
Abstract
Aiming at the problems of low detection accuracy and poor generalization ability of underwater disease targets in inland waterways, an underwater disease target detection algorithm for inland waterways based on improved YOLOv5 is designed, which is denoted as YOLOv5-GBCE. Firstly, Bi-directional Feature Pyramid Network (BiFPN) is used to strengthen feature fusion and improve the accuracy of small target recognition. Secondly, the coordinate attention (CA) module is introduced to allocate attention resources to key areas, so as to reduce the interference of complex background in underwater environment. Then, EIoU is used as the frame loss function to speed up the network convergence rate and solve the problem of difficult and easy sample imbalance. Finally, the Ghost convolutional network is used to reduce the complexity and computation of the model. In order to verify the feasibility of the algorithm, based on the underwater disease data set collected by the project team, a variety of algorithms were selected for comparison and ablation experiments were designed to study the improvement and improvement effect of each module. The research results show that compared with the YOLOv5 s algorithm, the improved algorithm YOLOv5-GBCE improves the average accuracy (IOU = 0.5) of the algorithm by 6.2%, reaching 89.8%, and the detection speed reaches 78.25 FPS. The amount of model calculation is reduced by 25.9%, and the detection energy is detected in complex environments and small target scenarios.
Similar content being viewed by others


Introduction
Side-scan sonar technology captures high-resolution images of underwater targets by analyzing and processing the scattered echoes from submerged objects. Recent advancements in technological, coupled with expanding application scenarios, have broadened the application of side-scan sonar technology in port and maritime engineering, including channel surveys1, inland river monitoring2, and underwater target detection3. Sonar scanning operations face challenges due to complex underwater acoustic phenomena, including blind zones, reverberation, and multipath effects4,5,6. Identifying target positions and types in sonar images requires specialized expertise, limiting detection efficiency and automation.
Side-scan sonar provides an intuitive representation of underwater objects' morphology and characteristics, offering wide detection coverage and instant results. However, target identification is entirely reliant on manual judgment, which is inefficient for long-distance operations. With the rapid advancement of computer vision, side-scan sonar image recognition technology has primarily focused on two approaches: traditional methods and deep learning techniques. Traditional methods rely on the statistical properties of sonar images, mathematical morphology processing, and pixel differences between frames to enhance target detection. In underwater target detection, Yang[7]used histograms of geometric features to calculate correlation coefficients of object attributes, facilitating clustering and improving performance. Lei8 applied a multi-feature fusion algorithm, based on particle swarm optimization for sonar image target detection. This algorithm optimizes the combination of multiple feature vectors, enabling adaptive feature selection. Luo9 applied mathematical morphology to side-scan sonar image processing, using structural elements to extract specific shapes. Experimental results show that this method effectively captures continuous, rough, and smooth feature edges. Kalyan10 employed CFAR technology for sonar target detection, comparing pixel gray levels to a threshold to address detection challenges. Two-stage object detection algorithms, such as R-CNN11, Fast R-CNN12 and Faster R-CNN13, first generate a series of candidate boxes, which are then classified by a CNN. Fang14 used a series of CNNs to extract image features and constructed an RPN to identify potential target regions. They proposed an optimized sonar image target detection method based on Faster R-CNN. Ma15 proposed a target detection method based on an optimized Faster R-CNN, introducing noise adversarial networks (NAN) to mitigate the significant impact of environmental noise on sonar image quality. Although this two-stage approach to target detection offers high accuracy, it suffers from poor real-time performance. The one-stage object detection methods, such as the YOLO and SSD series, directly return the category probability and position coordinates of objects16,17, making them faster than two-stage methods. Finally, the confidence parameter indicating target inclusion and the coordinate parameter describing the bounding box position are obtained. Manssor18 used the improved Tiny-YOLO-v3 model to design a method suitable for underwater small target detection. The problem of insufficient samples is addressed with by image denoising, and real-time performance issues are tackled by using a lightweight YOLO model. Fan19 applied the YOLOv4 model to underwater target detection in sonar images, improving the backbone network to address slow speed caused by the large number of parameters and depth. Yu20 proposed an underwater target detection algorithm, TR-YOLO-v5 based on YOLO-v5 for side-scan sonar images. By introducing attention mechanism and adding Transformer module, it adapts to the characteristics of sparse targets and poor sonar image features, improving detection accuracy. In summary, it can be seen that at present, for the existence of underwater building diseases or navigational obstacles, it mainly relies on manual judgment, which is limited by the subjective judgment of personnel experience. Traditional methods can utilize the mathematical and statistical properties of sonar images, mathematical morphological processing, and pixel differences between image frames to achieve more effective target detection, but there are great limitations in its accuracy and speed; target detection based on deep learning has become a mainstream method due to its significant superiority in accuracy and speed. Deep learning based target detection methods are divided into one stage and two stages, the one stage model is lighter and faster, and the two stage model is more accurate. The current research difficulties of sonar image target detection based on deep learning include low accuracy, poor real-time performance and low accuracy of small target detection, which is related to the complexity of underwater environment and the particularity of sonar imaging. Although these methods can be well applied to simple or obvious target discrimination, they are affected by the sonar image quality and the performance of the feature extraction algorithm model for complex targets. There are problems such as difficulty in feature design, large amount of redundancy, poor generalization robustness, and detection speed that cannot meet real-time requirements.
To overcome the challenges in side-scan sonar image target recognition and meet engineering application needs, a deep learning-based detection method has been developed, enhancing the one-stage YOLOv5 model. First, the bidirectional feature pyramid network (BiFPN) enhances feature fusion, thereby improving the accuracy of small target recognition. Second, the coordinate attention (CA) module is introduced to focus attention on key areas, reducing interference from complex underwater backgrounds. Next, EIoU is adopted as the frame loss function to accelerate network convergence and address the imbalance between hard and easy samples. Finally, the original convolution module in the backbone is replaced by the Ghost convolution module, reducing both computational complexity and model complexity. This approach enhances the model's detection speed and accuracy, effectively addressing issues of missed detection, false detection, and small target loss in underwater environments.
Data acquisition and pre-processing
Underwater disease target image acquisition
In channel measurement operations, side-scan sonar systems are typically deployed on unmanned vessels or operational ships, as illustrated in Fig. 1. Made by ArcMap using China map data from the standard map service system of the Ministry of Natural Resources of China (http://bzdt.ch.mnr.gov.cn/) and the survey data of this study. As the vessel moves, the side-scan sonar continuously transmits and receives acoustic waves, generating echo intensity images that vary with time and position. These images are subsequently used to analyze the characteristics of underwater targets within the channel. Currently, there is a scarcity of side-scan sonar images of underwater targets in waterways that utilize deep learning methods, and no open-source datasets of high-quality side-scan sonar images with annotated targets exist. Therefore, it is necessary to first organize and preprocess the raw side-scan sonar data. The experimental dataset in this study consists of 300 side-scan sonar images containing target objects, collected through collaborative efforts and field scanning of channels in Northern Zhejiang. Additionally, a web crawler was employed to collect and filter side-scan sonar images that met the study's criteria, expanding the dataset to a total of 626 images.

Channel side sweep equipment and location (Image by Tao Yu used the ArcMap 10.8.2:https://www.esri.com/).
Dataset produced
This project’s training dataset consists of 1,663 sonar images obtained through channel scanning and data scraping, including 1049 shipwrecks, 358 drowned people, and 256 broken revetments. The target sample dataset is randomly split into a training set and a validation set based on a specified proportion. A larger training set typically results in more accurate network model parameters. To better verify the algorithm model's generalization performance, this study divides the dataset into a training set and a validation set at a ratio of 0.8:0.2. The K-means algorithm calculates the center point and size of the annotation boxes. LabelImg was used to annotate the training samples within the acquired images. This experiment aims to detect wrecks, human bodies, and revetment damage. As a result, labels for ship, person, and revetment were created, as shown in Fig. 2.

Data label making diagram.
Data augmentation
To increase the diversity of shipwreck targets in samples and at various imaging positions, data enhancement operations are performed on the acquired images. This helps the convolutional neural network model better learn target characteristics in different environments and prevents overfitting. Due to the complexity of the underwater environment, the imaging resolution of side-scan sonar is influenced by factors such as range, power, track, and water conditions. Gaussian noise is added to more accurately simulate the actual channel scanning environment. The original images undergo geometric transformations, including random angle rotation, random cropping, and mirroring, to improve data stability. The enhanced side-scan sonar image with the target is shown in Fig. 3.

Dataset image after data enhancement.
Improved YOLOv5 model construction
YOLOv5 algorithm
YOLOv5 is a single-stage target detection algorithm that incorporates the strengths of various advanced network structures, offering higher accuracy and faster speed than its predecessors. It is capable of real-time target detection. There are four commonly used versions of YOLOv5. YOLOv5s21, with its concise network structure, offers the fastest running speed, minimal computing resource consumption, and easier portability to other platforms. Considering the application scenarios and engineering deployment requirements, this study selects the YOLOv5s model due to its shallow depth and width. The network structure is illustrated in Fig. 4.

YOLOv5s network structure diagram.
The original 640 × 640 × 3 video stream frame is input into the Focus structure, where slicing transforms it into a 640 × 640 × 3 feature map. After applying 32 convolution kernels, it becomes a 320 × 320 × 32 feature map, as shown in Fig. 4. The backbone network, consisting of the new Focus module, CBL convolution layer, and CSP1_X module, deepens the network layers to obtain richer semantic feature maps, effectively preventing gradient vanishing or exploding problems. In the Neck network, two up-samplings are performed, using the CSP2 and FPN + PAN structures to fuse shallow and high-level semantic features as well as multi-scale receptive fields, thereby fully utilizing detailed features from the shallow network. The detection head employs a regression and classification approach, dividing the input image into grids of 80 × 80, 40 × 40, and 20 × 20, respectively, to detect large, medium, and small targets.
Algorithm improvement strategy
Currently, side-scan sonar target detection is primarily used for underwater search and rescue, sediment search, and obstruction detection. In actual underwater search tasks, the size of various types of sediments differs, affecting their proportion in sonar images. Thus, the detection algorithm must achieve high-precision detection for targets of varying scales. Additionally, prolonged sediment deposition, like the degradation of underwater wreckage, often causes the wreckage to closely resemble the bottom geology in side-scan sonar images. This situation introduces significant background interference, leading to frequent missed and false detections by the algorithm. Existing side-scan sonar detection algorithms have limited feature extraction and discrimination abilities, failing to adequately address missed and false detection issues. Although the YOLOv5s algorithm effectively extracts image features and detects targets, the complex underwater environment of inland waterways demands higher speed and accuracy for identifying and detecting underwater anomalies.
To address the issues of low detection accuracy and poor generalization in detecting underwater anomalies using side-scan sonar, an improved YOLOv5-based detection algorithm is designed. First, the original Backbone convolution module is replaced by the Ghost convolution module to reduce the model's computational complexity. Second, the Bi-directional Feature Pyramid Network (BiFPN) is employed to enhance feature fusion and improve small target recognition accuracy. Next, the coordinate attention (CA) module is introduced to focus attention on key areas, reducing background interference in the underwater environment. Finally, EIoU is adopted as the bounding box loss function to accelerate network convergence and address sample imbalance between hard and easy examples.
Bidirectional feature pyramid network (BiFPN)
In the feature pyramid structure, deep feature maps carry more information beneficial for distinguishing object categories, while shallow feature maps provide more accurate object location information. The classical FPN transmits deep semantic information from top to bottom during target detection and makes predictions by fusing multi-layer feature information. However, due to the limitation of one-way information flow, some shallow location information may be lost during transmission, leading to a need for improved detection accuracy. The Neck of the original YOLOv5 model combines FPN with PAN, establishing a bottom-up path aggregation network through PAN to integrate with FPN. This fusion of feature information preserves both deep semantic and shallow location information, enhancing the detection accuracy of multi-scale targets without increasing network computation.
Detection targets such as underwater wrecks, human bodies, and revetment damage vary in size and present complex backgrounds, necessitating higher accuracy and speed in detection. This study employs the weighted bidirectional feature pyramid (BiFPN)22 structure to enhance the Neck component of the original model. The structure is illustrated in Fig. 5. BiFPN first simplifies the PAN structure. Nodes with only a single output or input edge are present at the top and bottom layers. These nodes, which lack feature fusion, contribute minimally to the network and can thus be removed, with their connections replaced by direct links between adjacent nodes. At each level, a horizontal connection between the original input node and the output node is introduced. This addition fuses more features with minimal computational cost and mitigates information loss due to increased network depth. Most notably, BiFPN treats the two-way path in PAN as an independent feature network layer that can be iterated to achieve advanced feature fusion.

BIFPN network structure diagram.
Add coordinate attention mechanism (CA)
In order to avoid the lack of feature extraction ability caused by the use of the BiFPN network, the attention mechanism is combined with the YOLOv5 backbone network. The SE attention mechanism only focuses on the interdependence between channels and ignores the spatial information. The CBAM23 mechanism considers both channel and spatial information, but only captures local information. Therefore, we introduce the CA mechanism24, which can better capture the relationship between channels and the remote dependencies with accurate location information. The CA mechanism structure is shown in the Fig. 6, and the attention mechanism is decomposed into two parallel (x and y directions) one-dimensional feature coding processes. In this way, long-distance dependencies can be captured along one direction, and accurate location information can be retained along the other direction, which can effectively aggregate spatial coordinate information into the generated attention map.

CA structure diagram.
Loss function EIOU
This paper enhances detection accuracy by refining the loss function. The original YOLOv5s model employs the CIoU (Complete IoU) loss function during training. CIoU (Complete Intersection over Union) is an enhanced IoU metric that considers the relationships among the position, shape, and size of the bounding box. However, CIoU has limitations in specific scenarios. For instance, when the target undergoes scale changes or has a large aspect ratio—characteristics present in the shipwreck dataset—CIoU may not accurately measure bounding box overlap, affecting detection accuracy. CIoU may fail to accurately measure bounding box overlap, impacting shipwreck target detection accuracy. To address CIoU’s limitations, this paper employs the enhanced bounding box loss function EIoU. The EIoU loss function separates the aspect ratio loss term into the difference between the predicted and minimal bounding box dimensions, which accelerates convergence and improves regression accuracy, resolving the aspect ratio ambiguity present in CIoU25. Figure 7 illustrates the iteration of CIoU and EIoU loss functions during the bounding box regression process. The red and green boxes represent the iterative process of the predicted box, the blue box denotes the ground truth box, and the black box represents the preset anchor box. The diagram shows that EIoU addresses the issue where CIoU's width and height cannot be adjusted simultaneously during the regression process. The EIoU loss function consists of three components: IoU loss, distance loss, and height-width loss (including overlapping area, center point, and height-width ratio), defined as follows.

Iteration diagram of CIOU and EIOU loss function.
Among them, wc and hc are the width and height of the minimum circumscribed rectangle of the predicted bounding box and the real bounding box. ρ is the Euclidean distance between two points.
Ghost convolutional network
In order to further compress the size of the YOLOv5s model, it is convenient for the later model to be deployed on hardware devices with limited computing resources. In this paper, GhostConv26 is used as the convolution layer in the Backbone and Head to replace the original ordinary convolution. GhostConv divides the convolution operation into two steps: a small amount of convolution and a lightweight linear transformation operation, as shown in Fig. 8. A small amount of convolution is used to reduce the number of convolution kernels of ordinary convolution operations to 1/2 of the original, thereby reducing the amount of calculation by 1/2. Lightweight linear transformation performs convolution with a convolution kernel of 3 or 5 one by one on the feature maps extracted by the first step. Finally, the feature maps obtained by the above two steps are spliced to generate the final feature map, and the feature map equivalent to the ordinary convolution is obtained, which can reduce the number of parameters without affecting the performance of the network in extracting features.

Ghost lightweight convolution.
Improved YOLOv5 algorithm structure
Underwater targets occupy only a few pixels in the image. Feature extraction for these targets is more challenging compared to other targets. This raises higher accuracy requirements for the detection algorithm. This raises higher requirements for the accuracy of the detection algorithm. To enhance model accuracy, this project refines the YOLOv5s model, focusing on underwater targets in channel environments. The improvements to YOLOv5s, based on the preceding description and experimental results, are outlined as follows Fig. 9. In the multi-scale detection phase, the PANet structure is replaced with the more accurate BiFPN structure to improve detection accuracy for underwater targets at various scales. To improve feature extraction, the Coordinate Attention mechanism is incorporated and combined with the C3 module. While enhancing detection accuracy, it is also crucial to consider model parameter quantity and inference speed to ensure a lightweight design. Therefore, this project introduces the GhostConv convolution module and designs the Ghost bottleneck, applying them to the Neck network to reduce model parameters. Finally, the loss function is replaced to achieve more accurate bounding box regression and target detection.

Improved YOLOv5s network structure diagram.
Test and result analysis
Model training
The image recognition system operates on a PC terminal. During training, images of size 640 × 640 are uniformly input. The model is configured with a momentum coefficient of 0.937, a weight decay factor of 0.0005, a learning rate of 0.01, a batch size of 128, and a total of 300 training epochs. The training environment is detailed in Table 1, and the identification process is illustrated in Fig. 10.

Flow chart of sonar image target recognition.
Evaluation index analysis
In order to evaluate the effectiveness of the underwater target detection model in this paper, three factors need to be considered: the accuracy of the classification (P, R, mAP)27, the processing speed and complexity of the model (FPS, model size, number of parameters, and computation). Among them, the detection accuracy (P) and the detection rate (R) are calculated as follows:
In the formula, TP represents the number of true positive predictions, FP represents the number of false positive predictions, and FN represents the number of false negatives. The pre-tests indicate that both precision (P) and recall (R) improve with the number of iterations, stabilizing after more than 200 iterations. The formula for calculating mean average precision (mAP) is as follows:
The above three metrics are evaluated for accuracy, and the recognition speed is also an important evaluation metric in target detection. The frame rate FPS, as an important index of detection speed, indicates the number of frames of the image transmitted in one second. FPS is defined as follows:
In the formula, “Inference Time per Frame (s)” is the time required for inference per image frame in seconds. The smaller the value, the higher the FPS, indicating a faster model.
Analysis of effect
Ablation experiment
To verify the theoretical improvements in accuracy and inference speed provided by the weighted bidirectional feature pyramid network (BiFPN), the collaborative attention mechanism (CA), and the loss function EIoU, as well as the potential speed benefits of the Ghost convolution module, we designed six groups of ablation experiments. The model's accuracy is evaluated using precision (P), recall (R), and mean average precision (mAP). Inference speed is assessed by seven parameters: frame rate (FPS), model size, number of parameters, and computational complexity. The experimental results for each module are shown in Table 2 below.
Analysis of the experimental accuracy (P), recall rate (R), and mAP@0.5 change curve (Fig. 11), along with the results from the experimental results table, shows that the new model incorporating the BiFPN module, CA attention mechanism, Ghost convolution network, and EIoU loss function significantly enhances both detection accuracy and speed. Specifically, precision (P), recall (R), and mAP@0.5 increased by 1.3%, 13.1%, and 6.2%, respectively. Concurrently, the model weight, number of parameters, and computational complexity decreased by 14.3%, 14.3%, and 25.9%, respectively. These improvements indicate that the enhanced YOLOv5s model offers better detection accuracy and speed.

P, R and mAP@0.5 change curves of YOLOv5s algorithm and improved algorithm.
Robustness
Figure 12 illustrates the change curves of box_loss, obj_loss, and box_loss during the 300 epochs of training on the target dataset for both the YOLOv5s network and the improved algorithm. Comparing Fig. 12a, b, it is evident that the box_loss for the YOLOv5 model on the training set decreased from 0.029 to 0.026 with the improved model, while the obj_loss decreased from 0.013 to 0.011 and the box_loss decreased from 0.00124 to 0.00104. Similarly, Fig. 12c, d show that on the validation set, the YOLOv5 model’s box_loss decreased from 0.036 to 0.033 with the improved algorithm, obj_loss decreased from 0.0055 to 0.0053, and box_loss decreased from 0.00199 to 0.0015. Lower loss values indicate better model robustness, suggesting that the improved model is more robust than the YOLOv5s model.

Comparison of model training results.
In summary, models with more complex structures and parameters require longer training times, result in heavier weights post-training, and decrease the frames per second (FPS) for detection, which can hinder engineering deployment and application. The improved YOLOv5s model outperforms the original YOLOv5s in detection performance, robustness, and training efficiency. Despite being slightly larger in FPS by 0.1 ms, this difference has a negligible impact on model performance. Thus, the improved model demonstrates better feasibility for underwater target detection, offering faster detection speed and a lighter model while maintaining higher accuracy.
Experimental comparison of different target detection models
In further verification of the effectiveness of the improved models in this paper, the improved algorithms in this paper are compared and trained with mainstream target detection models, such as Faster-RCNN, SSD, YOLOv4, YOLOv7, etc., in the same environment. The dataset is substituted into each of the six models for 300 rounds of training, and the training result parameters of the six models are shown in Table 3, The mAP@0.5 comparison for each model during the training process is shown in Fig. 13.

Map comparison results of each model for the training process.
The average precision mean mAP@0.5 of the YOLOv5s-GBCE model was 8.5, 9, 37.9, 5.2, and 4.7 percentage points higher than that of the other five models, respectively. The model weight sizes were reduced by 96, 79.6, 232, 2, and 59.2 M, and the frame rate FPS compared to Faster-RCNN, SSD, YOLOv4, and yolov7 by 50.3, 15.55, 34.2, and 49.84 frame. The single-stage detection network model YOLOv4 has the lowest model recognition accuracy, the two-stage detection model Faster-RCNN has the slowest inference speed, and the average accuracy and inference speed of YOLOv7 are both improved compared to the maximum of Faster-RCNN and YOLOv4, but it is still cannot meet the real-time detection of underwater diseases. The improved YOLOv5s-GBCE model has the highest P, R, and mAP@0.5 and the smallest model weight, and although the inference speed is slightly lower than the original YOLOv5s model, it still meets the requirements for real-time detection of underwater diseases.
To further verify the excellence of YOLOv5s-GBCE model, a wreck image with a complex background and small target features is selected as the detection object, and six algorithms are compared and analyzed. The detection results are shown in Fig. 14, where it can be seen that there is a misdetection phenomenon in Faster-RCNN, and the detection performance of YOLOv4 is the worst. The improved algorithm YOLOv5s-GBCE in this paper has the highest confidence and the best detection performance, indicating that the added CA attention mechanism and BiFPN provide better detection ability for underwater diseases.

Effectiveness of different algorithms in detecting shipwreck targets.
Analysis of different scene detection results
Detection of categories
This project focuses on detecting three types of targets in side-scan sonar images: shipwrecks, human bodies, and revetment damage. The scales of these targets vary significantly. Shipwrecks and human bodies appear larger in side-scan sonar images but may suffer from background interference due to deposition. Conversely, revetment damage is smaller and represents a typical small-target detection challenge. Table 4 below presents the precision (P), recall (R), and mean average precision (mAP@0.5) for these targets as obtained from the training conducted in this project.
The detection performance of the improved YOLOv5s algorithm is compared with that of the original YOLOv5s. The comparison of detection results for each category is illustrated in Fig. 15.

Side-scan sonar image effect diagram of various types of detection.
Figure 15 displays four types of original side-scan sonar images, along with detection results from both the original YOLOv5s algorithm and the improved algorithm. As shown in Fig. 13, the original side-scan sonar images contain significant noise. The original YOLOv5s algorithm often misidentifies background noise as small targets when detecting human targets. Additionally, it tends to miss targets that are similar to the background. Overall, the original YOLOv5s algorithm struggles with accurate target positioning due to noise and background similarity, resulting in missed or false detections and poor overall performance.
The integration of the improved YOLOv5s with a transfer learning algorithm has significantly enhanced overall detection accuracy. The improved algorithm more effectively integrates target feature information with its corresponding shadow features in side-scan sonar images. Consequently, as shown in Fig. 15, the enhanced algorithm suppresses the influence of bright spots without shadow features and avoids false detections. It accurately identifies targets that are often missed, including those in images with shipwrecks and small targets. Figure 15 further illustrates that the improved YOLOv5s algorithm excels in detecting various target types, demonstrating strong performance across different scales and making it highly suitable for side-scan sonar image target detection.
Background approximate target detection
A major challenge in side-scan sonar target detection is background interference, particularly with targets that have been deposited on the riverbed or seabed for extended periods. These targets often blend with the background, making their contours indistinct and leading to missed detections. To address this issue, Chapter 5 of this project proposes enhancing the YOLOv5s model by incorporating the Coordinate Attention (CA) mechanism. This approach reduces background interference and effectively mitigates the problem of missed detections for targets that closely resemble their background.
Figure 16 illustrates that for shipwrecks with prolonged underwater settlement, the target closely resembles the surrounding background, and its shadow characteristics are not well-defined. The original YOLOv5s algorithm struggles to differentiate such targets from the background, leading to missed detections. The improved algorithm proposed in this project addresses this issue by incorporating the Coordinate Attention (CA) mechanism and the EIoU loss function. As demonstrated in Fig. 16, this enhanced algorithm effectively detects targets even when they have blurred contours and are similar to the background.

Effect picture of background approximate target detection in side-scan sonar image.
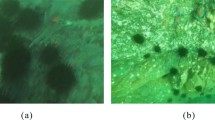
Small target detection
Detecting small targets in side-scan sonar images presents a significant challenge due to their limited size and minimal pixel representation. Accurate detection of these small targets demands high algorithmic precision. In this project, the Neck component of the YOLOv5s model is enhanced by incorporating the Weighted Bidirectional Feature Pyramid Network (BiFPN) structure, as detailed in Chapter 5, and employing the EIoU loss function. These improvements effectively address the challenge of detecting small targets with greater accuracy. The results of this enhancement in small target detection are illustrated in Fig. 17.

Small target detection effect of side-scan sonar image.
In Fig. 17, Panel (a) shows the original side-scan sonar image with small targets, Panel (b) displays the detection results of the YOLOv5s algorithm, and Panel (c) presents the detection results of the improved YOLOv5s algorithm. The comparison reveals that the improved algorithm introduced in Chapter 2 significantly enhances the accuracy of small target detection in side-scan sonar images. The proposed algorithm effectively identifies and marks the bounding boxes for small targets. It also addresses the issue of missed detections observed with the unimproved algorithm. These improvements are attributed to the optimized Neck network, which better captures the feature information of small targets, and the use of EIoU in place of the traditional CIoU loss function, leading to substantial improvements in small target detection.
Conclusion
-
(1)
To address the issues of low detection accuracy and poor generalization ability of underwater target detection in side-scan sonar images for inland waterways, a side-scan sonar image target detection algorithm based on an improved YOLOv5s model is developed. This algorithm incorporates the Ghost convolutional network, weighted bidirectional feature pyramid network (BiFPN), collaborative attention mechanism (CA), and the EIoU loss function.
-
(2)
Experimental results on the collected dataset show significant improvements in both detection accuracy and speed with the new model. Specifically, the precision (P), recall (R), and mean average precision at IoU 0.5 (mAP @ 0.5) increased by 1.3%, 13.1%, and 6.2%, respectively. Additionally, the model’s weight, number of parameters, and computational requirements were reduced by 14.3%, 14.3%, and 25.9%, respectively. This demonstrates that the improved YOLOv5s model achieves higher detection accuracy and faster detection speed.
-
(3)
Analysis of the comparative detection results indicates that the improved YOLOv5s method proposed in this paper effectively achieves accurate detection of targets, including small and overlapping ones that are similar to the background in side-scan sonar images. It avoids missed and false detections and does not suffer from detection frame loss. This enhancement significantly improves the accuracy of target detection in side-scan sonar images for underwater targets in inland waterways.
Data availability
The datasets used and analysed during the current study available from the corresponding author on reasonable request.
References
Ojo, E. P. et al. Assessment and characterization of woji creek riverbed in port harcourt, rivers state, Nigeria, utilizing side scan sonar technology. J. Eng. Res. Rep. 25(11), 31–38. https://doi.org/10.9734/JERR/2023/V25I111018 (2023).
Bodine, S. C. et al. PING-mapper: Open-source software for automated benthic imaging and mapping using recreation-grade sonar. Earth Space Sci. https://doi.org/10.1029/2022EA002469 (2022).
WonKi, K. et al. Neural network-based underwater object detection off the coast of the Korean Peninsula. J. Mar. Sci. Eng. 10(10), 1436–1436. https://doi.org/10.3390/JMSE10101436 (2022).
Yang, D. et al. Side-scan sonar image matching method based on topology representation. J. Mar. Sci. Eng. 12(5), 782. https://doi.org/10.3390/JMSE12050782 (2024).
Lakshmi, D. M. & Murugan, S. S. Contrast improvement on side scan sonar images using retinex based edge preserved technique. Mar. Geophys. Res. https://doi.org/10.1007/S11001-022-09478-W (2022).
Zhe, C. et al. Underwater sonar image segmentation combining pixel-level and region-level information. Comput. Electric. Eng. https://doi.org/10.1016/J.COMPELECENG.2022.107853 (2022).
Yang, F., Du, Z. & Wu, Z. Object recognizing on sonar image based on histogram and geometric feature. Mar. Sci. Bull. 25(5), 64. https://doi.org/10.1111/j.1745-4557.2006.00081.x (2006).
Hongquan, L., Diquan, L. & Haidong, J. Multi-feature fusion sonar image target detection evaluation based on particle swarm optimization algorithm. J. Intell. Fuzzy Syst. 46(1), 739–751. https://doi.org/10.3233/JIFS-234876 (2024).
Luo, J., Jiang, J. & Zhu, P. Automatic extraction of the side-scan sonar imagery outlines based on mathematical morphology. Haiyang Xuebao 38(5), 150–157 (2016).
Kalyan, B., Balasuriya, A. Sonar based automatic target detection scheme for underwater environments using CFAR techniques: A comparative study. In Proceedings of the 2004 International Symposium on Underwater Technology(IEEE Cat. No. 04EX869) IEEE, https://doi.org/10.1109/UT.2004.1405465 (2005)
Girshick, R., Donahue, J., Darrell, T., et al. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. https://doi.org/10.1109/CVPR.2014.81 (2014)
Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision. https://doi.org/10.1109/ICCV.2015.169 (2015)
Ren, S. et al. Faster R-CNN: Towards real-time object detection with region proposal net-works. IEEE Trans. Pattern Anal. Mach. Intell. 39(6), 1137–1149. https://doi.org/10.1109/TPAMI.2016.2577031 (2017).
Fang, J., Wang, P. Target detection in sonar image based on Faster RCNN. In 2020 International Conference on Information Science, Parallel and Distributed Systems(ISPDS). https://doi.org/10.1109/ISPDS51347.2020.00013 (2020)
Ma, Q., Jiang, L., Yu, W., et al. Training with noise adversarial network: A generalization method for object detection on sonar image. In Workshop on Applications of Computer Vision. https://doi.org/10.1109/WACV45572.2020.9093467 (2020).
Redmon, J., Divvala, S., Girshick, R., et al. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. https://doi.org/10.1109/CVPR.2016.91 (2016).
Liu, W. et al. SSD: Single shot multibox detector 21–37 (Springer, 2016). https://doi.org/10.1007/978-3-319-46448-0_2.
Manssor, F. A. S. et al. Real-time human detection in thermal infrared imaging at night using enhanced Tiny-yolov3 network. J. Real-Time Image Process. 19(2), 1–14. https://doi.org/10.1007/s11554-021-01182-z (2021).
Fan, X. et al. A novel sonar target detection and classification algorithm. Multimed. Tools Appl. 81(7), 10091–10106. https://doi.org/10.1007/s11042-022-12054-4 (2022).
Han, K. et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. https://doi.org/10.1109/TPAMI.2022.3152247 (2022).
Mbouembe, T. et al. Accurate and fast detection of tomatoes based on improved YOLOv5s in natural environments. Front. Plant Sci. 14, 1. https://doi.org/10.3389/fpls.2023.1292766 (2024).
Liu, S. et al. EcoDetect-YOLO: A lightweight, high-generalization methodology for real-time detection of domestic waste exposure in intricate environmental landscapes. Sensors 24(14), 4666–4666. https://doi.org/10.3390/s24144666 (2024).
Praharsha, H. C. & Poulose, A. CBAM VGG16: An efficient driver distraction classification using CBAM embedded VGG16 architecture. Comput. Biol. Med. 180, 108945–108945. https://doi.org/10.1016/J.COMPBIOMED.2024.108945 (2024).
Fu, T. et al. DCANet: CNN model with dual-path network and improved coordinate attention for JPEG steganalysis. Multimed. Syst. 30(4), 230–230. https://doi.org/10.1007/s00530-024-01433-6 (2024).
Jiuxin, W. et al. Small target detection algorithm based on attention mechanism and data augmentation. Signal Image Video Process. 18(4), 3837–3853. https://doi.org/10.1007/s11760-024-03046-y (2024).
Ponduri, V. & Laavanya, M. Ensemble of ghost convolution block with nested transformer encoder for dense object recognition. Biomed. Signal Process. Control 88(PB), 105645. https://doi.org/10.1016/j.bspc.2023.105645 (2024).
Wang, W. et al. CenterNet-saccade: Enhancing sonar object detection with lightweight global feature extraction. Sensors 24(2), 665. https://doi.org/10.3390/s24020665 (2024).
Funding
2022 Science and Technology Plan Project of Zhejiang Provincial Department of Transportation (NO:202208); 2023 Provincial Research and Development Project of the Department of Science and Technology of Zhejiang Province (2023C04037).
Author information
Authors and Affiliations
Contributions
T.Y. prepared the full manuscript; Y.X. defined the research idea; J.L. provided the image dataset; W.Z. reviewed the full text; J.L. performed the numerical simulation experiments.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yu, T., Xie, Y., Luo, J. et al. Research on underwater disease target detection method of inland waterway based on deep learning. Sci Rep 15, 14072 (2025). https://doi.org/10.1038/s41598-025-98570-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-98570-3
