Lite Swin Transformer and a CNN, leveraging the strengths of each. A Barnacles Mating Optimizer further enhanced performance by tuning hyperparameters. Evaluated on an open-source brain tumor dataset from Kaggle, OLiST demonstrated improved classification results and reduced processing time compared to established transfer learning methods. However, the study’s limitations include reliance on a single dataset, potentially affecting generalizability. Further validation on diverse datasets with varying image modalities and pathologies is warranted. Additionally, the computational cost of transformer-based models, even optimized versions, may pose challenges for real-time clinical applications.
Proposed framework for detecting brain tumour using CNN-SVM
The goal of this study is to develop a method that can automatically categorize brain tumors into various pathological categories. This method would be useful in identifying and treating brain tumors that are difficult to classify. There are numerous techniques that are currently being used to perform this procedure. The first step in the classification process of a brain tumor is to identify its characteristics. This step involves performing a feature extraction and segmentation process. The former aims to improve the accuracy of the method by adding more informative features. In previous studies, various methods such as wavelet transform, first-order statistics, and Gabor filters have been used to describe brain tumors. Intensity-based features and textures can help visualize the characteristics of brain tumors, but they are not as robust as other techniques when it comes to image classification and retrieval.
A deep neural network known as CNN uses a combination of the layers of its network to filter the inputs for various applications. Its goal is to provide a representation of both the temporal and spatial features of an image. To achieve this, a weight sharing method is implemented. Figure 1 shows the General CNN Architecture. CNN is composed of three building blocks. One of these is a convolutional layer, which learns the spatial and temporal details of an image. The other two are subsampling layers and a fully connected layer. These allow it to classify an image into different classes.

General CNN architecture.
The paper presents the concept of support vector machine, which is a type of classification that is used in an ANN framework. According to the studies, it can perform better than the Softmax function. One of the main disadvantages of this method is that it only classifies binary values. As SVM aims to find the optimal hyper plane for a given dataset, it is not always feasible to consider a multinomial case. With the use of this method, the case becomes a one versus-all, with the positive class representing the highest score, while the negative class is the lowest score.
Dataset description
In medical imaging, the data generated by brain CE-MRI are only limited by the slice gap, and this makes it difficult to build a 3D model. This paper proposes a method that takes into account the two-dimensional slices of the data. From 2005 to 2010, the data was collected from two hospitals in China: General Hospital of Tianjin University and Nanfang Hospital19. The images are equipped with a resolution of 512 × 1024 pixels and a slice that is 6 mm thick. The data was split into a pair of datasets. The training dataset trained the model while the testing dataset performed the feature extraction.
Brain tumour detection using DCNN-SVM
A novel framework is built on a DCNN and a SVM algorithm to perform generative model analysis on large datasets. The main objective of this method is to reduce the number of data elements needed to perform a successful NN model. In order to achieve this, the framework uses an unsupervised method known as ICI. Figure 2 shows the Proposed DCNN-SVM Architecture. The framework’s main objective is to retrieve the independent observations that are linearly dependent on another variable. It then takes into account the correlation among the data and then decorrelates the results by minimizing or maximizing the C-value.

Proposed DCNN-SVM architecture.
The yield of feature maps is computed by the DCNN-SVM layer’s learned convolution kernal. The derivatives of this layer are then used to frame the feature maps. The down sampling layer takes advantage of LBP-ICA to classify two-dimensional features. The output layer is composed of a support vector machine. When choosing a nonlinear function, the activation function chooses one that fits the model’s nonlinearity. The derivability and monotonicity of the activation function are taken into account.
Data augmentation
The inherent variability in brain MRIs can hinder the generalization capacity of deep convolutional neural networks designed for differential diagnosis. To mitigate overfitting stemming from this variability, this study employed several data augmentation techniques. Following pre-processing and augmentation of the original dataset, a total of 25,000 MR brain images were generated, comprising both normal and abnormal samples. The augmented dataset, derived from the TUCMD database, includes 7,000 normal and 9,000 abnormal MR brain images. The training process involved the use of a fivefold crossvalidation strategy, wherein each fold produced around 1,800 abnormal and 1,400 normal images. The goal of this method is to enhance the generalizability and robustness of the deep CNN model by allowing it to interact with various variations in the dataset.
Deep feature extraction using local binary pattern
The goal is to develop a deep learning framework that can retrieve the details of brain scans. Unfortunately, implementing deep CNN on a large scale would be impossible due to the amount of data involved and training tools that would be required. Instead, a framework is built using a LBP. It then trains its model on an augmented dataset in order to extract the most relevant details.
Texture feature extraction
The LBP values and the C measure were calculated from the various voxels in the data set, which were selected for their respective MR and ROI image types. Three different combinations of samples and the neighborhood radius were used to arrive at the values. The various features of the LBP and C values were then analyzed to determine their distributions. These features were then classified and selected to produce 8 features for each of the three image types.
The LBP feature, which is used in various applications, including image analysis, provides a high-performance representation of texture. It combines the power of statistical and computational methods to create a unique and precise representation of texture. An image contrast measure is also added to the feature to enhance its discriminative power. The LBP feature takes into consideration the various properties of textures, such as their rotation and gray scale. It first defines the texture T in the image’s local region, which is composed of the gray levels and the joint distribution of the image.
The gray value of a local neighborhood’s center pixel is known as the gc value. When the coordinates of gc are 0, 0, and 1, respectively, the value of the neighbor set is given by the circle of radius R, which is composed of symmetrically symmetric pixels. The value of the neighbors whose coordinates are not exactly in the center of the pixels is computed by interpolating.
The value of the center pixel is taken from the GP’s gray values. This allows us to achieve a gray-scale invariance.
By expecting that distinctions between and are free of, T can be acquired.
The distribution of an image is described in terms of its overall image luminance. It is not related to the local image texture.
conveys a lot of the original textural characteristics.
Invariance can be achieved by considering the signs of a difference instead of the exact values.
where
Each sign is assigned a binomial factor 2p, which is used to transform it into a unique spatial structure. This number is known as the Local Image Texture Prediction.
The LBPri P is a unique identifier for the rotation invariant binary patterns. It can be used to identify each pattern in a set of unique sequences.
ROR(x, i) repeatedly performs a circular bitwise right shift on the P-bit number.
The texture attributes are influenced by the presence of particular types of binary patterns. Circular frameworks with minimal spatial transitions are commonly used as templates for various materials. The uniformity of the resulting patterns is attributed to the number of transitions in their spatial structure. Uniform uniformity refers to the number of transitions in a given local binary pattern. If the U value of 000000002 and 1 is 0 and 2, respectively, then these patterns are considered uniform. Likewise, if the U value of 111111112 and 2 is at least 2, then these patterns are also considered uniform.
where
The representation of a neighbor in Fig. 3 is as one if its pixel value is equal or higher than zero or if its value is lower than zero. In an anti-clockwise direction, every neighbor is multiplied by 2 and summed as shown in (b). The left (Fig. 3a) and right (Fig. 3b) figures represent the varying radius and samples sizes in a given neighborhood.

(a) LBP thresholding. (b) Change of radius based on neighbourhood.
The riu2 superscript shows how rotation invariant patterns can be distinguished from non-uniform patterns by having a U value of 2. The “uniform” patterns can be found in a set of P pixels with a circular symmetry, while the non-uniform ones are grouped together under a labeled label.
Contrast
The LBPriP, and LBPriu2P, operators are good at identifying spatial patterns, they discard contrast when it comes to measuring the local image texture. If the invariance requirement is not met, a rotation invariant measure of the local variance can be used.
Which is unaffected by gray-scale shifts.
The values of C and LBP are used to create an image that is represented by a histogram. They are typically represented as the same type of data set’s histogram for every instance. There are a variety of ways to interpret these values, such as by creating new features.
Independent component analysis (ICA) for feature reduction
The high feature vector can increase the computation time and memory requirements, which can lead to misclassification and complicated implementations. A method known as Principal Component Analysis is used to reduce the feature vector dimension. The mean square optimal projection of a given data is achieved by using second order statistics. However, this method is not ideal for capturing the invariant features that are not considered by the PCA. In this paper, the proposed method uses an independent component analysis to reduce the feature vector. The use of an independent component analysis method known as the ICA improves the efficiency of the second order statistics in capturing the invariant features in the hyper spectral image data sets. It also helps in the classification of brain tumors.
One of the more popular higher-order methods is the Incoherent Calibrator (ICA). It shows linear projections but not necessarily linearly. Its uncorrelatedness is stronger than that of other methods. The random variables x and xp are said to be independent of each other.
In order to achieve the goal of independent property, the main requirement of the function is factorization of its multivariate probability density.
The independence property is not related to the vice versa. However, if the function f(x1,…xp) is multivariate normal, then the two are equivalent. An integral function of the k-dimensional random vector x follow is used to evaluate the components of the p-dimensional matrix.
The components of a k-dimensional vector s model are as independent as possible. To ensure that the model is not only accurate, but also can be easily identified, a non-Gaussian component has to be included. This method takes into account 13 features such as Mean, Standard-Deviation, Entropy, Variance, Skewness, IDM, Contrast, Energy, Homogeneity, and Kurtosis.
Fully connected layer (classification)
In this study, by modifying the last three layers of CNN’s architecture, we were able to fine-tune the models for our target domain. A new layer was added to the FC architecture. This replaces the original layer. The classification and Softmax layers were also replaced. We used a classification framework known as SVM to classify the deep CNN features. It is part of the supervised learning category. The popularity of this framework has been attributed to its promising results. It is used in various machine learning studies. It is very efficient when it comes to dealing with high dimensional spaces.
Classification of the brain using MRI typically involves extracting and engineering features manually. These techniques have limitations when it comes to capturing the intricate details and minor variances that can be observed in brain imaging. CNNs, which are commonly used for classification of brain images, have demonstrated promising results. These are especially useful in addressing issues related to computer vision. Due to the recent advances in deep learning and CNNs’ use in addressing vision problems, this technology has gained widespread popularity.
Besides CNNs, Support Vector Machines are also becoming popular in helping solve complex classification problems. These are capable of handling large feature spaces and performing well in multi-class classification tasks. Support vector machines are designed to find a suitable hyperplane that can handle various classes in a feature space. By merging the capabilities of CNNs and SVMs, a brain MRI classification solution can be achieved with remarkable accuracy and resilience. The two approaches will allow us to fully utilize their respective advantages.
A neural network is composed of a loss function that is used to calculate the errors of its network. It is then used to update the weights of its network. This method is carried out using a support vector machine, which is designed to provide deep learning with a learning framework. The SVM algorithm is a powerful classification tool that takes into account the data space’s original dimensions and transforms it into a new dimension.
The paper presents three datasets: xn, yn, and Lagrange Multiplier. The first two are collections of binary representations of abnormal and normal features. The third one has four classes, including glioma and meningioma.
The SVM algorithm is a widely used framework that can be used to implement various types of kernel functions, such as the RBF, the linear, and the sigmoid. The two key hyper-points of the algorithm are the C and gamma. The former is used to measure the influence of the support vector, while the latter is used to analyze the soft margin cost. The gamma hyper-parameter is a part of the algorithm that determines the amount of curvature that needs to be added to a decision boundary. The values of the C and gamma are set to, and they are chosen with the highest accuracy.
This enables a efficient classification of the types of tumour.
Result and discussion
Dataset description
The data was collected from two hospitals in China: the General Hospital of Tianjing Medical University and the Nanfang Hospital in Guangzhou. The images were taken from over 200 patients. The thickness of the slices was 6 mm, and the gap between them was 1 mm. Three radiologists manually identified the border of the tumors.
The four major tumor regions are shown in Fig. 4. They are: ED, NCR, ET, and NET. The goal of this study was to refine the tumor core so that it can be easier to observe.

Tumor area division of glioma.
Data augmentation
The training set contains around 2084 images. For the proposed CNN’s training phase, we use 200 iterations to produce various training examples. Each iteration is augmented only once. Also, each epoch is produced with original images from the mini batch. For 200 iterations, the training images are able to produce a total of 2084 × 2084.
A series of geometric transformations are performed on the training set to improve the efficiency of data augmentation. The first step is to transform each image by performing horizontal flip and vertical filliping. Then, rotation with a range of 0 to 60 degrees is done. Objects that are not placed in the center of the image may be off-centered in various ways. This is why it is important to perform random horizontal and vertical shifting to detect these objects. Besides horizontal and vertical filliping, it is also known as height shifting and width shifting. The range of both shifting and vertical filliping is set at 0.20. To zoom in on the image randomly, the range of both shifting and vertical filliping is applied. Then, a shear mapping procedure is performed to displace the image vertically or horizontally with the range of (x,y, or + 0.2). Figure 5 shows the Data augmented MRI image.

Data augmented MRI image.
Classification performance
While Deep Convolutional Neural Networks excel at feature representation, their deep architectures and reliance on supervised learning can lead to overfitting, particularly in medical contexts where training data is often limited. The large number of parameters within a differential DCNN exacerbates this tendency towards overfitting when the available data is insufficient.
The architecture of the differential deep CNN mirrors the original CNN, maintaining identical configurations for convolutional and pooling layers. This architecture comprises five convolutional layers with 48, 20, 20, 8, and 4 feature maps, respectively. The first two convolutional layers employ 2 × 2 feature maps, while the remaining three utilize 3 × 3 feature maps. Each convolutional layer is followed by a pooling layer.
A convolutional neural network architecture was developed using TensorFlow and Keras within the Spyder 3.7 environment. Training and testing were conducted on a proprietary dataset, TUCMD, to evaluate and analyze various performance factors of the differential deep CNN model.
The differential D-CNN employs a single-depth expansion of convolutional layers through convolution of original feature maps with pre-defined filters, avoiding an increase in the number of layers. This approach allows the differential feature maps to capture multi-directional variations, enhancing the model’s ability to identify the base template image and improve classification accuracy. Consequently, the use of a differential deep-CNN architecture leads to improved classification performance.
The goal of this paper is to create a robust and efficient tool that can be used to classify the input of MRI brain images into three categories: meningioma, glioma, and pituitary tumors. Table 1 summarizes the proposed performance metrics for the classifier. The basis for its evaluation lies in the unique attributes of the acquired data set. The classification of the brain tumors presented in Fig. 6 is as follows: meningioma, pituitary, and glioma.

Brain tumor classification: meningioma, glioma and pituitary tumor.
Performance evaluation with minimum amount of data
The performance of the three proposed models is shown in terms of segmentation in 26 patients. The models were utilized to train and segment brain tumors. The study’s findings were shown in Figs. 7 and 8.

SVM segmentation results for 26 patients.

DCNN-SVM segmentation results for 26 patients.
Figure 9 shows the floating error of the index values is generally around 0.18. This section displays the sensitivity, specificity, and DSC values. The DSC value is typically around 0.89.

Comparison of DSC, specificity, and sensitivity.
Figure 9 shows the sensitivity, specificity, and DSC values of three different techniques: CNN, DCNN-SVM, and SVM. The suggested technique can outperform the two existing methods when utilized independently.
After training, the model can confidently predict the results of the test set, which will be used to analyze the glioma segmentation results. Figure 9 shows the various evaluation index pairs of the models in the test set. The proposed model outperforms CNN and SVM in tumor segmentation. The proposed model performed better than SVM when it comes to analyzing the results of the test set. It also improved its sensitivity, specificity, and DSC levels when compared to CNN.
The Fig. 10 shows the performance of the proposed framework against the existing techniques. It shows that the proposed framework has greater accuracy. Several studies have explored brain tumor classification using various techniques and datasets. Cheng et al.20 achieved 91.28% accuracy with SVM and KNN on a dataset of T1-weighted contrast-enhanced MRI scans. Paul et al.21 and Afshar et al.22 used CNNs on similar datasets, achieving 91.43% and 90.89% accuracy, respectively. Anaraki et al.23 improved upon this with a genetically optimized CNN, reaching 94.20%. Bahadure et al.24 used a different approach (BWT + SVM) on T2-weighted images, achieving 95% accuracy on a smaller dataset. Ansari et al.25 achieved the highest accuracy among the prior works (98.91%) using a combination of DWT, PCA, GLCM, and SVM on a smaller T1-weighted CE-MRI dataset. Sultan et al.20 also employed a CNN on the larger dataset, achieving 96.13% accuracy. The proposed DCNN-SVM system in this study achieved the highest overall accuracy of 98.96% on the same large dataset as Cheng et al., Anaraki et al., and Sultan et al., suggesting a significant improvement over existing methods.

Performance comparison of existing and proposed techniques.
This Fig. 11 presents an evaluation of the performance of various ML models on a classification task, which is presumably related to medical imaging research. The CNN-SVM hybrid model has the highest accuracy, beating other approaches. Specifically, it surpasses CNN-SVM-kNN (97%)19, two different GAN-based approaches (96.25% and 96%)26, MANet (97.71%)27, BW-VGG19 (98%)28, and FT-ViT (98.13%)29. This suggests that the combination of CNNs for feature extraction and SVMs for classification, as employed in the proposed methodology, offers a more effective approach compared to the alternative methods listed. The superior performance of the proposed CNN-SVM model may be attributed to the synergistic combination of CNNs’ ability to learn hierarchical features and SVMs’ strength in handling high-dimensional data. However, the specific task and dataset used for evaluation are not provided, making it difficult to draw definitive conclusions about the generalizability of these results.

Performance graph for different deep and transfer leaning algorithm.
Conclusion
Through the next phase of the study, the researchers will develop a method that can be used to detect brain tumors using an independent analysis. This method would allow them to improve the accuracy of their diagnosis. They will also develop a deep classifier that can improve the accuracy of their diagnosis. The proposed model is composed of a series of components, such as a deep learning network (DCNN) and a standard variable matrix (SVM). The first phase of the study involves training a DCNN to map the different regions of the tumor using the LBP and ICA. The predicted labels are then taken into the SVM classifier. In phase three, the proposed model is trained using a series of connections between deep learning networks. This method allows it to achieve a 99.6% accuracy rate and a sensitivity of 0.973%. It is also more accurate against the different types of brain tumors and the tests are conducted in nondestructive manner.
Data availability
All data generated or analyzed during this study are included in this published article [and its supplementary information files].
References
Amin, J., Sharif, M., Yasmin, M. & Fernandes, S. L. A distinctive approach in brain tumor detection and classification using MRI. Pattern Recogn. Lett. 139, 118–127 (2020).
Abd-Ellah, M. K., Awad, A. I., Khalaf, A. A. & Hamed, H. F. A review on brain tumor diagnosis from MRI images: Practical implications, key achievements, and lessons learned. Magn. Reson. Imaging 61, 300–318 (2019).
Iqbal, S., Khan, M. U. G., Saba, T. & Rehman, A. Computer-assisted brain tumor type discrimination using magnetic resonance imaging features. Biomed. Eng. Lett. 8(1), 5–28 (2018).
Jemimma, T. A. & Raj, Y. J. V. Brain tumor segmentation and classification using deep belief network. In 2018 Second International Conference on Intelligent Computing and Control Systems (ICICCS) 1390–1394 (IEEE, 2018).
Sami, A. S., Rahim, M. S. M., Ahmed, F. Y. & Sulong, G. B. A review study of methods utilized for identifying and segmenting the brain tumor from MR imageries. J. Theor. Appl. Inf. Technol. 97(11) (2019).
Joya, J. S., Thomasb, R. & Johnsonc, J. A review of brain tumor segmentation on MRI image using machine learning algorithm. Cancer Res. 1(1) (2021).
Badža, M. M. & Barjaktarović, M. Č. Classification of brain tumors from MRI images using a convolutional neural network. Appl. Sci. 10(6), 1999 (2020).
Del Campo, F. A., Villegas, O. O. V., Sánchez, V. G. C., Tena, L. A. G. & Nandayapa, M. Influence of image pre-processing to improve the accuracy in a convolutional neural network. Int. J. Comb. Optim. Probl. Inform. 11(1), 88 (2020).
Abiwinanda, N., Hanif, M., Hesaputra, S. T., Handayani, A. & Mengko, T. R. Brain tumor classification using convolutional neural network. In Proceedings of the World Congress on Medical Physics and Biomedical Engineering 2018, Prague, Czech Republic, 3–8 June 2019 183–189 (2019).
Seetha, J. & Raja, S. S. Brain tumor classification using convolutional neural networks. Biomed. Pharmacol. J. 11, 3 (2018).
Sajid, S., Hussain, S. & Sarwar, A. Brain tumor detection and segmentation in MR images using deep learning. Arab. J. Sci. Eng. 44, 9249–9261 (2019).
Almadhoun, H. R. & Abu-Naser, S. S. Detection of brain tumor using deep learning. Int. J. Acad. Eng. Res. IJAER 6(3).
Methil, A. S. Brain tumor detection using deep learning and image processing. In 2021 International Conference on Artificial Intelligence and Smart Systems (ICAIS) 100–108 (IEEE, 2021).
Alqazzaz, S., Sun, X., Nokes, L.D., Yang, H., Yang, Y., Xu, R., Zhang, Y. & Yang, X. Combined features in region of interest for brain tumor segmentation. J. Digit. Imaging 1–9 (2022).
Haq, I., Ullah, N., Mazhar, T., Malik, M. A. & Bano, I. A novel brain tumor detection and coloring technique from 2D MRI images. Appl. Sci. 12(11), 5744 (2022).
Srinivas, B., Anilkumar, B., Devi, N. & Aruna, V. B. K. L. A fine-tuned transformer model for brain tumor detection and classification. Multimed. Tools Appl. 1–25 (2024).
Ahmed, M. M. et al. Brain tumor detection and classification in MRI using hybrid ViT and GRU model with explainable AI in Southern Bangladesh. Sci. Rep. 14(1), 22797 (2024).
Gade, V. S. R., Cherian, R. K., Rajarao, B. & Kumar, M. A. BMO based improved Lite Swin transformer for brain tumor detection using MRI images. Biomed. Signal Process. Control 92, 106091 (2024).
Deepak, S. & Ameer, P. Brain tumor classification using deep CNN features via transfer learning. Comput. Biol. Med. 111, 103345 (2019).
Sultan, H. H., Salem, N. M. & Al-Atabany, W. Multi-classification of brain tumor images using deep neural network. IEEE Access 7, 69215–69225 (2019).
Paul, J. S., Plassard, A. J., Landman, B. A. & Fabbri, D. Deep learning for brain tumor classification. In Medical Imaging 2017: Biomedical Applications in Molecular, Structural, and Functional Imaging, Vol. 10137 (eds Krol, A. & Gimi, B.) 1013710 (SPIE, 2017).
Afshar, P., Plataniotis, K. N. & Mohammadi, A. Capsule networks for brain tumor classification based on MRI images and coarse tumor boundaries. In ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 1368–1372 (2019).
Anaraki, A. K., Ayati, M. & Kazemi, F. Magnetic resonance imaging-based brain tumor grades classification and grading via convolutional neural networks and genetic algorithms. Biocybern. Biomed. Eng. 39(1), 63–74 (2019).
Bahadure, N. B., Ray, A. K. & Thethi, H. P. Image analysis for MRI based brain tumor detection and feature extraction using biologically inspired BWT and SVM. Int. J. Biomed. Imaging 2017(1), 9749108 (2017).
Ansari, M. A., Mehrotra, R. & Agrawal, R. Detection and classification of brain tumor in MRI images using wavelet transform and support vector machine. J. Interdiscip. Math. 1–12 (2020).
Ahmad, B., Sun, J., You, Q., Palade, V. & Mao, Z. Brain tumor classification using a combination of variational autoencoders and generative adversarial networks. Biomedicines 10(2), 223 (2022).
Shaik, N. S. & Cherukuri, T. K. Multi-level attention network: Application to brain tumor classification. Signal Image Video Process. 16(3), 817–824 (2022).
Asiri, A. A. et al. Multi-level deep generative adversarial networks for brain tumor classification on magnetic resonance images. Intell. Autom. Soft Comput. 36, 127–143 (2023).
Asiri, A. A. et al. Block-wise neural network for brain tumor identification in magnetic resonance images. Comput. Mater. Contin. 73, 5735–5753 (2022).
Author information
Authors and Affiliations
Contributions
C.G.: Conceptualization, Data curation, Formal analysis, Methodology, Validation, Writing—original draft; K.S. B.: Conceptualization, Supervision, Visualization, Writing—review & editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Gunasundari, C., Selva Bhuvaneswari, K. A novel approach for the detection of brain tumor and its classification via independent component analysis. Sci Rep 15, 8252 (2025). https://doi.org/10.1038/s41598-025-87934-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-87934-4
