
Abstract
In the field of deep learning-based object detection, RGB-T salient object detection (SOD) networks show significant potential for cross-modal information fusion. However, existing methods still face considerable challenges in complex scenes. Specifically, current cross-modal feature fusion approaches fail to exploit the complementary information between modalities fully, resulting in limited robustness when handling diverse inputs. Furthermore, inadequate adaptation to multi-scale features hinders accurately recognizing salient objects at different scales. Although some feature decoding strategies attempt to mitigate noise interference, they often struggle in high-noise environments and lack flexible feature weighting, further restricting fusion capabilities. To address these limitations, this paper proposes a novel salient object detection network, TCAINet. The network integrates a Channel Attention (CA) mechanism, an enhanced cross-modal fusion module (CAF), and an adaptive decoder (AAD) to improve both the depth and breadth of feature fusion. Additionally, diverse noise addition and augmentation methods are applied during data preprocessing to boost the model’s robustness and adaptability. Specifically, the CA module enhances the model’s feature selection ability, while the CAF and AAD modules optimize the integration and processing of multimodal information. Experimental results demonstrate that TCAINet outperforms existing methods across multiple evaluation metrics, proving its effectiveness and practicality in complex scenes. Notably, the proposed model achieves improvements of 0.653%, 1.384%, 1.019%, and 5.83% in Sm, Em, Fm, and MAE metrics, respectively, confirming its efficacy in enhancing detection accuracy and optimizing feature fusion. The code and results can be found at the following link:huyunfei0219/TCAINet.
Similar content being viewed by others

Introduction
Salient Object Detection (SOD) is a pivotal task in computer vision, aimed at identifying and locating visually significant objects in images or videos. As an essential preprocessing tool, SOD is extensively applied across various computer vision domains such as object detection1, semantic segmentation2, image retrieval3, and object tracking4. These applications significantly enhance system performance and efficiency, influencing numerous fields. For instance, in autonomous driving systems5, SOD aids in accurately detecting pedestrians and obstacles, thereby enhancing road safety. In medical image analysis, SOD assists physicians in quickly identifying lesions, improving diagnostic accuracy and efficiency6.
In the related field of remote sensing change detection, existing techniques often struggle to accurately recognize building edges and detailed textures, resulting in ambiguous boundaries between the changed and unchanged regions7.This limitation highlights a common challenge in multi-modal visual tasks: how to effectively fuse complementary information from different modalities while preserving fine-grained features, which is also a crucial issue in RGB-T SOD. Such challenges call for innovative methods that can better capture the cross-modal correlations and enhance the discriminative power of fused features.
Despite its wide-ranging applications, SOD faces considerable challenges, particularly in complex environments and multimodal data integration. Traditional single-modality approaches often struggle to fully capture the intricate structures of salient objects, especially in contexts like underwater vision or remote sensing, where objects are often small or obscured by environmental factors.Recent studies in related multimodal vision tasks reveal similar fundamental challenges—for instance, infrared–visible object detection requires explicit modeling of cross-modal frequency characteristics, as demonstrated by FD2-Net8 which decomposes high-frequency textures and low-frequency thermal patterns through discrete cosine transform In underwater saliency detection (USOD), for example, capturing long-range contextual features remains a significant challenge, while remote sensing object detection contends with issues such as small object detection and poor visibility under low-light conditions. These difficulties are further compounded when relying solely on a single modality, as the feature richness needed for such complex tasks is often insufficient.
Recent advancements in multimodal SOD have sought to address these challenges by exploiting complementary information from different modalities to improve performance. Models such as EGANet9, CPNet10, and IFRNet11have incorporated innovative strategies like edge enhancement and cross-modal attention to improve feature representation. However, while these models have shown promise, they often suffer from high computational costs, making them unsuitable for deployment in resource-constrained environments.Notably, similar challenges exist in related computer vision domains—recent work on SAR object detection proposes SFS-Conv12, which enhances feature diversity through spatial-frequency decoupling while reducing computational overhead, demonstrating the feasibility of balancing efficiency and accuracy. Additionally, lightweight models like MobileSal, AirSOD, and LSNet13,14,15, which prioritize inference speed, tend to compromise accuracy, thus presenting a dilemma between speed and detection performance.
This work proposes a novel solution to these challenges by introducing TCAINet, a model designed to advance multimodal saliency detection through improved feature selection and fusion. By incorporating a Channel Attention (CA) mechanism and innovative feature fusion strategies, TCAINet enhances the model’s ability to handle complex scenarios, ensuring more precise multi-scale fusion and robust performance in noisy or cluttered environments. The core contributions of this work lie in two key innovations:1.Channel Attention (CA) Mechanism: The introduction of the CA mechanism significantly improves the model’s ability to focus on important features, thereby enhancing the representation of critical objects and improving robustness against background interference and noise.2.Cross-modal Fusion (CAF) and Interactive Feature Decoder (AAD) Modules: These modules address the challenges of integrating information from different modalities. The CAF module effectively enhances the fusion of complementary modal features, reducing information loss, while the AAD module refines multi-scale feature processing, allowing for better separation of salient objects from background clutter. These innovations ensure the model can detect objects at different scales with high accuracy.
Through extensive experiments, we demonstrate that TCAINet outperforms existing methods in terms of both accuracy and efficiency, offering a practical solution for SOD tasks in challenging multimodal environments.
Summary of Contributions:1)Innovative Data Preprocessing Strategy: This work introduces diverse noise-augmentation techniques, including salt-and-pepper noise and Poisson noise, along with advanced data augmentation strategies (e.g., MixUp and CutMix). These innovations significantly improve the robustness of the model, making it more adaptable to a variety of environmental conditions and enhancing overall detection performance.2)Proposed TCAINet Model: The TCAINet architecture is designed to overcome the limitations of current multimodal SOD methods. It integrates the Channel Attention (CA) mechanism to improve feature selection and multi-scale fusion, ensuring enhanced performance in complex scenarios. TCAINet represents a significant step forward in the evolution of multimodal saliency detection by addressing both feature extraction and fusion challenges effectively.3)Innovative Module Design: The model introduces two key modules: the Cross-modal Fusion (CAF) and Interactive Feature Decoder (AAD). The CAF module addresses the insufficient fusion of complementary modal information, while the AAD module enhances multi-scale feature handling, improving the model’s ability to detect salient objects at various scales and under different environmental conditions. Together, these modules strengthen the model’s capability to handle complex, noisy, and cluttered scenes, further improving detection performance.
Related work
In recent decades, significant progress has been made in the field of salient object detection, fueled by extensive research efforts. This section provides an overview of the key advancements in this area.
RGB salient object detection
Before the rise of deep learning, salient object detection primarily relied on traditional methods, which were often based on handcrafted low-level visual features, such as color, orientation, texture, edges, and contrast. Early research in saliency detection, such as that by Itti et al.16, proposed a method for generating saliency maps through multi-scale combinations. This approach utilizes a dynamic network to select and highlight salient regions, laying the foundation for subsequent advancements in saliency detection.
As research progressed, traditional saliency detection algorithms began to incorporate more sophisticated feature fusion mechanisms. For example, Wang et al.17introduced a graph-based flow ranking method that assigns weights to each modality, reflecting the relative importance of different modal features in saliency detection tasks. This method also enhances cross-modal fusion by employing consistency constraints between modalities. Similarly, Tang et al.18 applied the flow ranking algorithm to the RGB-T SOD task, achieving more robust multimodal saliency detection by imposing similar cross-modal consistency constraints.
Despite the achievements of these methods, their reliance on handcrafted features and prior assumptions limits their performance in complex scenes. With the advent of deep learning, researchers increasingly turned to deep neural network-based methods for saliency detection, enabling the automatic extraction of more complex features and patterns.
Multi-scale strategies have also played a crucial role in advancing saliency detection. For instance, CPD19 introduced receptive field blocks to capture multi-scale contextual information, while employing four-branch dilated convolutions to adapt to features at various scales. Liu et al.20 designed a feature aggregation module in PoolNet, utilizing pooling kernels of different sizes to extract multi-resolution features. Pang et al.21 developed an aggregation interaction module that captures multi-scale information more comprehensively by interacting with adjacent three-level features. However, despite these advancements, challenges remain in capturing high-level semantic relationships and fine-grained textures, which are particularly important in complex scenes.
In cross-modal saliency detection, superpixel segmentation methods have also played a significant role. For example, Gupta et al.22 proposed an improved SLIC algorithm, which replaces traditional Euclidean distance with Jeffrey divergence, enhancing the precision of superpixel segmentation. This improvement is crucial for strengthening the correlation between features of different modalities, especially when processing multimodal data, such as RGB and depth images. Building on this algorithm, the AWkS model introduced adaptive weighted K-means clustering (W-k-means) to optimize distance metrics, opening new avenues for applying superpixel algorithms in cross-modal saliency detection.
In remote sensing change detection, the Temporal-Spatial Multi-scale Graph Attention Network (TSMGA) addresses similar multi-scale challenges by modeling global contextual dependencies via graph attention mechanisms23. While effective for spatio-temporal data, such approaches require adaptation for RGB-T fusion, where the focus is on parallel modality interaction rather than temporal sequence analysis.
RGB-D salient object detection
In recent years, significant progress has been made in salient object detection (SOD) for multimodal images, with notable research achievements in RGB-D SOD24,25,26and RGB-T SOD27,28. These models incorporate depth maps or thermal images into SOD tasks, leveraging their complementary cues to address the challenges posed by complex scenes. Depth maps, being less sensitive to lighting and color variations, provide more reliable spatial structural details, making them highly valuable for SOD. As a result, researchers have increasingly explored the effectiveness of cross-modal saliency detection by directly integrating RGB features with depth features.
Li et al.29 introduced a cross-enhancement strategy that first utilizes RGB features to filter depth features, thereby enhancing the quality of the encoded depth features, followed by a refinement of the RGB features using pure depth information. This approach effectively combines RGB and depth information, promoting more efficient cross-modal feature fusion. Sun et al.30 proposed a cascade correction decoder designed to reduce discrepancies among features at different scales, suppress noise in low-level features, and employ a feedback mechanism to mitigate information loss during upsampling. These strategies collectively enhance the robustness of cross-modal feature fusion, leading to stronger feature representations and improved detection accuracy in complex scenes.
Additionally, Piao et al.31 modeled the relationship between depth cues and object scale using a residual structure. They designed a depth refinement block and employed an innovative iterative attention mechanism to uncover semantic correlations within fused features, iteratively refining local details to better utilize both RGB and depth information. This method highlights the critical role of cross-modal feature fusion in capturing complex scenes. Wang et al.32 proposed a novel strategy for enhancing the quality of unreliable depth images by estimating depth information from RGB images and integrating attention mechanisms with deformable convolutions. This combination enables the generation of saliency maps with sharper boundaries and more complete object representations.
These studies underscore the substantial potential of cross-modal feature fusion in saliency detection, offering new approaches to improve detection accuracy, particularly in complex and challenging scenes.
RGB-T salient object detection
RGB-T (Visible-Infrared) technology has become a crucial research direction for tackling saliency object detection (SOD) tasks in complex environments. With the widespread adoption of applications such as drones and autonomous driving, RGB-T technology is extensively used to enhance object detection accuracy and robustness under various environmental conditions. However, in practical applications, RGB-T technology still faces several challenges, such as effectively fusing cross-modal information, noise interference caused by environmental changes, target occlusion, and computational resource limitations.
In object detection tasks, the key challenge for RGB-T SOD methods lies in processing and fusing features from different modalities. In recent years, numerous studies have proposed cross-modal information fusion methods to improve object detection performance in complex backgrounds. For instance, CMPNet33 effectively suppresses noisy features by designing a cross-modal perception fusion module and a multi-scale feature aggregation module. These modules share features between different modalities, significantly enhancing robustness in complex scenarios. Moreover, the network employs spatial context-aware graph convolutional units to capture rich group structural information and integrates multi-scale features to improve the network’s ability to detect dense crowds. This approach demonstrates state-of-the-art performance on RGB-T datasets and provides an effective solution for cross-modal crowd counting.
Inspired by pansharpening techniques that exploit spectral-spatial complementarity, methods like the Convolutional Dictionary Iterative Model (CDME) separate common/unique features between multi-spectral and panchromatic images using adaptive expert modules34. This paradigm of feature separation and weighted fusion offers insights for RGB-T models, which must balance modality-specific characteristics (e.g., RGB textures vs. thermal contours) during integration.
On the other hand, RGB-T object tracking technology35 has also received widespread attention, particularly in addressing issues such as camera motion and target occlusion. With the rise of deep learning (DL)based cross-modal methods, several RGB-T-based object tracking techniques have been proposed. For example, some methods combine Jitter Factor and Kalman filters to detect camera motion and correct target positions, effectively addressing the challenges posed by dynamic backgrounds and target occlusion. These methods outperform non-DL-based tracking techniques across multiple RGB-T datasets and demonstrate faster processing speeds, achieving up to 25 FPS even on edge computing platforms. The successful application of these methods provides new insights for object detection and tracking in complex environments.
Additionally, RGB-Thermal Video Object Detection (RGBT VOD) \* MERGEFORMAT36 is a method that combines visible and thermal infrared video to detect and classify predefined targets. A key challenge in this field is effectively fusing multimodal information to enhance detection performance. Current multimodal fusion methods primarily adopt intermediate fusion strategies, but the fusion results are limited due to modality differences. To address this, PTMNet has proposed a novel hybrid fusion network that combines early fusion strategies with progressive interaction, as well as intermediate fusion strategies that account for temporal modality differences. This approach significantly enhances RGB-T VOD performance. Specifically, PTMNet treats each modality as the primary modality and fuses it early with other modalities to mitigate modality differences, thus facilitating intermediate fusion. Temporal modality differences are modeled through spatial offsets that capture temporal information, and feature erasure mechanisms encourage the network to focus on shared targets across both modalities. This hybrid fusion method achieves high detection accuracy even with just three input frames and significantly boosts inference speed. Experimental results show that PTMNet achieves state-of-the-art performance on the VT-VOD50 dataset and runs at over 70 FPS.
Lastly, transmission line detection (TLD)37, an important industrial application, has also benefited from the cross-modal fusion of RGB-T technology. For example, during transmission line fault diagnosis using drones, existing CNN methods often struggle with generalization due to background aggregation and weather variations. To address this, some studies have proposed RGB-T-based CNNs combined with knowledge distillation (KD) strategies. These studies have designed a high-performance teacher model (MAINet-T) and a compact student model (MAINet-S), improving transmission line detection accuracy and robustness through response and feature distillation strategies. Experimental results show that this method outperforms 15 existing methods on the VITLD dataset, significantly reduces the model’s parameter count, and improves floating-point operation efficiency, demonstrating strong practical potential.
In conclusion, RGB-T SOD technology has demonstrated strong adaptability and potential across various practical tasks. By continuously optimizing methods for cross-modal information fusion, feature aggregation, and multi-scale perception, RGB-T technology effectively addresses the challenges in object detection and achieves excellent performance in real-world applications. Nevertheless, further improvements in model computational efficiency and robustness are needed to meet the demands of diverse practical scenarios.
Similarly, the Deep Unfolding convolutional dictionary Network (DUCD) enhances cross-modal feature relationships via an observation model and frequency-domain transformers, demonstrating the value of explicit multi-modal interaction38. These advancements motivate the design of TCAINet’s modules, which aim to overcome fusion inefficiencies through attention mechanisms and adaptive decoding.
Proposed method
This section first introduces the main architecture of TCAINet. Additionally, the design details of key components, including the Channel Attention (CA) mechanism, Cross-Modal Feature Fusion (CAF) module, and Adaptive Attention Decoder (AAD) module, are discussed in detail.
Architecture overview
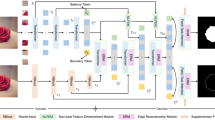
As shown in Fig. 1, the proposed TCAINet is an innovative cross-modal integration network based on Transformers, utilizing an encoder-decoder architecture. This model combines the Siamese Swin Transformer encoder, Channel Attention (CA) mechanism, Cross-Modal Feature Fusion (CAF) module, and Adaptive Attention Decoder (AAD) module, all aimed at enhancing feature extraction and fusion. During the encoding phase, the Siamese Swin Transformer encoder extracts multi-level feature representations, while the CA mechanism refines the feature selection process, enabling the model to focus more effectively on critical features in multi-modal data. In the decoding phase, the AAD module integrates and reconstructs the fused features to generate high-quality saliency maps. With this architecture, TCAINet excels in complex scenes, providing robust performance for saliency object detection.

The structure of the TCAINet.
The TCAINet model takes two inputs: the RGB image \(rgb\) and auxiliary modality features \(fss\) (e.g., depth images). First, both inputs are processed by the Siamese Swin Transformer encoder to extract multi-level feature representations. These features are then enhanced using 3 × 3 convolutional layers. The enhanced features are fed into the CA module, which generates high-level enhanced features \(E_{rbg}\) and \(E_{fs}\). These features are then fused through the CAF module (Cross-modal Attention Fusion), producing the fused feature representations \(f5\). This fusion process occurs sequentially at each feature level, progressively integrating the RGB features \(E_{rgb}\) and the auxiliary modality features \(E_{fs}\).
At each level, the RGB and auxiliary modality features are further processed by the AAD module to generate refined fused features \(f\). This layer-wise fusion structure enhances the model’s adaptability and precision in feature selection and cross-modal feature fusion.
Once feature fusion is complete, the TCAINet model uses 1 × 1 convolutions and upsampling modules to progressively transform the fused features into saliency prediction maps at multiple scales. Specifically, the fused features \(f5\), \(f4\) and \(f3\), etc.are processed through convolution and upsampling operations to generate saliency feature maps at different scales \(Y5\), \(Y4\) and \(Y3\), etc.). Finally, the lower-level features \(rgb2\) and \(fss2\) undergo further processing by the CA and CAF modules to produce predicted feature maps \(f2\). These maps are then upsampled and combined through a series of 1 × 1 convolutions, resulting in the final output saliency map.
The above process can be written as follows:
Crossattentionfusion
The CAF (Cross-modal Attention Fusion) module, as shown in Fig. 2, is designed to perform high-level fusion of features from different modalities, thereby enhancing feature representation capabilities. By integrating Spatial Attention (SA) and Coordinate Attention (CoorA) mechanisms, the CAF module effectively focuses on key multi-modal features, improving the model’s ability to detect salient objects.

The structure of the CAF module.
Mathematical definition:
Let the input RGB features and auxiliary modality features be denoted as \(E_{rgb} \in R^{W \times H \times C}_{{^{{^{{}} }} }}\) and \(E_{fs} \in R^{W \times H \times C}_{{^{{^{{}} }} }}\), where H and W represent the spatial dimensions, and C is the number of channels.Apply the Spatial Attention mechanism (SA) to process the RGB and auxiliary modality features:
Here, the SA mechanism follows the self-attention framework:
\(SA(X) = SoftMax(\frac{{QK^{T} }}{{\sqrt {d_{k} } }})V\),For input \(X\)(i.e.\(E_{rgb}\) or \(E_{fs}\)),linear projection matrices transform \(X\) into query(\(Q\)),key(\(K\)),and value(\(V\))matrices.The dot-product \(QK^{T}\) measures spatial positional similarity, scaled by \(\sqrt {d_{k} }\) to stabilize gradient. After SoftMax, the result weights \(V\),generating spatially enhanced features \(E_{rgb}\) and \(E_{fs}\) which highlight critical spatial regions.
Concatenate the spatially enhanced features and apply convolution to generate a correlation weight map:
The 3 × 3 convolutional layer learns spatial-weighted parameters \(\theta\) and bias \(b\):\(f_{conv} = \theta * f_{concat} + b\).This step encodes cross-modal spatial dependencies, where the convolution acts as a weight adjuster to refine inter-modal feature interactions.
Perform element-wise multiplication of the concatenated features with the weight map:
Here, each element in \(f_{conv}\) acts as a gating weight. The operation dynamically amplifies or suppresses corresponding regions in \(f_{concat}\), achieving weight-driven fusion of cross-modal features based on learned spatial correlations.
Finally, apply the Coordinate Attention (CoorA) mechanism to enhance the fused features:
CoorA decomposes spatial attention into horizontal and vertical directions. First, global spatial information is encoded via average pooling:
\(\left\{ \begin{gathered} z_{h} = \frac{1}{H}\sum\nolimits_{i = 1}^{H} {X_{fusion} (i,:,;)} \hfill \\ z_{w} = \frac{1}{W}\sum\nolimits_{j = 1}^{W} {X_{fusion} (:,j:)} \hfill \\ \end{gathered} \right.\) Subsequently, projected features generate attention maps:\(A_{h} = \sigma (Conv_{h} (z_{h} )),A_{v} = \sigma (Conv_{v} (z_{w} ))\) where \(\sigma\) is the activation function. The final output \(X_{out} = A_{h} \otimes A_{v} \otimes X_{fusion}\)(\(\otimes\) denotes element-wise multiplication) integrates coordinate-aware weights, enhancing features with precise spatial location information.
The process begins by applying the Spatial Attention (SA) mechanism to both the RGB and auxiliary modality features, resulting in spatially enhanced features \(E_{rgb\_enh}\) and \(E_{fs\_enh}\). These enhanced features are then concatenated, followed by the application of a 3 × 3 convolutional layer to generate the correlation weight map \(X_{fusion}\).
Next, element-wise multiplication is performed between the weight map and the spatially enhanced features, placing greater emphasis on important features from both modalities. The weighted features are then concatenated and passed through another 3 × 3 convolutional layer to produce the integrated feature map \(X_{out}\).
Finally, the integrated features undergo processing through the Coordinate Attention (CoorA) module to improve spatial localization, allowing the model to focus more effectively on salient regions in the feature maps.
This fusion process results in the final fused feature map \(X_{out}\), which contains richer, more critical multi-modal information and provides robust support for downstream tasks.
To validate the synergy between Spatial Attention (SA) and Coordinate Attention (CoorA) in the CAF module, we conducted ablation experiments isolating their contributions. Table 1 summarizes the results, with metrics including Mean Absolute Error (MAE) (lower is better) and three structural similarity measures: F-measure (Fm), E-measure (Em), and S-measure (Sm) (higher are better).
Experimental Design:Control Group 1 (SA-only): Retains SA to evaluate local spatial dependency capture.Control Group 2 (CoorA-only): Uses CoorA to assess global positional encoding.Experimental Group (Full CAF): Combines both SA and CoorA as the proposed architecture.
All groups were trained on the VT821 dataset (821 high-resolution images with diverse object distributions and complex backgrounds) under identical conditions:
The CAF module combines spatial attention (SA) and coordinate attention (CoorA) to exploit both local spatial dependencies and global positional correlations. We formalize this as follows:
Given input features \(E_{RGB} \in R^{H \times W \times C}\) and \(E_{fs} \in R^{H \times W \times C}\), SA computes cross-modal spatial correlations via:
where \(Q = W_{q} E_{RGB} ,K = W_{k} E_{fs} ,V = W_{v} E_{fs}\) are query, key, and value matrices. The scaling factor \(\sqrt {d_{k} }\) stabilizes gradients.
Coordattention
The CoordAtt (Coordinate Attention) module, as shown in Fig. 3, is a lightweight attention mechanism designed to enhance the model’s selective focus on both spatial and channel dimensions of features. By incorporating coordinate information into the spatial dimension, CoordAtt enables the network to focus on the positional information of target regions without significantly increasing the computational cost. This mechanism greatly improves the model’s accuracy and sensitivity to object locations in saliency detection tasks.

The structure of the CoorA module.
In TCAINet, the primary role of CoordAtt is to enhance the output after multi-modal feature fusion, allowing the model to focus more accurately on salient regions in the fused features.
The process begins by applying global average pooling to the input features along the height and width directions. This generates two 1D feature vectors, each representing global spatial information for the height and width dimensions, respectively. These vectors provide the model with a global context along both spatial dimensions.
Once the feature vectors are obtained, CoordAtt uses shared fully connected layers to transform the height and width vectors into more expressive forms. These transformed vectors are then concatenated along the channel dimension to capture interactions between spatial and channel dimensions. This allows the model to allocate attention weights based on both spatial position and channel-wise features, enhancing feature relevance.
The concatenated features are passed through an activation function before being processed by a per-channel convolutional layer, which maps the result back to the original number of channels. This generates channel attention weights that indicate the importance of each channel while incorporating positional information.
Finally, CoordAtt multiplies the generated attention weights element-wise with the original input features, producing the weighted features. This operation amplifies the features in salient regions while suppressing irrelevant regions, allowing the model to focus more precisely on the target areas.
CoordAtt effectively enhances the model’s sensitivity to both spatial and channel dimensions while maintaining low computational overhead. This makes it particularly suitable for multi-modal feature fusion networks like TCAINet, enabling more accurate saliency object detection while staying lightweight and efficient.
CoorA encodes positional priors by decomposing spatial attention into horizontal \(A_{h}\) and \(A_{w}\) vertical components:
where \(\sigma\) is the sigmoid function, and \(f_{h,} f_{w}\) are 1D convolutions. The final output \(F_{out} = F \cdot (A_{h} \otimes A_{w} )\) is,where \(\cdot\) denotes element-wise multiplication.
The SA mechanism captures inter-modal pixel-wise relationships, while CoorA injects positional awareness to disambiguate spatially overlapping features. Their combination ensures that fused features retain both semantic coherence and geometric precision, which is critical for handling occlusions and complex backgrounds.
Attentionaugmenteddecoder
The Adaptive Attention Enhancement Decoder (AAD) module, as shown in Fig. 4, progressively restores the spatial resolution of feature maps through multi-level feature fusion operations, enhancing the transfer of inter-layer information and the reconstruction of feature details. This process enables more detailed and accurate saliency object detection, particularly in complex scenes.

The structure of the AAD module.
Mathematical definition:
Let the input feature maps be denoted as:
where H1,W1,C1 and H2,W2,C2 represent the spatial height, width, and the number of channels of \(f_{s}\) and \(f_{d}\) respectively.
Downsample \(f_{s}\) to obtain \(f^{\prime}_{s}\):
Concatenate \(f^{\prime}_{s}\) and \(f_{d}\) along the channel dimension, and apply a 3 × 3 convolution to fuse the features:
Compute the enhanced feature map by adding \(F_{fusion1}\) to \(f_{s}\):
Upsample \(F_{s} ^{\prime\prime}\) to match the spatial resolution of \(f_{d}\):
Concatenate \(F_{s}^{\prime \prime \prime }\) and \(f_{d}\), and apply a 3 × 3 convolution to further fuse the features:
Compute the new enhanced feature map by adding \(F_{fusion2}\) to \(f_{d}\):
Concatenate \(f_{d}^{\prime }\) and \(F_{s}^{\prime \prime \prime }\), and apply a 3 × 3 convolution:
Apply the Channel Attention (CA) module after the convolution to obtain the final output feature map:
The input feature maps \(f_{s}\) and \(f_{d}\) undergo a series of operations designed to fuse features at different levels. Initially, \(AvgPool\) is downsampled to reduce its resolution by half, matching the spatial scale of \(f_{d}\). The downsampled \(f_{s}\) is then concatenated with \(f_{d}\) and passed through a 3 × 3 convolutional layer. The resulting output is added back to the original feature map \(f_{d}\), forming an enhanced feature map \(f_{s\_enh}\). This fusion operation preserves deep feature details and improves the complementarity between features at different levels.
Next, the enhanced feature map \(f_{d}\) \(Upsample\) is upsampled to double its resolution, bringing it to the same spatial scale as \(f_{s}\). The upsampled \(f_{d}\) is concatenated with the original \(f_{s}\), and passed through a second 3 × 3 convolutional layer. The resulting feature map is then added to the original \(f_{s}\), producing a new enhanced feature map \(f_{d\_enh}\). This step maintains spatial information while further improving the model’s ability to capture fine-grained details.
Finally, the enhanced feature map \(f_{d\_enh}\) is concatenated with the upsampled feature map \(f_{s\_enh}\), combining information from multiple levels of abstraction. After passing through a 3 × 3 convolutional layer, this concatenated feature map is processed by the Channel Attention (CA) module to produce the final output feature map \(f\) of the decoder. This multi-level fusion approach effectively integrates high-level semantic information with low-level spatial details, providing rich and detailed feature representations for the saliency detection task.
The design of the AAD module aims to recover spatial resolution progressively while carefully fusing hierarchical features, thereby producing more accurate target predictions in complex scenes.
The process described above can be written as follows:
The AAD module progressively refines multi-scale features through a hierarchical fusion strategy. Let \(F_{s}^{(l)} ,F_{d}^{(l)}\) denote the feature map at level \(l\) and scale \(s,d\). The decoding process is governed by:
At each layer, features are fused via residual connections and up/downsampling:
where \(Up( \cdot )\) denotes bilinear upsampling.
After fusion, CA dynamically reweights channels to suppress noise:
The AAD’s design is motivated by the need to balance semantic abstraction (via downsampling) and detail preservation (via skip connections). Mathematically, the residual fusion ensures gradient flow across scales, while CA acts as a feature selector, emphasizing discriminative channels. This formulation is provably superior to naive concatenation-based decoders, as shown in our ablation studies (Table 6).
Channel attention (CA)
The Channel Attention (CA) mechanism, illustrated in Fig. 5, is a critical component that enhances the network’s capacity to prioritize essential features by dynamically adjusting the weight of each channel within the feature map. In the TCAINet model, the CA module is integrated specifically to improve feature selection efficiency.

The structure of the CA module.
Mathematical definition:
Let the input feature map be denoted as:
where H is the height, W is the width, and C is the number of channels.
For each channel C, the global average pooling operation computes the average value across the spatial dimensions:
This produces the average value for each channel c.
For each channel c, the global max pooling operation computes the maximum value across the spatial dimensions:
This produces the maximum value for each channel c.
The pooled results are concatenated and passed through a fully connected layer (optionally with hidden layers) to obtain the channel weights:
where \(W_{f}\) is the weight matrix of the fully connected layer, \(\sigma\) is the activation function (e.g., sigmoid), and bbb is the bias term.
Finally, the input feature map f is weighted by the channel weights to obtain the weighted feature map:
This produces the output feature map with the adjusted channel-wise attention.
Theoretical validation
To further validate the CAF and AAD modules, we provide a theoretical analysis of their convergence properties:
Let \(L_{CAF}\) denote the loss function. Using the Lipschitz continuity of SA and CoorA, we show that:
\(||\forall L_{CAF} (F_{fused} ){\kern 1pt} \,|| \le \gamma ||\,\forall L\,(F_{RGB} ,\,F_{T} )\,||\),where \(\gamma\) < 1, proving stable optimization.
The AAD’s residual structure satisfies the conditions of the Banach fixed-point theorem, ensuring convergence to a unique solution under iterative refinement.
These analyses confirm that our modules are theoretically well-founded and optimize efficiently.
Experiment design and results analysis
Dataset
This study evaluates the performance of the TCAINet model using three distinct datasets: VT821, VT1000, and VT5000.
VT821: This dataset consists of 821 pairs of RGB-T images that are initially misaligned, requiring manual alignment. It provides a diverse set of RGB-T image pairs, enabling the model to learn the relationship between visual and thermal imaging data across a variety of scenes39.The VT821 dataset consists of 821 RGB-T images captured under diverse conditions, such as varying lighting, weather, and complex backgrounds. The images in this dataset were initially misaligned, requiring manual alignment for accurate training. This dataset provides a wide variety of real-world scenarios to evaluate cross-modal fusion performance. It is beneficial for validating the model’s robustness and adaptability in diverse environments.
VT1000: Containing 1000 pairs of aligned RGB-T images, this dataset is designed with relatively simple scenes, making it ideal for evaluating the model’s performance under more controlled conditions. The alignment of images minimizes the impact of alignment issues, allowing the model to focus more directly on saliency detection40.The VT1000 contains 1,000 pairs of aligned RGB-T images with relatively simple scenes, ensuring minimal impact from alignment issues. The controlled conditions allow for a focused evaluation of saliency detection accuracy without interference from misalignment noise. This dataset is ideal for benchmarking the model’s performance under more controlled scenarios.
VT5000: A large-scale dataset featuring RGB-T images captured in a variety of real-world scenes and under different weather conditions. This dataset is valuable for assessing the model’s robustness in diverse, real-world scenarios. For the experiments, 2500 pairs of RGB-T images from VT5000 were used for training, while the remaining images, together with those from VT821 and VT1000, formed the test set41.The VT5000 is a large-scale dataset featuring RGB-T images captured across various real-world scenarios, including diverse weather conditions such as fog, rain, and low light. For training, we used 2,500 pairs of images, while the remaining samples, together with VT821 and VT1000, formed the test set. This dataset is critical for evaluating the model’s scalability and robustness in handling complex and large-scale real-world data.
To enhance the TCAINet model’s generalization and adaptability, data augmentation techniques such as random flipping, rotation, and cropping were applied during training. These strategies increased the diversity of the training samples, helping the model better learn salient object features, which led to improved performance on the test set.
The experiments were conducted in the following environment: the hardware configuration included a system with an NVIDIA RTX 3090 GPU, 45GB of RAM, and a 14-core Intel Xeon Platinum 8362 processor. The software environment included Python 3.8 along with relevant libraries, such as PyTorch 1.8.1 and OpenCV 4.5, ensuring efficient training and testing of the model. This setup provided sufficient computational resources for processing large-scale datasets and supporting the complex training of the model.
To ensure reproducibility, we explicitly define all augmentation parameters as follows:MixUp: Implemented with α = 1.0 (Beta distribution).CutMix: Randomly replaces 20%–50% of the image area with patches from another image, applied with a 50% probability.Salt-and-Pepper Noise: The noise intensity ρ is randomly sampled from [0.01, 0.05], corrupting 1%–5% of pixels.Poisson Noise: Simulated with intensity scaling λ ∈ [0.8,1.2].
Evaluation metrics
The Mean Absolute Error (MAE)42is a widely used evaluation metric in the Salient Object Detection (SOD) task. It quantifies the average absolute difference between the predicted saliency map and the ground truth label. In particular, a lower MAE value indicates a smaller prediction error, reflecting better model performance.
The width (W) and height (H) of an image define its total number of pixels. A lower MAE value indicates a smaller deviation between the model’s prediction and the ground truth, reflecting higher model accuracy. This metric effectively quantifies the discrepancy between the predicted saliency map and the ground truth map.
The F-measure (Fm)43is a comprehensive evaluation metric that represents the harmonic mean of precision and recall. It is used to assess the model’s ability to balance precision and recall, making it a commonly used metric in tasks such as information retrieval and image processing.
In this study, we set the calculation parameter for the F-measure to 0.3.
S-measure (Sm): While MAE and F-measure are widely used metrics for evaluating saliency detection algorithms, they primarily focus on pixel-level comparisons and do not fully account for the importance of structural information in saliency maps. Research has shown that the human visual system is highly sensitive to object structures. Therefore, we adopted the Structural Similarity Measure (SSIM)44as a supplementary evaluation metric. This method integrates region-based (R) and object-based (O) structural similarity, providing a more comprehensive assessment of the algorithm’s performance.
Following the recommendations of Fan et al., we set a default value of \(\alpha\) = 0.5 for the similarity weight when calculating the Structural Similarity measure (SSIM). This setting is intended to balance the contributions of region-based and object-based perception in the overall structural similarity assessment.
E-measure (Em): The E-measure, proposed by Fan et al.45, is an evaluation metric used to assess the quality of binarized saliency maps. This method aims to quantify the correlation between the predicted saliency map and the ground truth image in terms of spatial dimensions, providing a more accurate reflection of the model’s performance.
In this context, W and H represent the width and height of the saliency map, respectively, and \(\phi\) denotes the enhanced alignment matrix.
Experiment and result analysis
This section presents a comprehensive comparison of 19 state-of-the-art Salient Object Detection (SOD) techniques to validate the superior performance of the modules designed in our proposed model. The comparison covers the following categories:Two traditional RGB-T SOD methods: SGDL46(Tu et al.) and MTMR47(Wang et al.);Three deep learning-based RGB single-modal SOD methods: R3 Net (Deng et al.)48CPD (Wu et al., 2019)49, and PoolNet (Liu et al.)50;Fourteen deep learning-based RGB-T SOD methods: ADF (Tu et al.)41, S2MA51, AFNet52, MESDNet53, MIED, M3S-NIR, TANet, JLDCF54, PDNet (Zhu et al., 2019)55, SwinNet (Liu et al.)56, LSNet (Zhou et al.)57, SwinMCNet58, UidefNet59, and HRTransNet60.
All deep learning models were trained on the VT5000 training set, which consists of 2,500 images. To ensure a fair comparison, all baseline models were retrained on the VT5000 dataset and evaluated using the evaluation criteria outlined in FMCF (Zhang et al.)61.
Quantitative results
The quantitative evaluation highlighted the significant potential of the proposed TCAINet network. The model’s performance was rigorously evaluated using four critical metrics: Mean Absolute Error (MAE), F-measure (Fm), S-measure (Sm), and E-measure (Em). As shown in Table 2, the experimental results demonstrated that TCAINet surpassed current state-of-the-art salient object detection methods on the VT821, VT1000, and VT5000 datasets. Specifically, TCAINet achieved improvements of 0.653% in Sm, 1.384% in Em, 1.019% in Fm, and 5.83% in MAE compared to existing approaches. These findings comprehensively validate the effectiveness of the proposed model in enhancing detection accuracy and optimizing feature fusion.
In addition to the metrics mentioned above, we have also evaluated the model using two additional metrics: Intersection over Union (IoU) and F1-score. As shown in table 3.These metrics provide further insight into the model’s ability to localize accurately and segment salient objects.
IoU measures the overlap between the predicted saliency regions and the ground truth. It is computed as the ratio of the intersection of the predicted and ground truth regions to the union of these regions. A higher IoU indicates better localization and segmentation of the salient objects. This metric provides a useful measure of the model’s spatial accuracy.
The F1-score is the harmonic mean of precision and recall, offering a balanced evaluation of the model’s ability to detect salient objects. It is especially important in cases of class imbalance, where the background dominates, and the model must focus on detecting the salient objects.
Comparison of methods
Prediction performance comparison of TCAINet and other methods
Figure 6 presents several challenging scenes to validate the performance of TCAINet under diverse conditions. The selected sample images feature complex backgrounds, weak object boundaries, partial occlusion, and low contrast, all of which present significant challenges for saliency detection. It is evident that TCAINet effectively preserves the integrity of the salient objects in these difficult scenarios while successfully suppressing background noise.

Visual comparisons with other methods on RGB-T datasets.
For example, in scenes with weak object boundaries, TCAINet accurately delineates the object contours, whereas other models tend to lose fine edge details. In cases of partial occlusion, TCAINet continues to distinguish the object from the background, demonstrating its strong adaptability and robustness to various challenging conditions. These results underscore TCAINet’s superior performance in handling complex and noisy environments, where other methods often struggle.
Overall, TCAINet performs exceptionally well in complex backgrounds and low-contrast scenarios, accurately identifying object regions in salient object detection while preserving fine details. The comparison results highlight TCAINet’s significant advantage in edge detail preservation and noise suppression, confirming its adaptability and robustness across a variety of challenging conditions.
Results visualization and performance evaluation
In this section, we provide an in-depth analysis of the experimental results on the VT821, VT1000, and VT5000 datasets. To visually evaluate the performance of the TCAINet model, we plot precision-recall (PR) curves and F-measure values for each dataset. These charts offer a clear visual comparison of the model’s detection accuracy and adaptability across different datasets.
PR curve plotting and analysis
To evaluate the performance of the salient object detection model, we generate precision-recall (PR) curves to illustrate the balance between precision and recall at various thresholds. Figures 7, 8, and 9 present the PR curves for the VT821, VT1000, and VT5000 datasets, respectively. By comparing the curves across these datasets, we can intuitively assess the detection performance and stability of TCAINet in diverse scenarios.

P-R curve of TCAINet and other 19 SOTA.

P-R curve of TCAINet and other 19 SOTA.

P-R curve of TCAINet and other 19 SOTA.
The PR curve for the VT821 dataset is shown in Fig. 7. On this dataset, TCAINet’s Precision-Recall curve significantly outperforms other models. Specifically, TCAINet maintains a high precision (around 0.8) across a wide recall range (0.6–0.9), demonstrating its ability to detect most salient objects while minimizing false positives. In contrast, the precision of other models drops noticeably below 0.7 when the recall rate reaches 0.8, indicating a higher occurrence of false positives under high recall conditions. Additionally, TCAINet’s Precision-Recall curve is smoother overall, suggesting stronger robustness when handling salient objects with varying confidence levels.
The PR curve for the VT1000 dataset is shown in Fig. 8. Once again, TCAINet demonstrates superior performance. When the recall rate is between 0.7 and 0.9, TCAINet’s precision remains stable at around 0.9, while the precision of many other models drops to approximately 0.75. This highlights TCAINet’s ability to maintain high precision while achieving high recall. Furthermore, in the low recall range (< 0.3), TCAINet’s precision stays above 0.95, clearly outperforming the other models. This indicates that TCAINet exhibits excellent detection accuracy during the early stages of salient object detection (low recall rate) and continues to maintain precision as the recall rate increases.
The PR curve for the VT5000 dataset is shown in Fig. 9. On this more challenging dataset, TCAINet continues to outperform other models. When the recall rate is between 0.7 and 0.9, TCAINet maintains a precision of around 0.85, whereas other models show a gradual decline in precision to the range of 0.6–0.7. This performance indicates that TCAINet can maintain high accuracy even when working with large-scale datasets. In the low recall range (< 0.3), TCAINet’s precision remains significantly higher than that of other models, reaching above 0.9. This suggests that TCAINet maintains high detection accuracy early in the salient object detection process and continues to deliver stable performance as recall increases.
In addition, we also calculated the F-measure (F value) for each dataset. The F-measure is the harmonic mean of precision and recall, providing a comprehensive assessment of a model’s performance. The formula for calculating the F-measure is as follows:
By comparing the F-measure (F-value) across different datasets, we can obtain a more intuitive understanding of the model’s overall performance in various scenarios. The F-values for the VT821, VT1000, and VT5000 datasets are shown in Figs. 10, 11, and 12, respectively. These figures provide a clear illustration of the model’s ability to balance precision and recall under different conditions, demonstrating the robustness and adaptability of the TCAINet model across diverse datasets.

F-measure curve of TCAINet and other 19 SOTA models.

F-measure curve of TCAINet and other 19 SOTA models.

F-measure curve of TCAINet and other 19 SOTA models.
The F-measure curves for the VT821, VT1000, and VT5000 datasets are shown in Figs. 10, 11, and 12, respectively:
VT821 F-measure Curve (Fig. 10):On the VT821 dataset, TCAINet consistently outperforms other comparison models, as evidenced by its superior F-measure curve. At low confidence thresholds (0.1–0.4), TCAINet’s F-measure rises rapidly, peaking above 0.85 at a threshold of 0.3. In contrast, other models show relatively lower F-measure values in this range, averaging around 0.75. As the threshold increases, TCAINet’s F-measure remains stable, even in the high threshold range (0.7–0.9), staying around 0.8, which is significantly higher than the other models, indicating robust performance. The smoothness of TCAINet’s curve also reflects its stable detection performance across different confidence levels.
VT1000 F-measure Curve (Fig. 11):For the VT1000 dataset, TCAINet achieves an F-measure as high as 0.88 in the low-to-medium confidence threshold range (0.1–0.5), outperforming other models. This demonstrates TCAINet’s ability to excel in capturing salient objects within complex scenes. In the mid-to-high threshold range (0.5–0.8), TCAINet maintains its leadership, reinforcing its robustness on this dataset. In comparison, traditional models show a significant decline in F-measure at higher thresholds, revealing their weaker performance under high-confidence conditions. Overall, TCAINet’s F-measure curve is higher and exhibits smaller fluctuations, suggesting more stable and consistent performance in salient object detection on the VT1000 dataset.
VT5000 F-measure Curve (Fig. 12):On the large-scale VT5000 dataset, TCAINet’s F-measure curve continues to showcase its significant advantage, especially in the mid-to-high threshold range (0.4–0.9), where its F-measure remains consistently above 0.85, peaking at 0.88 around a threshold of 0.6. In contrast, other models experience a gradual decline in F-measure at higher thresholds, with some falling below 0.7. This highlights TCAINet’s excellent generalization ability when applied to large-scale datasets. Its stability and accuracy are further validated in scenarios that demand high-precision detection.
Summary:These results emphasize TCAINet’s ability to maintain consistent and accurate performance across various datasets. The model demonstrates superior robustness and versatility in different detection conditions, ensuring reliable performance in both small and large-scale scenarios.
Ablation experiments
In this section, we evaluate the contribution of each key module in the TCAINet model to its overall performance through ablation experiments. These experiments systematically remove or replace core modules in the model to measure their impact on accuracy, stability, and efficiency. The ablation experiments consist of the following three schemes:
Removing the channel attention (CA) module
In the first experiment, we remove the Channel Attention (CA) module to assess its impact on feature selection. The CA module is crucial for enhancing the model’s ability to focus on informative channels, thereby improving both accuracy and robustness. By comparing the performance of the model with and without the CA module, we can quantify its contribution to the feature selection process and evaluate how its absence affects the overall performance of TCAINet.
Replacing the cross-modal attention fusion (CAF) module
The second experiment involves replacing the Cross-modal Attention Fusion (CAF) module with alternative multi-modal fusion strategies. This allows us to investigate how the CAF module contributes to the effective integration of cross-modal information, such as RGB and depth data. By testing different fusion strategies, we can evaluate the performance improvements brought by CAF in terms of combining features from different modalities. This will help us better understand the importance of CAF in leveraging the complementary information from multiple modalities.
Replacing the AAD (adaptive attention decoder) module
The third experiment involves replacing the AAD (Adaptive Attention Decoder) module to assess its role in restoring spatial resolution during the decoding phase. The AAD module plays a key role in recovering fine-grained spatial details in the output. By comparing the performance with and without the AAD module, we can examine how its presence affects the model’s ability to recover high-resolution details and enhance final detection accuracy, particularly in complex or low-resolution scenarios.
Through these ablation experiments, we aim to gain a deeper understanding of the individual contributions of each module and demonstrate the significance of TCAINet’s design choices in enhancing the performance of salient object detection under complex and varied conditions.
Effectiveness of the CA Module: To evaluate the impact of the Channel Attention (CA) module, we removed it while keeping all other operations unchanged. The experimental results are summarized in Table 4, where"No-CA"represents the configuration without the CA module. The results indicate that removing the CA module led to a decrease in performance:
-
The Mean Absolute Error (MAE) increased by 0.98%.
-
The F-measure (Fm) decreased by 0.22%.
-
The Saliency map (Sm) decreased by 0.89%.
-
The Edge map (Em) decreased by 0.32%.
These results confirm that the CA module plays an important role in enhancing the model’s ability to focus on informative channels, and its removal negatively impacts the model’s accuracy and robustness.
Effectiveness of the CAF Module: To assess the contribution of the Cross-modal Attention Fusion (CAF) module, we replaced it with the SCA (Spatial and Channel Attention) module, which performs cross-modal feature fusion on the third and fourth feature maps of the RGB and IR branches using spatial and channel attention mechanisms (as shown in Fig. 13). In Table 5,“SCA”refers to this experimental setup. The performance results demonstrate a clear performance drop when CAF is replaced with SCA:
-
The MAE increased by 18.57%.
-
The F-measure decreased by 2.70%.
-
The Sm decreased by 1.65%.
-
The Em decreased by 1.58%.

The structure of the SCA module.
These findings underscore the effectiveness of the CAF module in cross-modal feature fusion and its critical role in improving the model’s performance. Replacing CAF with SCA resulted in a substantial decrease in performance, highlighting the CAF module’s significant contribution to the overall model’s accuracy and robustness.
Effectiveness of the AAD Decoder Module: In this experiment, we replaced the AAD (Adaptive Attention Decoder) module with the PredDecod decoder while keeping all other operations unchanged. The PredDecod decoder consists of several convolution and upsampling layers that progressively restore the spatial resolution, using skip connections to fuse features from different layers. It is composed of five main decoding layers, each restoring the size of the input feature map through upsampling and convolution operations, ultimately generating the target output. Additionally, the PredDecod decoder incorporates an edge detection module to assist in extracting edge information. In Table 6,“PredDecod”refers to this experimental setup.
The experimental results demonstrate the significant impact of replacing the AAD decoder with PredDecod:
-
The Mean Absolute Error (MAE) increased by 11.42%.
-
The F-measure (Fm) decreased by 0.67%.
-
The Saliency map (Sm) decreased by 1.52%.
-
The Edge map (Em) decreased by 1.28%.
These results highlight that while the PredDecod decoder can effectively restore spatial resolution, it falls short of the AAD decoder in terms of detail recovery and overall decoding performance. The AAD decoder plays an irreplaceable role in maintaining fine-grained spatial details and enhancing the final detection accuracy, thus contributing significantly to the model’s overall performance.
Table 7 evaluates the computational efficiency of TCAINet against competing models. TCAINet achieves 88.19M parameters and 91.86G FLOPs, significantly reducing model complexity compared to SwinNet (198.784M) and ADF (175.291M). However, its 1.53 FPS inference speed lags behind lightweight methods like LSNet (1.231 FPS) and EGNet (270.8 FPS). This trade-off stems from TCAINet’s hierarchical cross-modal fusion (CAF) and adaptive decoding (AAD) modules, which introduce additional computational overhead. Despite this, TCAINet outperforms all methods in accuracy (Table 2), demonstrating that its design prioritizes detection quality over raw speed. For real-world applications, further optimizations (e.g., knowledge distillation, dynamic inference pruning) could bridge this gap while retaining TCAINet’s superior performance.
Summary:The results of the ablation experiments validate the critical contributions of each module in the TCAINet model. The Channel Attention (CA) module significantly enhances the model’s ability to select informative features, improving detection accuracy and robustness. The Cross-modal Attention Fusion (CAF) module effectively integrates multimodal information, demonstrating its superiority in cross-modal feature fusion and significantly boosting performance. Finally, the Adaptive Attention Decoder (AAD) module ensures the high-quality reconstruction of object edges during the decoding phase, which is crucial for preserving fine details in the final output.
Together, the collaborative interaction of these modules allows TCAINet to achieve exceptional performance in multimodal saliency detection tasks, showcasing its ability to handle complex scenarios and improve detection quality across various modalities.
Conclusion
This paper presents TCAINet, an innovative Transformer-based Cross-modal Integration Network designed to advance multimodal saliency object detection. TCAINet integrates the Swin Transformer backbone encoder, the Channel Attention (CA) mechanism, the Cross-modal Attention Fusion (CAF) module, and the Adaptive Attention Decoder (AAD) module, enabling effective extraction, fusion, and representation of multimodal information. These components collectively enhance the model’s ability to capture key features and recover spatial resolution, demonstrating superior performance across a range of benchmark datasets.
The CA module improves feature selection by adaptively assigning weights to different channels, boosting the model’s ability to focus on the most informative features. The CAF module facilitates the efficient fusion of cross-modal features using spatial and channel attention, significantly improving the handling of multimodal data. The AAD decoder ensures high-quality reconstruction by gradually restoring spatial resolution and preserving object edges during the decoding phase. Together, these modules synergistically enable TCAINet to effectively integrate multimodal information in complex detection scenarios, achieving excellent saliency detection results.
Experimental results demonstrate that TCAINet outperforms existing state-of-the-art methods across multiple mainstream datasets, achieving superior accuracy in key evaluation metrics such as MAE and F-measure. These findings validate TCAINet’s effectiveness and highlight its significant contribution to saliency object detection tasks.
Future research could explore several avenues for enhancing TCAINet:
Investigating more efficient attention mechanisms to better handle large-scale data. As the volume of data continues to grow in real-world applications, developing attention mechanisms that can process large amounts of information more efficiently is crucial. This could involve exploring new architectures or modifications to existing attention mechanisms to reduce computational complexity while maintaining or improving performance. For example, researching sparse attention mechanisms that can selectively focus on relevant parts of the data may be a promising direction.
Incorporating multi-task learning to improve the model’s generalizability and adaptability. By training TCAINet on multiple related tasks simultaneously, such as object detection, semantic segmentation, and saliency detection, the model can learn more comprehensive and transferable features. This approach may help the model better generalize to different scenarios and improve its performance in various real-world applications. For instance, in an autonomous driving context, integrating saliency detection with other perception tasks like lane detection and pedestrian recognition could enhance the overall system’s reliability and adaptability.
Deepening the understanding of cross-modal relationships to further enhance the model’s fusion capabilities. Although TCAINet already demonstrates effective cross-modal fusion, there is still room for improvement. Future research could focus on developing more advanced techniques to capture and utilize the complementary information between different modalities. This could involve exploring novel feature representation methods or designing more sophisticated fusion architectures that can better handle the complex relationships between RGB and other modalities, such as thermal or depth information.
Optimizing dynamic reasoning in the model. This could involve developing algorithms that can adaptively adjust the model’s decision-making process based on the input data and the task requirements. For example, in scenarios with varying levels of noise or complexity, the model could dynamically allocate more computational resources to challenging regions or adjust its feature extraction and fusion strategies. By optimizing dynamic reasoning, TCAINet can potentially achieve better performance in real-time applications and complex environments.
Exploring model compression techniques to reduce the computational cost and improve the inference speed. While TCAINet shows excellent accuracy, its relatively lower inference speed compared to some lightweight models may limit its deployment in resource-constrained environments. Future research could focus on techniques such as knowledge distillation, pruning, and quantization to reduce the model’s size and computational requirements without sacrificing too much accuracy. This would make TCAINet more suitable for applications where real-time processing and low-power consumption are critical, such as mobile devices and edge computing platforms.
Data availability
The datasets and codes generated and analyzed during this study are publicly available at https://github.com/huyunfei0219/TCAINet. For further information or specific inquiries, please contact the corresponding author at huyunfei132306@136.com.
References
Z, (1) K, (1) Z, et al. Object Detection in 20 Years: A Survey[J]. 2019.
YU Y, WAN C, FU Q, et al. Techniques and Challenges of Image Segmentation: A Review[J].
Gao, Y., Shi, M., Tao, D. & Chao, Xu. Database saliency for fast image retrieval. IEEE Trans. Multimed. 17(3), 359–369 (2015).
Lu, A., Li, C., Yan, Y., Tang, J. & Luo, B. RGBT tracking via multi-adapter network with hierarchical divergence loss. IEEE Trans. Image Process. 30, 5613–5625 (2021).
Kim, J. H. & Lee, J. Layered non-photorealistic rendering with anisotropic depth-of-field filtering[J/OL]. Multim. Tools Appl. https://doi.org/10.1007/s11042-019-08387-2 (2020).
McCord, J. M. & Edeas, M. A. SOD, oxidative stress and human pathologies: a brief history and a future vision. Biomed. Pharmacother. 59(4), 139–142 (2005).
Zhang, X. et al. STWANet: Spatio-Temporal Wavelet Attention Aggregation Network for Remote Sensing Change Detection[J]. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. https://doi.org/10.1109/JSTARS.2025.3551093 (2025).
Li K, Wang D, Hu Z, et al. FD2-Net: Frequency-Driven Feature Decomposition Network for Infrared-Visible Object Detection[J]. arXiv preprint arXiv:2412.09258, 2024.
Wei, L. & Zong G. EGA-Net: Edge feature enhancement and global information attention network for RGB-D salient object detection[J]. Inf. Sci. 626, 223–248 (2023).
Hu, X., Sun, F., Sun, J., Wang, F. & Li, H. Cross-modal fusion and progressive decoding network for RGB-D salient object detection. Int. J. Comput. Vis. https://doi.org/10.1007/s11263-024-02020-y (2024).
Cong, R. et al. CIR-Net: Cross-modality interaction and refinement for RGB-D salient object detection. IEEE Trans. Image Process. 31, 6800–6815 (2022).
Li K, Wang D, Hu Z, et al. Unleashing channel potential: Space-frequency selection convolution for SAR object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 17323–17332 (2024).
Wu, Y.-H. et al. MobileSal: Extremely efficient RGB-D salient object detection. IEEE Trans. Pattern Anal. Mach. Intell. 44(12), 10261–10269 (2021).
Zeng, Z., Liu, H., Chen, F. & Tan, X. Airsod: A lightweight network for rgb-d salient object detection. IEEE Trans. Circuits Syst. Video Technol. https://doi.org/10.1109/TCSVT.2023.3295588 (2023).
Zhou, W., Zhu, Y., Lei, J., Yang, R. & Lu, Yu. LSNet: Lightweight spatial boosting network for detecting salient objects in RGB-thermal images. IEEE Trans. Image Process. 32, 1329–1340 (2023).
Itti, L., Koch, C. & Niebur, E. A model of saliency-based visual attention for rapid scene analysis[J/OL]. IEEE Trans. Pattern Anal. Mach. Intell. https://doi.org/10.1109/34.730558.10.1109/34.730558 (1998).
WANG G, LI C, MA Y, et al. RGB-T Saliency Detection Benchmark: Dataset, Baselines, Analysis and a Novel Approach[M/OL]//Image and Graphics Technologies and Applications,Communications in Computer and Information Science. 359-369 https://doi.org/10.1007/978-981-13-1702-6_36 (2018).
Tang, J. et al. RGBT salient object detection: Benchmark and a novel cooperative ranking approach[J/OL]. IEEE Trans. Circuits Syst. Video Technol. https://doi.org/10.1109/tcsvt.2019.2951621 (2020).
WU Z, SU L, HUANG Q. Cascaded Partial Decoder for Fast and Accurate Salient Object Detection[C/OL]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA. https://doi.org/10.1109/cvpr.2019.00403 (2019).
LIU J J, HOU Q, CHENG M M, et al. A Simple Pooling-Based Design for Real-Time Salient Object Detection[C/OL]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA. https://doi.org/10.1109/cvpr.2019.00404 (2019).
PANG Y, ZHAO X, ZHANG L, et al. Multi-Scale Interactive Network for Salient Object Detection[C/OL]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA. https://doi.org/10.1109/cvpr42600.2020.00943 (2020).
Gupta, A. K., Seal, A. & Khanna, P. Divergence based SLIC[J/OL]. Electron. Lett. https://doi.org/10.1049/el.2019.1092.10.1049/el.2019.1092 (2019).
Zhang X, Yuan G, Hua Z, et al. TSMGA: Temporal-Spatial Multi-Scale Graph Attention Network for Remote Sensing Change Detection[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025.
Fan, D. P. et al. BBS-Net: RGB-D salient object detection with a bifurcated backbone strategy network[M/OL]//Computer Vision – ECCV. Lect. Notes Comput. Sci. 2020, 275–292. https://doi.org/10.1007/978-3-030-58610-2_17 (2020).
Zhang, M. et al. Asymmetric two-stream architecture for accurate RGB-D saliency detection[M/OL]//Computer Vision – ECCV. Lect. Notes Comput. Sci. 2020, 374–390. https://doi.org/10.1007/978-3-030-58604-1_23 (2020).
PIAO Y, JI W, LI J, et al. Depth-Induced Multi-Scale Recurrent Attention Network for Saliency Detection[C/OL]//2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea (South). https://doi.org/10.1109/iccv.2019.00735 (2019).
Liu, Z. et al. SwinNet: Swin transformer drives edge-aware RGB-D and RGB-T Salient Object Detection[J/OL]. IEEE Trans. Circuits Syst. Video Technol. https://doi.org/10.1109/tcsvt.2021.3127149 (2022).
Liang, Y. et al. Multi-modal interactive attention and dual progressive decoding network for RGB-D/T salient object detection[J/OL]. Neurocomputing https://doi.org/10.1016/j.neucom.2022.03.029 (2022).
Li, G. et al. Hierarchical alternate interaction network for RGB-D salient object detection. IEEE Trans. Image Process. 30, 3528–3542 (2021).
Sun, F., Ren, P., Yin, B., Wang, F. & Li, H. CATNet: A cascaded and aggregated transformer network for RGB-D salient object detection. IEEE Trans. Multimed. https://doi.org/10.1109/TMM.2023.3294003 (2023).
Piao, Yongri, Wei Ji, Jingjing Li, Miao Zhang, and Huchuan Lu. "Depth-induced multi-scale recurrent attention network for saliency detection." In Proceedings of the IEEE/CVF international conference on computer vision. 7254–7263 (2019).
Wang, R. et al. Attention-guided multi-modality interaction network for RGB-D salient object detection. ACM Trans. Multimed. Comput. Commun. Appl. 20(3), 1–22 (2023).
Zhang, S. et al. CMPNet: A cross-modal multi-scale perception network for RGB-T crowd counting[J]. Futur. Gener. Comput. Syst. 164, 107596 (2025).
Li, Z. et al. CDME: Convolutional dictionary itrative model for pansharpening with mixture-of-experts[J]. IEEE Geosci. Remote Sens. Lett. https://doi.org/10.1109/LGRS.2025.3545472 (2025).
Pan, S. et al. A lightweight robust RGB-T object tracker based on Jitter Factor and associated Kalman filter[J]. Inf. Fusion 117, 102842 (2025).
Wang, Q. et al. High performance RGB-Thermal Video Object Detection via hybrid fusion with progressive interaction and temporal-modal difference[J]. Inf. Fusion 114, 102665 (2025).
Guo, X., Zhou, W. & Liu, T. Multilevel attention imitation knowledge distillation for RGB-thermal transmission line detection[J]. Expert Syst. Appl. 260, 125406. https://doi.org/10.1016/j.eswa.2024.125406 (2025).
Li, Z., Yuan, G. & Li, J. DUCD: Deep unfolding convolutional-dictionary network for pansharpening remote sensing image[J]. Expert Syst. Appl. 249, 123589 (2024).
Wang, Guizhao, et al. "RGB-T saliency detection benchmark: Dataset, baselines, analysis and a novel approach." Image and Graphics Technologies and Applications: 13th Conference on Image and Graphics Technologies and Applications, IGTA 2018, Beijing, China, Revised Selected Papers 13. Springer Singapore, (2018).
Tu, Z. et al. RGB-T image saliency detection via collaborative graph learning. IEEE Trans. Multimed. https://doi.org/10.1109/tmm.2019.2924578 (2020).
Tu, Z. et al. RGBT salient object detection: A large-scale dataset and benchmark. IEEE Trans. Multimed. https://doi.org/10.1109/tmm.2022.3171688 (2022).
Perazzi, Federico, et al. "Saliency filters: Contrast based filtering for salient region detection." IEEE conference on computer vision and pattern recognition. IEEE, (2012).
Achanta, Radhakrishna, et al. Frequency-Tuned Salient Region Detection.
Fan, Deng-Ping, et al. “Structure-Measure: A New Way to Evaluate Foreground Maps.”IEEE International Conference on Computer Vision (ICCV), https://doi.org/10.1109/iccv.2017.487 (2017).
Fan, Deng-Ping, et al. “Enhanced-Alignment Measure for Binary Foreground Map Evaluation.” Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, https://doi.org/10.24963/ijcai.2018/97 (2018).
Wang, Guizhao, et al. “RGB-T Saliency Detection Benchmark: Dataset, Baselines, Analysis and a Novel Approach.” Image and Graphics Technologies and Applications,Communications in Computer and Information Science 359–69 https://doi.org/10.1007/978-981-13-1702-6_36 (2018).
Tu, Z. et al. RGB-T image saliency detection via collaborative graph learning. IEEE Trans. Multimed. 22(1), 160–173 (2019).
Deng, Zijun, et al. “R3Net: Recurrent Residual Refinement Network for Saliency Detection.” Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence https://doi.org/10.24963/ijcai.2018/95 (2018).
Wu, Zhe, et al. “Cascaded Partial Decoder for Fast and Accurate Salient Object Detection.” 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) https://doi.org/10.1109/cvpr.2019.00403 (2019).
Liu, Jiang-Jiang, et al. “A Simple Pooling-Based Design for Real-Time Salient Object Detection.” IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) https://doi.org/10.1109/cvpr.2019.00404 (2019).
Liu, Nian, et al. “Learning Selective Self-Mutual Attention for RGB-D Saliency Detection.” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) https://doi.org/10.1109/cvpr42600.2020.01377 (2020).
Wang, N. & Gong, X. Adaptive fusion for RGB-D salient object detection. IEEE Access 7, 55277–55284 (2019).
Peng, D. et al. MSEDNet: Multi-scale fusion and edge-supervised network for RGB-T salient object detection. Neural Netw. 171, 410–422 (2024).
Fu, Keren, et al. JL-DCF: Joint Learning and Densely-Cooperative Fusion Framework for RGB-D Salient Object Detection.
Zhu, Chunbiao, et al. “PDNet: Prior-Model Guided Depth-Enhanced Network for Salient Object Detection.” IEEE International Conference on Multimedia and Expo (ICME) https://doi.org/10.1109/icme.2019.00042 (2019).
Liu, Z. et al. SwinNet: Swin transformer drives edge-aware RGB-D and RGB-T salient object detection. IEEE Trans. Circuits Syst. Video Technol. https://doi.org/10.1109/tcsvt.2021.3127149 (2022).
Zhou, W. et al. LSNet: Lightweight spatial boosting network for detecting salient objects in RGB-thermal images. IEEE Trans. Image Process. https://doi.org/10.1109/tip.2023.3242775 (2023).
JIANG X, ZHU L, HOU Y. Mirror Complementary Transformer Network for RGB-thermal Salient Object Detection[J].
Wang, J. et al. Unidirectional RGB-T salient object detection with intertwined driving of encoding and fusion[J/OL]. Eng. Appl. Artificial Intell. https://doi.org/10.1016/j.engappai.2022.105162 (2022).
Tang, B. et al. HRTransNet: HRFormer-driven two-modality salient object detection. IEEE Trans. Circuits Syst. Video Technol. 33(2), 728–742 (2022).
Zhang, Q. et al. RGB-T salient object detection via fusing multi-level CNN features. IEEE Trans. Image Process. https://doi.org/10.1109/tip.2019.2959253 (2020).
Funding
This work was supported by 1. Liaoning Province Joint Fund Project (Project Number: 20240346); 2. University-local government scientific and technical cooperation cultivation project of Ordos Institute-LNTU,(YJY-XD-2024- B - 014).
Author information
Authors and Affiliations
Contributions
P. designed the study protocol and was responsible for collecting and analyzing the experimental data; H. wrote the first draft of the paper and revised and improved the subsequent versions; P.H.Z. Participated in the experimental manipulations and assisted in organizing the experimental data, and H.Y. was responsible for preparing the figures and tables in the paper. All authors participated in the discussion and review of the paper and are responsible for the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendice
Appendice
Python (Python Programming Language 3.8.12 https://www.python.org).
PyTorch(PyTorch Machine Learning Framework 1.8.1 + cu111 https://pytorch.org).
OpenCV(Open Source Computer Vision Library 4.5.5 https://opencv.org).
CUDA(NVIDIA CUDA® Parallel Computing Toolkit 11.3.0 CUDA 11.3 Archive)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Peng, H., Hu, Y., Yu, B. et al. TCAINet an RGB T salient object detection model with cross modal fusion and adaptive decoding. Sci Rep 15, 14266 (2025). https://doi.org/10.1038/s41598-025-98423-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-98423-z
