
Abstract
Accurate estimation of the solubility of solid drugs (SDs) in the supercritical carbon dioxide (SC-CO2) plays an essential role in the related technologies. In this study, artificial intelligence models (AIMs) by gene expression programming (GEP) and adaptive neuro-fuzzy inference system (ANFIS) methods were applied to estimate the solubility of SDs in SC-CO2. Hence, a comprehensive database (1816 datasets) comprising operational conditions (T, P) in the wide ranges (308–348.2 K and 80–400 bar), SD’s molecular weight (MWSDs), and melting point (MPSDs) were gathered. Investigation analysis of the models’ strength showed that the model developed by ANFIS exhibited a more satisfactory approximation than the GEP model. According to the optimized ANFIS model, statistical parameters of R2, RMSE, MAE, and AARD% were obtained, equivalent to 0.991, 0.260, 0.167, and 13.890% for training and 0.990, 0.256, 0.157, and 15.273% for validation, in that order. Sensitivity analysis showed that the highest effect of independent variables on calculating SDs solubility in SC-CO2 belong to MWSDs, P, MPSDs, and T, respectively. Therefore, MWSDs is a key factor for modeling the solubility of various SDs in SC-CO2. Comparing the estimated results obtained from the optimized AIM with previous semi-empirical models showed that the AIMs could be more accurate in modeling the solubility of SDs in SC-CO2.
Similar content being viewed by others
Introduction
In recent years, supercritical fluid (SCF) technology has garnered significant attention as an environmentally friendly option due to its unique characteristics such as low viscosity, high diffusion capabilities, strong solvation capacity, and excellent selectivity. Regarding polar compounds, while SC-CO2 has moderate or even minimal solubility, it remains the most prevalent SCF due to numerous unique traits like low critical temperature and pressure, non-flammability, non-explosiveness, non-toxicity, economic efficiency, and particularly its ease of separation and recycling1. SC-CO2 has demonstrated significant capabilities in diverse domains, energy2, comprising nanoparticle formation3, food4, extraction of essential oil5, seed oil6, solubility7, anti-cancer drugs8,9, polymer synthesis5, impregnation10, optimization and mathematical modeling11, etc. Several studies showed that the micronization of a drug leads to improving the performance and absorption in the body and reducing side effects initiated from using the drug12. For this purpose, various methods such as grinding, recrystallization, spray-drying, freeze-drying, and crystallization have been utilized up to now. These prevalent micronization techniques are associated with issues such as significant thermal stress, thermal degradation, broad particle size distribution, and elevated residual solvent in the end product. Recently, new SCF-based technologies have arisen to achieve a high-quality product with a consistent particle size distribution13.
The key and fundamental effective factor in SCF extraction processes is the precise understanding of the equilibrium solubility of substances. Despite various methods to experimentally determine drug solubility, a specific set of conditions and tools is necessary due to their intricate and sensitive designs14. The difficulty and expense of obtaining equilibrium data at high pressures and temperatures increase the need to estimate drug solubility in SC-CO215. The solubility of SDs in SCF can be estimated through thermodynamic equations of state (EoSs), fluid density-based experimental and semi-experimental models, solution activity coefficient-based models, and artificial intelligence techniques16.
Numerous experimental investigations were conducted in the field of the solubility measurement of SDs in SC-CO2, which are given in Table 1. Some of these researchers presented experimental and semi-experimental models as follows. Sodeifian et al. measured the solubility of imatinib mesylate in SC-CO2 and analyzed the data using two sets of procedures involving three EoSs and six semi-experimental models. Their findings highlighted the effectiveness of the Haghtalab et al. EoS with the VdW2 mixing rule over other models. They subsequently introduced a new model, named Sodeifian et al., which incorporates six adjustable parameters and accurately estimates the experimental solubility of imatinib mesylate17. Housaindokht and Bozorgmehr estimate the solubility of three SDs in SC-CO2. The estimation was performed by three EoSs (Peng-Robinson, modified Peng-Robinson and Pauzuki) as well as three mixing rules (VdW1, VdW2 and Adachi-Sugi). The optimal outcome was obtained from the Pauzuki equation with the VdW2 mixing rule18. Huang et al. measured the solubility of aspirin in SC-CO2 with and without two solvents of ethanol and methanol. Then they estimate experimental data with the Peng-Robinson EoS and VdW mixing rule. Peng-Robinson EoS with an average absolute relative deviation (AARD) of (14–23%) showed good accordance between both experimental and estimated data19. Ardestani et al. measured the solubility of capecitabine using seven experimental models and three EoSs combined with the mixing rule. The EoS of PR-VdW2 (AARD = 20.32%) could estimate the solubility better9.
Recently, machine learning technology has been widely used as estimation tools across various scientific fields, such as estimating the solubility of solid materials in SC-CO2. This approach will reduce massive numerical calculations and expenses if a suitable thermodynamic model is provided20. One of the most famous of them is the artificial neural networks (ANNs) operate as a powerful methodology for the comparison and modeling of complex nonlinear problems, facilitating the estimation of solutions for such challenges. Sodeifian et al. studied the solubility of six pharmaceutical compounds in SC-CO2 using four different models: cubic EoS, empirical and semi-empirical models, regular solution with the Flory-Huggins equation, and ANN. comparing results indicated that the ANN-based model provided the best results in terms of correlating the experimental solubility of the pharmaceutical compounds in SC-CO220. Yang et al. measured the solubility of silymarin in pure SC-CO2 and with a cosolvent. They used three semi-experimental models and one backpropagation artificial neural network (BPANN) model to estimate solubility and compared the results to experimental data. The BPANN model demonstrated higher accuracy, with an AARD of 1.14–2.15%21. Mehdizadeh and Movagharnejad estimated the solubility of thirty different compounds in SC-CO2 using seven semi-experimental models and compared the results to those obtained from an ANN. The ANN method showed greater precision, with an average relative deviation (ARD) of 5.3%, compared to 15.96% for the best semi-experimental equation. Additionally, the ARD of the semi-experimental equations varied significantly across different compounds, whereas the ANN method exhibited more consistent performance regardless of the material type22. Dadkhah et al. estimated the solubility of solid substances in SC-CO2 by employing the adaptive neuro-fuzzy inference system (ANFIS) model. The model’s input parameters include several thermodynamic properties of the compounds, such as critical temperature, critical pressure, acentric factor, critical molar volume, as well as operational temperature and pressure. The correlation coefficient and The Root Mean Square Error (RMSE) values for all the data were found to be 0.983 and 0.156, respectively. The results of the model comparison showed that the ANFIS model performs superiorly to the FFNN model in estimating the target data23. Pishnamazi et al. measured the solubility of busulfan, which is an SD to treat blood cancer, in SC-CO2 using five semi-experimental models, the KJ model (AARD = 7.57%) presented a more suitable estimation of solubility24. Zhu et al. estimated the solubility of busulfan in SC-CO2 using ANFIS. The results showed that the ANFIS model can be utilized to precisely estimate the solubility of drugs in supercritical solvents8.
The literature includes only a few general semi-empirical models for estimating the solubility of solids in SC-CO₂25,26,27. The primary drawback of these models is that the parameters of the model for a particular solid must be determined solely by utilizing its own experimental solubility datasets. This makes it difficult to use easily and restricts the model’s performance to apply for other SDs.
According to the literature, there is no rigorous model to estimate the solubility of a specific SD in SC-CO2 without needing its sufficient experimental datasets used to fit the coefficients of semi-empirical models. On the other hand, the empirical determination of the solubility of solids under broad conditions is not only often troubled but also requires a significant amount of cost to carry out28,29,30. To address this challenge, the present study aimed to estimate the solubility of SDs in SC-CO2 using AIMs. The selected models include GEP and ANFIS. These models offer several advantages, including reduced time required and the ability to model complex nonlinear processes due to having a number of controllable parameters, which enhances the algorithm compared to other methods31. In order to derive the rigorous AIMs, a comprehensive data collection including some SDs properties additional to operating conditions were gathered. Using SDs properties as the input variables enables the model to estimate the solubility of an SD in SC-CO2 without applying its particular experimental datasets. The input variables of the AIMs were operational temperature and pressure (T, P), SDs’ molecular weight (MWSDs), and melting point (MPSDs). Coefficient of determination (R2), root mean square error (RMSE), mean absolute error (MAE), and the percent of Average absolute relative deviation (AARD%), as statistical parameters, were employed to evaluate and validate the results and to select the best model.
Artificial intelligence modeling
Data gathering
The data required for the AIMs was collected by gathering a comprehensive data collection (1816 dataset) from previous studies, as shown in Table 1. Consistent with Fig. 1, the experimental data of T, P, MWSDs, and MPSDs variables were selected as the input variables to estimate the solubility of SDs in SC-CO2. In the current AIMs, a wide range of T, P, MWSDs, and MPSDs were investigated, as presented in Table 2.

Schematic diagram of the AIMs.
Gene expression programming (GEP)
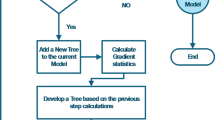
GEP is a combination of genetic algorithms and genetic programming that is based on Darwin’s theory and was developed by Ferreira in 199990. In this method, at the first stage, the initial population of chromosomes are generated randomly or based on input information. The chromosomes are then evaluated as expression trees. If an optimal solution is found, or the number of generations reaches a specified limit, evolution stops, and the best solution is presented. Otherwise, selection is performed, and the process is repeated for several generations to improve the quality of the population. Figure 2 presents the flowchart of GEP90. Figure 2 presents the flowchart of GEP.

The GEP flowchart90.
Development GEP model
The procedure GEP utilizes to present a nonlinear function is mentioned below:
-
Entering data: 80% of datasets were selected for training, and 20% of them were selected for validation. The data was randomly selected and introduced to the software. Afterward, the estimator variables and response were identified.
-
The preparation of information: Given that the input variables had various ranges and entering raw-form data led to reducing the rate and accuracy of the model, a normalization process was employed to equalize the range of the data, as well as to accomplish better training. The Min-max normalization was conducted by Eq. (1):
Where \(\:{\text{v}}^{{\prime\:}}\) is the normalized data, \(\:{\text{v}}_{\text{m}\text{a}\text{x}}\) and \(\:{\text{v}}_{\text{m}\text{i}\text{n}}\) are the maximum and minimum values of the data and \(\:{\text{v}}_{\text{n}\text{e}\text{w}-\text{m}\text{a}\text{x}}\) and \(\:{\text{v}}_{\text{n}\text{e}\text{w}-\text{m}\text{i}\text{n}}\) are the range in which the datas were normalized, respectively91.
-
Adjusting parameters: The setting of GEP includes some steps as below:
-
(1)
The determination of the chromosome’s structure (number of chromosomes; head size; number of genes).
-
(2)
The determination of the linking function which determines the relationship between sub-ET (expression tree).
-
(3)
The determination of fitness function.
-
(4)
The selection of genetic operators, including mutation, IS transposition, RIS transposition, etc., and the determination of their rate.
-
(5)
The use of random numerical constants.
The optimal parameters concerning the GEP model settings are given in Table 3. The defaulted values of the software were used for other parameters92.
-
Selection of functions: as shown Table 4, a collection of functions was selected for modeling. Moreover, the stop condition was MAX fitness. The output of the model is shown in Fig. 3 as tree expression.

Expression tree structure for the best GEP model.
The adaptive neuro-fuzzy inference system (ANFIS)
ANFIS is a powerful technique in intelligent computational modeling. This method combines the learning capabilities of ANNs and the logical reasoning of Fuzzy Inference Systems (FIS) to overcome the disadvantages of each. FIS is designed based on “if-then” rules and appropriate membership functions to create an input-output relationship. ANFIS consists of six main sections: data preparation, ANFIS creation, variable selection, training, validation, and output generation, and includes five layers as shown in Fig. 4: Fuzzification Layer, Rule Layer, Normalization Layer, Defuzzification Layer, and Summary Layer. This structure allows ANFIS to effectively process inputs and generate accurate output93,94. The flowchart of ANFIS is presented in Fig. 5.

ANFIS structure.

The ANFIS flowchart.
Development ANFIS model
In order to develop AIM based on ANFIS the follow steps were done:
-
Entering data: Similar to the GEP model, 80% of datasets were selected for training, and 20% of them were selected for test and check.
-
The preparation of information: For the purpose of increasing accuracy and speed of AIM based on ANFIS, all datasets comprising the inputs and the targets were normalized between [− 1, 1] according to Eq. (1).
-
The preparation of information: For the purpose of increasing accuracy and speed of AIM based on ANFIS, all datasets comprising the inputs and the targets were normalized between [− 1, 1] according to Eq. (1).
Adjusting parameters:
In order to develop the satisfying AIM based on ANFIS, a Takagi–Sugeno fuzzy inference system was applied by using the fuzzy c-mean (FCM) clustering algorithm. The Gaussian membership function was selected for all independent variables comprising T, P and MWSDs. The output membership function was chosen linear. Additionally, the specifications of the developed ANFIS model are presented in Table 5.
Model selection
The AIMs were implemented many times to find the optimal setting of the parameters. The best model was selected by a multi-objective strategy as follows:
-
(1)
The selection of the simplest model though this parameter is not predominant
-
(2)
The training data have the highest value of fitness
-
(3)
The validation data have the highest value of fitness
The first objective should be controlled by the user. About the other objectives, the objective function (OBJ) by Eq. (2) was defined as a criterion for the accordance of the output estimated by the model with the output experimentally measured. The selection of the best model was conducted based on the minimum OBJ value that resulted in lower AARD%95.
where Notraining and Novalidation denote the number of training and validation data, respectively, and Pij is the value estimated by the individual model i for record j (out of n records). Tj is the target value for record j96.
The created objective function considers the variations of R2, RMSE, MAE, and AARD%, which are defined in Eqs. (3–6). The higher values of R2 and the lower values of RMSE, MAE and AARD% result in reducing the objective function. Consequently, it can present a more precise model. Furthermore, the abovementioned function considers the effects of splitting data sets to the training and validation sets95.
Results and discussion
To study the behavior of the AIMs selected based on the optimized parameters, the comparison of output of the models with the training and validation experimental data is shown in Figs. 6 and 7, respectively. The results and the statistical parameters of R2, RMSE, MAE, and AARD%, presented in Table 6 indicate that the ANFIS is more satisfactory and reliable in estimating the solubility of SDs in SC-CO2 than the GEP model. Since the ANFIS model showed the higher R2 and lower RMSE, MAE, and AARD% compared to GEP model, it was applied to compare the independent variables importance, to investigate the effect of them on the response, and finally to compare the model with semi-empirical ones.

Scattergram of the experimental data versus the estimation by GEP and ANFIS models for training datasets.

Scattergram of the experimental data versus the estimation by GEP and ANFIS models for validation datasets.
As before mentioned, to evaluate the model accuracy, 10% of datasets was randomly considered as check data in the ANFIS model. Matching experimental and output values for check data including random SDs at various operating condition is clearly indicated in Fig. 8, The statistical analysis for the accordance investigation showed the R2 of 0.991, RMSE of 0.322, MAE of 0.153, and AARD% of 16.820%.

Investigation the accordance between experimental and output values for check data.
Variable importance
The sensitivity analysis of independent variables is conducted so as to estimate their relative importance in forecasting the dependent variable, which is significant to design better and optimize the related process97. GEP uses a complicated random method to calculate the variable importance of every single input variable. The importance of each independent variable is calculated by randomizing its input values and then by reducing R2 between the model output and the target. The results are normalized to nondimensionalize96. The relative importance of nondimensionalized numbers related to each independent variable produced in this study is shown in Fig. 9.

Variable importance chart for the GEP model.
As can be seen, the independent variables of T, P, MWSDs, and MPSDs are denoted by d0, d1, d2, and d3. According to Fig. 9, MWSDs, P, MPSDs, and T have the highest effect in estimating the solubility in SC-CO2, respectively.
Investigation of the effect of independent variables on the solubility in SC-CO2
Temperature effect
In the equilibrium of a pure solid (component 1) with the SCF, by assuming that SC-CO2 is not solved in the solid, and the solid molar volume is not as a function of pressure, Eq. (7) can be written as follows:
where \(\:{y}_{1}\:\)is the molar fraction of the solvent in the vapor phase, T and P are the operational temperature and pressure, respectively, \(\:{\phi\:}_{1}^{scf}\) is the solid fugacity coefficient in the supercritical phase, \(\:{\:\phi\:}_{1}^{sat}\) is the vapor fugacity coefficient originated from the solid, \(\:{\:P}_{1}^{sat}\) is the solid saturation vapor pressure, \(\:{V}_{1}^{S}\) is the solid molar volume, P1 is the solid vapor pressure, and R is the universal gas constant98.
Since the temperature enhancement can lead to increasing the solvent vapor pressure, it can also be stated that the solubility of the solid component in SC-CO2 increases (see Eq. (7)). Despite the fact that increasing temperature will lead to decreasing the density of the solvent, the study of the effect of increasing temperature on the solubility of SDs in SC-CO2 indicated that the positive effect of vapor pressure of the drug component is dominant. Figure 10a and b indicates the positive effect of temperature on the solubility of SDs in SC-CO2. The literature research also showed the similar trend in examining the effect of operating temperature on the solubility of solid materials in SC-CO2 as Ref99.
Pressure effect
Operating pressure typically demonstrates a dual influence in investigating the solid solubility in SC-CO2. In assessing the impact of pressure, one must consider two significant variables: SC-CO2 density and solubilized vapor pressure. For this objective, there exists a cross-over region for drug solubility. This phenomenon transpires when the magnitude of the two determinants of SC-CO2 density and solute vapor pressure are equivalent73,75. In other word, as pressure rises at constant temperature constant, the density of the solvent rises, whereas the vapor pressure of the solute diminishes. At higher pressures, the extent of this density alteration becomes less pronounced, and the change in solute vapor pressure becomes more significant, effectively outweighing the impact of solvent density changes on the solubility of the solute. Since many drugs were used in this study and not all of them necessarily exhibited cross-over pressure, it is not possible to select a specific pressure or range as the crossover pressure. However, this phenomenon is clearly observable at a pressure of 215 bar and a temperature range of 308–328 K in Fig. 10b drawn for Galantamine. At pressures less than this region, the density effect dominates, and solubility increases with decreasing temperature. In contrast, above this region, the vapor pressure of the solute becomes a more significant factor, and higher solubility is observed at higher temperatures. The dual effect of temperature on the solubility of various drugs in supercritical carbon dioxide has been repeatedly studied in the literature58,62,79,81. In fact, the increase of pressure leads to reducing the intermolecular distance in SCF and as a result increasing the density, which heightens the solubility. Furthermore, the solvation power of SC-CO2 increases under the influence of increasing pressure. In the simplest binary solutions of SCF, the solvation phenomenon requires the soluble molecules to be surrounded by solvent because of local clustering of solvent molecules. In a cluster, the highest number of solvent molecules is aggregated around a soluble. The increase of the number of solvent-soluble interactions created by the displacement of solvent molecules towards the potential range of solvent-soluble interaction locally increases the average density of the solvent compared to the bulk, leading to enhancing the solubility100. Qingzhao Shi et al.101 also reached the similar results with this study during investigating the effect of pressure on the solubility of n-alkanes in SC-CO2. Figure 10a indicates the positive effect of increasing operating pressure and temperature on the solubility of Flutamide as an SD in SC-CO2. While the effect of pressure is more significant compared to temperature, which is also reported in Refs24,44,45,99. The results obtained from the sensitivity analysis of the independent variables of the model in Fig. 9 also confirms this finding. Furthermore, its three-dimensional surface plot was drawn as Fig. 10b to take a broader view of the operating condition effects on the ACDs solubility in the SC-CO2. As can be seen in Fig. 10, the maximum solubility of Flutamide and Galantamine is obtained in the highest operating conditions. Therefore, it is suggested that these two variables be at the highest possible value. On the other hand, due to the increase in the process cost, the cost of the supercritical process should be considered to determine the optimal operating conditions.
It is noteworthy, Fig. 10b confirms the results reported in the literature like the surface description of the estimated solubility data for salsalate based on ANN modeling reported by Nguyen et al.102 and for busulfan based on ANFIS modeling reported by Zhu et al.8. Since both of these models are provided only for a specific SD, the operating temperature and pressure were only their independent variables. While in the current model, using the physical properties of SDs as input model variables cause to the model applicability for solubility estimate of various SDs in the SC-CO2.

Two dimensional plot for Flutamide (a) and three dimensional plot for Galantamine (b) to investigate the effects of operating temperature and pressure on SD solubility in the SC-CO2.
The effect of physical properties of SDs: MWSD and MPSD
The drugs with low molecular weight usually have higher solubility in SC-CO2. This is because smaller molecules can easily penetrate and interact with the molecular networks of carbon dioxide. Also, lower molecular weight usually means more surface area in contact with the solvent. Materials with higher molecular weight may have lower solubility in SC-CO2 due to their larger size and structural complexity28,103. In addition, the solubility of the substance depends on the type and chemical structure of the substance. SC-CO2 is a nonpolar solvent. Therefore, nonpolar drugs with high molecular weight are usually better dissolved in SC-CO2. On the other hand, polar drugs or drugs with polar groups may have lower solubility in SC-CO2. The type of bonds and molecular structure can also have a great effect on solubility. For example, drugs with strong hydrogen bonds may not dissolve in SC-CO287. In general, although molecular weight is one of the factors affecting solubility, it should be noted that other factors such as chemical structure, presence of functional groups, pressure and temperature also play an important role in estimating drug solubility in SC-CO2103.
The melting point can indicate the type of intermolecular bonds and the chemical structure of the drugs. Drugs with complex structures and strong bonds usually have higher melting points and may have lower solubility in SC-CO228,104. On the other hand, if the drug has functional groups that can interact with SC-CO2, it may have more solubility in SC-CO2, even if its melting point is high. Therefore, the solubility of a drug in SC-CO2 is strongly influenced by the type of interactions between drug molecules and SC-CO2103. Also, drugs with lower melting points usually have higher solubility in SC-CO₂. This is because, as the temperature decreases, the drugs can easily turn into a gas state and thus dissolve in SC-CO₂47.
Comparison the selected AIM with semi-empirical models
To compare the accuracy and ability of estimating SDs solubility in the SC-CO2 by the ANFIS model and previously reported models, the Flutamide SD was selected as a case study. As Table 7, the statistical parameters including R2, MAE, RMSE and AARD% showing the ANFIS model has more satisfactory results with higher accuracy than the other semi-empirical models.
Conclusion
The solubility estimation in SCF is an important step in the development of micro- and nanoscale particle production processes, as well as the extraction and purification of drugs. Alternatively, the time-consuming and costly access to solubility equilibrium data and the sensitivity of some drugs to heat, upsurge the necessity to model the solubility of drugs in SC-CO2. In this research, the solubility of SDs in SC-CO2 was modeled in a wide range of temperature and pressure (308–348.2 K and 80–400 bar) using AIMs based on GEP and ANFIS. The independent variables were T, P, MWSDs, and MPSDs. The collection of data for SDs in different operational conditions contains 1816 datasets, 80% of them were randomly selected for training, and the rest of them were for validation and test. The AIM output was selected through a multi-objective strategy that resulted in lower AARD% based on the simplest model having the highest fitness. The ANFIS model outperformed the GEP model in terms of accurate estimation, with statistical parameters such as R2, RMSE, MAE, and AARD% obtained in training and validation data equivalent to 0.991, 0.260, 0.167 and 13.890% and 0.990, 0.256, 0.157 and 15.273%, in that order. The RMSE, MAE and AARD% values not only are low, but they are very close together as much as possible, indicating the selected model has high precision in estimating the solubility. The sensitivity analysis of the optimized GEP model concerning the input variables was conducted. The results revealed that MWSDs, P, MPSDs, and T had the most influence in determining the solubility of SDs in SC-CO2, in that order. Increasing MWSDs as a consequence of increasing the number of carbon atoms leads to moving SDs towards nonpolarity. Hence, given the nonpolarity nature of SC-CO2, the increase of MWSDs enhances SDs solubility. Furthermore, the results showed that the positive effect of increasing temperature is dominant in such a way as to result in increasing the vapor pressure of SDs and consequently increasing the solubility in SC-CO2. Moreover, operating pressure significantly influences SDs solubility in SC-CO2, considering SC-CO2 density and solute vapor pressure. A cross-over region exists for drug solubility when the two determinants are equivalent. Other factors like chemical structure, functional group presence, and MPSDs also can play a significant role. Lower MPSDs exhibiting higher solubility due to gas-state dissolution. Eventually, in order to estimate the nonlinear relation between the input and output variables of the current research, the AIMs developed by ANFIS provides satisfactory results. Comparison the performance of the ANFIS model with the other semi-empirical models showed that the current model in addition to providing generalizability for various SDs by using MWSDs and MPSDs as the input model variables indicates more satisfactory results with higher accuracy.
Data availability
The datasets used during the current study available from the corresponding author (F. Bashipour) on reasonable request.
Abbreviations
- AARD :
-
Average absolute relative deviation
- AIMs:
-
Artificial intelligence models
- ANFIS:
-
Adaptive neuro-fuzzy inference system
- ANN:
-
Artificial neural network
- ARD:
-
Average relative deviation
- BPANN:
-
Backpropagation artificial neural network
- EoSs:
-
Equations of state
- ET:
-
Expression tree
- Exp:
-
Exponential
- FCM:
-
Fuzzy c-mean
- FFNN:
-
Feed forward neural network
- FIS:
-
Fuzzy inference system
- GEP:
-
Gene expression programming
- Inv:
-
Inverse
- IS transpozition:
-
Insertion sequence transpozition
- MAE:
-
Mean absolute error
- MFs:
-
Membership functions
- MPSD :
-
Solid Drug Melting Point
- MSE:
-
Mean square error
- MWSDs :
-
Solid Drugs Molecular Weight
- OBJ:
-
Objective
- PR-VdW:
-
Peng-Robinson- van der waals
- RIS Transposition:
-
Root insertion sequence transpozition
- RMSE:
-
Root mean square error
- SC-CO2 :
-
Supercritical carbon dioxide
- SCF:
-
Supercritical fluid
- SDs:
-
Solid drugs
- Tanh:
-
Hyperbolic tangent
- VdW:
-
Van der waals
References
Alwi, R. S. & Garlapati, C. New correlations for the solubility of anticancer drugs in supercritical carbon dioxide. Chem. Pap. 76, 1385–1399 (2022).
Li, M. J., Zhu, H. H., Guo, J. Q., Wang, K. & Tao, W. Q. The development technology and applications of supercritical CO2 power cycle in nuclear energy, solar energy and other energy industries. Appl. Therm. Eng. 126, 255–275 (2017).
Razmimanesh, F., Sodeifian, G. & Sajadian, S. A. An investigation into Sunitinib malate nanoparticle production by US- RESOLV method: Effect of type of polymer on dissolution rate and particle size distribution. J. Supercrit Fluids. 170, 105163 (2021).
Wang, W. et al. Supercritical carbon dioxide applications in food processing. Food Eng. Rev. 13, 570–591 (2021).
Sodeifian, G. & Sajadian, S. A. Saadati Ardestani, N. Experimental optimization and mathematical modeling of the supercritical fluid extraction of essential oil from Eryngium billardieri: Application of simulated annealing (SA) algorithm. J. Supercrit Fluids 127, 146–157 (2017).
Sodeifian, G., Ardestani, N. S., Sajadian, S. A. & Moghadamian, K. Properties of Portulaca oleracea seed oil via supercritical fluid extraction: Experimental and optimization. J. Supercrit Fluids 135, 34–44 (2018).
Sodeifian, G., Usefi, M. M. B. & Solubility extraction, and nanoparticles production in supercritical carbon dioxide: A mini-review. ChemBioEng Rev. 10, 133–166 (2023).
Zhu, H., Zhu, L., Sun, Z. & Khan, A. Machine learning based simulation of an anti-cancer drug (busulfan) solubility in supercritical carbon dioxide: ANFIS model and experimental validation. J. Mol. Liq. 338, 116731 (2021).
Ardestani, N. S., Majd, N. Y. & Amani, M. Experimental measurement and thermodynamic modeling of capecitabine (an Anticancer Drug) solubility in supercritical carbon dioxide in a ternary system: Effect of different cosolvents. J. Chem. Eng. Data. 65, 4762–4779 (2020).
Fathi, M., Sodeifian, G. & Sajadian, S. A. Experimental study of ketoconazole impregnation into polyvinyl pyrrolidone and hydroxyl propyl methyl cellulose using supercritical carbon dioxide: Process optimization. J. Supercrit Fluids. 188, 105674 (2022).
Sodeifian, G., Sajadian, S. A. & Honarvar, B. Mathematical modelling for extraction of oil from Dracocephalum Kotschyi seeds in supercritical carbon dioxide. Nat. Prod. Res. 32, 795–803 (2018).
Lee, H. W. et al. Comparative pharmacokinetic profiles of a novel low-dose micronized formulation of raloxifene 45 mg (AD-101) and the conventional raloxifene 60 mg in healthy subjects. Clin. Pharmacol. Drug Dev. 12, 1204–1210 (2023).
Wang, B. C. & Su, C. S. Solid solubility measurement of ipriflavone in supercritical carbon dioxide and microparticle production through the rapid expansion of supercritical solutions process. J. CO2 UTIL. 37, 285–294 (2020).
Tabernero, A., del Valle, M., Galan, M. A. & E.M. & An empirical analysis of the solubility of pharmaceuticals in supercritical carbon dioxide using sublimation enthalpies. Ind. Eng. Chem. Res. 52, 18447–18457 (2013).
Valderrama, J. O. & Zavaleta, J. Generalized binary interaction parameters in the Wong–Sandler mixing rules for mixtures containing n-alkanols and carbon dioxide. Fluid Ph Equilib. 234, 136–143 (2005).
Huang, C. Y., Lee, L. S. & Su, C. S. Correlation of solid solubilities of pharmaceutical compounds in supercritical carbon dioxide with solution model approach. J. Taiwan. Inst. Chem. Eng. 44, 349–358 (2013).
Sodeifian, G., Razmimanesh, F. & Sajadian, S. A. Solubility measurement of a chemotherapeutic agent (Imatinib mesylate) in supercritical carbon dioxide: Assessment of new empirical model. J. Supercrit Fluids. 146, 89–99 (2019).
Housaindokht, M. R. & Bozorgmehr, M. Calculation of solubility of methimazole, phenazopyridine and propranolol in supercritical carbon dioxide. J. Supercrit Fluids 43, 390–397 (2008).
Huang, Z., Chiew, Y. C., Lu, W. D. & Kawi, S. Solubility of aspirin in supercritical carbon dioxide/alcohol mixtures. Fluid Ph Equilib. 237, 9–15 (2005).
Jeon, P. R. & Lee, C. H. Artificial neural network modelling for solubility of carbon dioxide in various aqueous solutions from pure water to brine. J. CO2 UTIL. 47, 101500 (2021).
Yang, G., Li, Z., Shao, Q. & Feng, N. Measurement and correlation study of silymarin solubility in supercritical carbon dioxide with and without a cosolvent using semi-empirical models and back-propagation artificial neural networks. Asian J. Pharm. 12, 456–463 (2017).
Mehdizadeh, B. & Movagharnejad, K. A comparison between neural network method and semi empirical equations to predict the solubility of different compounds in supercritical carbon dioxide. Fluid Ph Equilib. 303, 40–44 (2011).
Dadkhah, M. R. et al. Prediction of solubility of solid compounds in supercritical CO2 using a connectionist smart technique. J. Supercrit Fluids. 120, 181–190 (2017).
Pishnamazi, M. et al. Measuring solubility of a chemotherapy-anti cancer drug (busulfan) in supercritical carbon dioxide. J. Mol. Liq. 317, 113954 (2020).
Garlapati, C. & Madras, G. New empirical expressions to correlate solubilities of solids in supercritical carbon dioxide. Thermochim Acta 500, 123–127 (2010).
Chrastil, J. Solubility of solids and liquids in supercritical gases. J. Phys. Chem. 86, 3016–3021 (1982).
Méndez-Santiago, J. & Teja, A. S. The solubility of solids in supercritical fluids. Fluid Ph Equilib. 158–160, 501–510 (1999).
Rezaei, T. et al. A universal methodology for reliable predicting the non-steroidal anti-inflammatory drug solubility in supercritical carbon dioxide. Sci. Rep. 12, 1043 (2022).
Amani, M. Saadati Ardestani, N. Investigation of the solubility of anticancer drugs in the supercritical solvent for development of innovative drug delivery systems; artificial intelligence paradigms (MLP-ANN) and thermodynamic correlations. J. Mol. Liq. 394, 123701 (2024).
Nateghi, H., Sodeifian, G. & Razmimanesh, F. Mohebbi Najm Abad, J. A machine learning approach for thermodynamic modeling of the statically measured solubility of nilotinib hydrochloride monohydrate (anti-cancer drug) in supercritical CO2. Sci. Rep. 13, 12906 (2023).
Zhong, J., Feng, L. & Ong, Y. Gene expression programming: A survey [Review article]. IEEE Comput. Intell. Mag. 12, 54–72 (2017).
Yamini, Y. et al. Solubility of capecitabine and docetaxel in supercritical carbon dioxide: Data and the best correlation. Thermochim Acta 549, 95–101 (2012).
Sodeifian, G. & Sajadian, S. A. Solubility measurement and preparation of nanoparticles of an anticancer drug (letrozole) using rapid expansion of supercritical solutions with solid cosolvent (RESS-SC). J. Supercrit Fluids. 133, 239–252 (2018).
Hojjati, M., Vatanara, A., Yamini, Y., Moradi, M. & Najafabadi, A. R. Supercritical CO2 and highly selective aromatase inhibitors: Experimental solubility and empirical data correlation. J. Supercrit Fluids 50, 203–209 (2009).
Sodeifian, G., Razmimanesh, F., Sajadian, S. A. & Hazaveie, S. M. Experimental data and thermodynamic modeling of solubility of Sorafenib tosylate, as an anti-cancer drug, in supercritical carbon dioxide: Evaluation of Wong-Sandler mixing rule. J. Chem. Thermodyn. 142, 105998 (2020).
Sodeifian, G., Razmimanesh, F., Saadati Ardestani, N. & Sajadian, S. A. Experimental data and thermodynamic modeling of solubility of azathioprine, as an immunosuppressive and anti-cancer drug, in supercritical carbon dioxide. J. Mol. Liq. 299, 112179 (2020).
Sodeifian, G., Razmimanesh, F. & Sajadian, S. A. Prediction of solubility of sunitinib malate (an anti-cancer drug) in supercritical carbon dioxide (SC–CO2): Experimental correlations and thermodynamic modeling. J. Mol. Liq. 297, 111740 (2020).
Vandana, V. & Teja, A. S. The solubility of paclitaxel in supercritical CO2 and N2O. Fluid Ph Equilib. 135, 83–87 (1997).
Yamini, Y. et al. Solubilities of flutamide, dutasteride, and finasteride as antiandrogenic agents, in supercritical carbon dioxide: Measurement and correlation. J. Chem. Eng. Data 55, 1056–1059 (2010).
Yamini, Y., Tayyebi, M., Moradi, M. & Vatanara, A. Solubility of megestrol acetate and levonorgestrel in supercritical carbon dioxide. Thermochim Acta. 569, 48–54 (2013).
Pishnamazi, M. et al. Thermodynamic modelling and experimental validation of pharmaceutical solubility in supercritical solvent. J. Mol. Liq. 319, 114120 (2020).
Sodeifian, G., Sajadian, S. A. & Ardestani, N. S. Determination of solubility of aprepitant (an antiemetic drug for chemotherapy) in supercritical carbon dioxide: Empirical and thermodynamic models. J. Supercrit Fluids. 128, 102–111 (2017).
Zhan, S. et al. Solubility and partition coefficients of 5-Fluorouracil in ScCO2 and ScCO2/Poly (l-lactic acid). J. Chem. Eng. Data. 59, 1158–1164 (2014).
Hazaveie, S. M., Sodeifian, G. & Sajadian, S. A. Measurement and thermodynamic modeling of solubility of Tamsulosin drug (anti cancer and anti-prostatic tumor activity) in supercritical carbon dioxide. J. Supercrit Fluids. 163, 104875 (2020).
Pishnamazi, M. et al. Experimental and thermodynamic modeling decitabine anti cancer drug solubility in supercritical carbon dioxide. Sci. Rep. 11, 1–8 (2021).
Zabihi, S. et al. Thermodynamic study on solubility of brain tumor drug in supercritical solvent: Temozolomide case study. J. Mol. Liq. 321, 114926 (2021).
Sodeifian, G., Alwi, R. S., Razmimanesh, F. & Roshanghias, A. Solubility of pazopanib hydrochloride (PZH, anticancer drug) in supercritical CO2: Experimental and thermodynamic modeling. J. Supercrit Fluids 190, 105759 (2022).
Sodeifian, G., Bagheri, H., Bargestan, M. & Ardestani, N. S. Determination of Gefitinib hydrochloride anti-cancer drug solubility in supercritical CO2: Evaluation of sPC-SAFT EoS and semi-empirical models. J. Taiwan. Inst. Chem. Eng. 161, 105569 (2024).
Sodeifian, G., Alwi, R. S., Arbab Nooshabadi, M., Razmimanesh, F. & Roshanghias, A. Solubility measurement of Triamcinolone acetonide (steroid medication) in supercritical CO2: Experimental and thermodynamic modeling. J. Supercrit Fluids 204, 106119 (2024).
Sodeifian, G., Behvand Usefi, M. M., Razmimanesh, F. & Roshanghias, A. Determination of the solubility of rivaroxaban (anticoagulant drug, for the treatment and prevention of blood clotting) in supercritical carbon dioxide: Experimental data and correlations. Arab. J. Chem. 16, 104421 (2023).
Sodeifian, G., Nateghi, H. & Razmimanesh, F. Measurement and modeling of dapagliflozin propanediol monohydrate (an anti-diabetes medicine) solubility in supercritical CO2: Evaluation of new model. J. CO2 UTIL. 80, 102687 (2024).
Sodeifian, G., Hazaveie, S. M. & Sodeifian, F. Determination of galantamine solubility (an anti-alzheimer drug) in supercritical carbon dioxide (CO2): Experimental correlation and thermodynamic modeling. J. Mol. Liq. 330, 115695 (2021).
Sodeifian, G., Derakhsheshpour, R. & Sajadian, S. A. Experimental study and thermodynamic modeling of Esomeprazole (proton-pump inhibitor drug for stomach acid reduction) solubility in supercritical carbon dioxide. J. Supercrit Fluids. 154, 104606 (2019).
Sodeifian, G., Bagheri, H., Ashjari, M. & Noorian-Bidgoli, M. Solubility measurement of ceftriaxone sodium in SC-CO2 and thermodynamic modeling using PR-KM EoS and vdW mixing rules with semi-empirical models. Case Stud. Therm. Eng. 61, 105074 (2024).
Abadian, M., Sodeifian, G., Razmimanesh, F. & Zarei Mahmoudabadi, S. Experimental measurement and thermodynamic modeling of solubility of Riluzole drug (neuroprotective agent) in supercritical carbon dioxide. Fluid Ph Equilib. 567, 113711 (2023).
Sodeifian, G., Hsieh, C. M., Derakhsheshpour, R., Chen, Y. M. & Razmimanesh, F. Measurement and modeling of metoclopramide hydrochloride (anti-emetic drug) solubility in supercritical carbon dioxide. Arab. J. Chem. 15, 103876 (2022).
Sodeifian, G., Nasri, L., Razmimanesh, F. & Abadian, M. CO2 utilization for determining solubility of teriflunomide (immunomodulatory agent) in supercritical carbon dioxide: Experimental investigation and thermodynamic modeling. J. CO2 UTIL. 58, 101931 (2022).
Sodeifian, G., Hazaveie, S. M. & Sajadian, S. A. Saadati Ardestani, N. Determination of the solubility of the repaglinide drug in supercritical carbon dioxide: Experimental data and thermodynamic modeling. J. Chem. Eng. Data. 64, 5338–5348 (2019).
Sodeifian, G., Hazaveie, S. M., Sajadian, S. A. & Razmimanesh, F. Experimental investigation and modeling of the solubility of oxcarbazepine (an anticonvulsant agent) in supercritical carbon dioxide. Fluid Ph Equilib. 493, 160–173 (2019).
Sodeifian, G., Saadati Ardestani, N., Sajadian, S. A., Golmohammadi, M. R. & Fazlali, A. Prediction of solubility of sodium valproate in supercritical carbon dioxide: Experimental study and thermodynamic modeling. J. Chem. Eng. Data. 65, 1747–1760 (2020).
Sodeifian, G., Surya Alwi, R., Razmimanesh, F. & Abadian, M. Solubility of Dasatinib monohydrate (anticancer drug) in supercritical CO2: Experimental and thermodynamic modeling. J. Mol. Liq. 346, 117899 (2022).
Sodeifian, G., Garlapati, C., Razmimanesh, F. & Sodeifian, F. The solubility of Sulfabenzamide (an antibacterial drug) in supercritical carbon dioxide: Evaluation of a new thermodynamic model. J. Mol. Liq. 335, 116446 (2021).
Sodeifian, G., Razmimanesh, F., Sajadian, S. A. & Soltani Panah, H. Solubility measurement of an antihistamine drug (loratadine) in supercritical carbon dioxide: Assessment of qCPA and PCP-SAFT equations of state. Fluid Ph Equilib. 472, 147–159 (2018).
Sodeifian, G., Garlapati, C., Razmimanesh, F. & Nateghi, H. Solubility measurement and thermodynamic modeling of pantoprazole sodium sesquihydrate in supercritical carbon dioxide. Sci. Rep. 12, 7758 (2022).
Sodeifian, G., Hsieh, C. M., Tabibzadeh, A. & Wang, H. C. Arbab Nooshabadi, M. Solubility of palbociclib in supercritical carbon dioxide from experimental measurement and Peng–Robinson equation of state. Sci. Rep. 13, 2172 (2023).
Sodeifian, G., Garlapati, C., Arbab Nooshabadi, M., Razmimanesh, F. & Roshanghias, A. Studies on solubility measurement of codeine phosphate (pain reliever drug) in supercritical carbon dioxide and modeling. Sci. Rep. 13, 21020 (2023).
Sodeifian, G. & Sajadian, S. A. Experimental measurement of solubilities of sertraline hydrochloride in supercriticalcarbon dioxide with/without menthol: Data correlation. J. Supercrit Fluids. 149, 79–87 (2019).
Sodeifian, G., Garlapati, C., Hazaveie, S. M. & Sodeifian, F. Solubility of 2,4,7-Triamino-6-phenylpteridine (Triamterene, Diuretic Drug) in supercritical carbon dioxide: Experimental data and modeling. J. Chem. Eng. Data. 65, 4406–4416 (2020).
Sodeifian, G., Nasri, L., Razmimanesh, F. & Arbab Nooshabadi, M. Solubility of ibrutinib in supercritical carbon dioxide (Sc-CO2): Data correlation and thermodynamic analysis. J. Chem. Thermodyn. 182, 107050 (2023).
Sodeifian, G., Sajadian, S. A. & Razmimanesh, F. Solubility of an antiarrhythmic drug (amiodarone hydrochloride) in supercritical carbon dioxide: Experimental and modeling. Fluid Ph Equilib. 450, 149–159 (2017).
Sodeifian, G., Sajadian, S. A. & Derakhsheshpour, R. Experimental measurement and thermodynamic modeling of Lansoprazole solubility in supercritical carbon dioxide: Application of SAFT-VR EoS. Fluid Ph Equilib. 507, 112422 (2020).
Sodeifian, G., Garlapati, C., Razmimanesh, F. & Ghanaat-Ghamsari, M. Measurement and modeling of clemastine fumarate (antihistamine drug) solubility in supercritical carbon dioxide. Sci. Rep. 11, 24344 (2021).
Sodeifian, G., Garlapati, C., Razmimanesh, F. & Nateghi, H. Experimental solubility and thermodynamic modeling of empagliflozin in supercritical carbon dioxide. Sci. Rep. 12, 9008 (2022).
Sodeifian, G., Garlapati, C., Arbab Nooshabadi, M., Razmimanesh, F. & Tabibzadeh, A. Solubility measurement and modeling of hydroxychloroquine sulfate (antimalarial medication) in supercritical carbon dioxide. Sci. Rep. 13, 8112 (2023).
Sodeifian, G. et al. Determination of morphine sulfate anti-pain drug solubility in supercritical CO2 with machine learning method. Sci. Rep. 14, 22370 (2024).
Sodeifian, G., Nateghi, H. & Razmimanesh, F. Mohebbi Najm Abad, J. Thermodynamic modeling and solubility assessment of oxycodone hydrochloride in supercritical CO2: Semi-empirical, EoSs models and machine learning algorithms. Case Stud. Therm. Eng. 55, 104146 (2024).
Sodeifian, G., Bagheri, H., Arbab Nooshabadi, M., Razmimanesh, F. & Roshanghias, A. Experimental solubility of fexofenadine hydrochloride (antihistamine) drug in SC-CO2: Evaluation of cubic equations of state. J. Supercrit Fluids 200, 106000 (2023).
Sodeifian, G., Alwi, R. S. & Razmimanesh, F. Solubility of Pholcodine (antitussive drug) in supercritical carbon dioxide: Experimental data and thermodynamic modeling. Fluid Ph Equilib. 556, 113396 (2022).
Sodeifian, G., Bagheri, H., Razmimanesh, F. & Bargestan, M. Supercritical CO2 utilization for solubility measurement of tramadol hydrochloride drug: Assessment of cubic and non-cubic EoSs. J. Supercrit Fluids. 206, 106185 (2024).
Sodeifian, G., Arbab Nooshabadi, M., Razmimanesh, F. & Tabibzadeh, A. Solubility of buprenorphine hydrochloride in supercritical carbon dioxide: Study on experimental measuring and thermodynamic modeling. Arab. J. Chem. 16, 105196 (2023).
Sodeifian, G. et al. Determination of Regorafenib monohydrate (colorectal anticancer drug) solubility in supercritical CO2: Experimental and thermodynamic modeling. Heliyon 10, e29049 (2024).
Sodeifian, G., Saadati Ardestani, N., Razmimanesh, F. & Sajadian, S. A. Experimental and thermodynamic analyses of supercritical CO2-Solubility of minoxidil as an antihypertensive drug. Fluid Ph Equilib. 522, 112745 (2020).
Sodeifian, G., Nasri, L., Razmimanesh, F. & Abadian, M. Measuring and modeling the solubility of an antihypertensive drug (losartan potassium, Cozaar) in supercritical carbon dioxide. J. Mol. Liq. 331, 115745 (2021).
Sodeifian, G., Garlapati, C., Razmimanesh, F. & Sodeifian, F. Solubility of amlodipine besylate (calcium channel blocker drug) in supercritical carbon dioxide: Measurement and correlations. J. Chem. Eng. Data. 66, 1119–1131 (2021).
Sodeifian, G., Alwi, R. S., Razmimanesh, F. & Tamura, K. Solubility of Quetiapine hemifumarate (antipsychotic drug) in supercritical carbon dioxide: Experimental, modeling and Hansen solubility parameter application. Fluid Ph Equilib. 537, 113003 (2021).
Sodeifian, G., Saadati Ardestani, N., Sajadian, S. A. & Panah, H. S. Measurement, correlation and thermodynamic modeling of the solubility of Ketotifen fumarate (KTF) in supercritical carbon dioxide: Evaluation of PCP-SAFT equation of state. Fluid Ph Equilib. 458, 102–114 (2018).
Sodeifian, G., Sajadian, S. A., Razmimanesh, F. & Hazaveie, S. M. Solubility of Ketoconazole (antifungal drug) in SC-CO2 for binary and ternary systems: Measurements and empirical correlations. Sci. Rep. 11, 7546 (2021).
Sodeifian, G., Garlapati, C. & Roshanghias, A. Experimental solubility and modeling of Crizotinib (anti-cancer medication) in supercritical carbon dioxide. Sci. Rep. 12, 17494 (2022).
Sodeifian, G., Surya Alwi, R., Razmimanesh, F. & Sodeifian, F. Solubility of prazosin hydrochloride (alpha blocker antihypertensive drug) in supercritical CO2: Experimental and thermodynamic modelling. J. Mol. Liq. 362, 119689 (2022).
Ferreira, C. Gene expression programming: A new adaptive algorithm for solving problems. arXiv preprint cs/0102027 (2001).
Akanbi, O., Sadegh Amiri, I. & Fazeldehkordi, E. A machine learning approach to phishing detection and defense. (2014).
Hosseini, S. A. & Maleki Toulabi, H. Presenting a novel approach for predicting the compressive strength of structural lightweight concrete based on pattern recognition and gene expression programming. Arab. J. Sci. Eng. 48, 14169–14181 (2023).
Shanmugapriya, M., Sundareswaran, R., Kumar, P. S. & Elayarani, M. An ANFIS approach for predicting MHD radiative hybrid nanofluid flow attributes with activation energy effect. Arab. J. Sci. Eng. 48, 16373–16387 (2023).
Nafees, A. et al. Predictive modeling of Mechanical properties of silica fume-based green concrete using Artificial Intelligence approaches: MLPNN, ANFIS, and GEP. Mater. (Basel Switzerland) 14 (2021).
Gandomi, A. H. & Alavi, A. H. Expression programming techniques for formulation of structural engineering systems, Vol. 18 chapter,. (2013).
Ferreira, C. Gene Expression Programming: Mathematical Modeling by an Artificial Intelligence Vol. 21 (Springer, 2006).
Rashidi, S. & Ranjitkar, P. Bus dwell time modeling using gene expression programming. Aided Civ. Infrastruct. Eng. 30, 478–489 (2015).
Bagheri, H. & Shariati, A. Prediction of the Solubility of Benzoic Acid in Supercritical CO2 Using the PC-SAFT EoS. Sat 1, P1 (2014).
Baghban, A., Sasanipour, J. & Zhang, Z. A new chemical structure-based model to estimate solid compound solubility in supercritical CO2. J. CO2 UTIL. 26, 262–270 (2018).
Fulton, J. L., Yee, G. G. & Smith, R. D. Hydrogen bonding of methyl alcohol-d in supercritical carbon dioxide and supercritical ethane solutions. J. Am. Chem. Soc. 113, 8327–8334 (1991).
Shi, Q., Jing, L. & Qiao, W. Solubility of n-alkanes in supercritical CO2 at diverse temperature and pressure. J. CO2 UTIL. 9, 29–38 (2015).
Nguyen, H. C. et al. Computational prediction of drug solubility in supercritical carbon dioxide: Thermodynamic and artificial intelligence modeling. J. Mol. Liq. 354, 118888 (2022).
Chang, F., Jin, J., Zhang, N., Wang, G. & Yang, H. J. The effect of the end group, molecular weight and size on the solubility of compounds in supercritical carbon dioxide. Fluid Ph Equilib. 36–42 (2012).
Su, C. S. & Chen, Y. P. Measurement and correlation for the solid solubility of non-steroidal anti-inflammatory drugs (NSAIDs) in supercritical carbon dioxide. J. Supercrit Fluids 43, 438–446 (2008).
Author information
Authors and Affiliations
Contributions
Zahra Bahrami: Data curation management, Developing GEP modeling, Managed the data curation process, Drafted the initial manuscript, Reviewed and edited the manuscriptFatemeh Bashipour: Conceptualization ideas, Developing GEP and ANFIS modeling, Reviewed and edited the manuscript, SupervisionAlireza Baghban: Development methodology, Reviewed and edited the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Bahrami, Z., Bashipour, F. & Baghban, A. Application of machine learning approach to estimate the solubility of some solid drugs in supercritical CO2. Sci Rep 15, 5192 (2025). https://doi.org/10.1038/s41598-025-89858-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-89858-5
