
Abstract
Recent advancements in large language models (LLMs) such as ChatGPT have been transforming the ways we approach science tasks, including data analysis, experimental design, writing, and literature review. However, due to the lack of specialized knowledge and inherent issues such as plagiarism and hallucinations (i.e., false or misleading outputs), it is necessary for users to verify the output information. To address these issues, prompt engineering has become a significant task. In this study, we evaluate the performance of different prompt styles for extracting information from literature abstracts and emphasize the importance of prompt engineering for such scientific tasks. The literature on white phosphor materials is used for this study due to the availability of important and quantitative information in the abstracts. Through detailed comparative and quantitative evaluation, we provide guidance on preparing suitable and effective prompts based on the types of information sought.
Similar content being viewed by others


Introduction
Artificial intelligence (AI) has significantly transformed science and engineering1,2,3,4,5,6,7,8. Among the many AI tools, ChatGPT has emerged as one of the most widely used, establishing a strong presence in these fields9,10. ChatGPT is OpenAI’s chatbot program based on a large language model (LLM). It can produce high-quality sentences that closely resemble human-generated ones and process large volumes of data more quickly and efficiently than humans11,12. However, some researchers have expressed concerns about ChatGPT’s limited specialized knowledge, which makes it improper to use ChatGPT in the scientific and engineering fields5,13,14. Nevertheless, several reports have indicated that ChatGPT can support researchers in tasks such as literature search, abstract writing, and organizing information from papers2,6,7,8,15,16. Despite its utility, there are risks associated with ChatGPT, including the potential for plagiarism and the generation of false or misleading information, known as “hallucination.“, which bothers users and has them double-check the output information15,17,18,19,20,21. Along with this, prompt engineering has become an important topic in minimizing these issues and enhancing the accuracy of extracted information22,23. A prompt is a set of sentences that establishes the context for the conversation and provides instructions regarding key information and the desired output format24. A well-crafted prompt bridges the gap between the user’s intent and the model’s understanding, enabling more accurate and relevant responses25. Various advanced prompting strategies and evaluation methods have recently been proposed26,27,28,29,30,31,32,33,34. However, despite the variety of prompting strategies explored in recent studies, practical approaches tailored for scientists – who may not be experts in LLMs but need to extract and refine scientific information accurately – have remained limited.
In this study, we evaluate the performance of different prompts designed for information extraction. We here use literature abstracts considering general situations where access to full texts is unavailable and select phosphor as the subject of the literature since important and quantitative information in this field, such as emission wavelength, correlated color temperature (CCT), and quantum efficiency (QE), is given in the abstracts. Phosphor is a material that emits light when excited by an external energy source, and recent research has focused on improving luminous efficiency and developing phosphors for white light-emitting diodes35,36. We test four different types of prompts for selected information and evaluate prompts by comparing them with pre-prepared answers. We also discuss the performance and limitations of the prompts with respect to the characteristics of the information. This study serves as a guideline for tailoring ChatGPT prompts for each purpose.
Methods

Workflow to assess the performance of ChatGPT’s information extraction using different prompts: (1) paper selection using Google Scholar (search keywords: “white”, “phosphor”, “tetragonal”, “single component”) and subsequent manual filtering process; (2) preparation of answer key (a table form) based on the titles and abstracts by a user; (3) execution of different ChatGPT prompts for preparing ChatGPT-generated answer keys; (4) comparison of the user-prepared answer keys with ChatGPT generated ones to evaluate the performance.
Workflow
Figure 1 depicts the workflow used in this study to evaluate the performance of different prompts designed for the information extraction task. We employed ChatGPT 3.5 and used the title and abstract of papers as input data. The papers were searched using Google Scholar with the keywords: “white,” “phosphor,” “tetragonal,” and “single component”. To streamline the evaluation process (see Evaluation section below), we restricted the publish year range from 2022 to 2023 and selected 52 papers after filtering out review papers, books, and duplicate papers. Eight types of information that are typically provided in the abstract of phosphor papers – host material, activator, emission wavelength, excitation wavelength, CCT, CRI (color rendering index), QE, and doping type – are selected, and we created an answer key table to evaluate the performance (see Table 1, and Table S1 in Supplementary Tables to access all information). We designed and tested four different types of prompts for information extraction (see Prompts section below). Note that due to the token limitation of ChatGPT, each prompt was executed with 10 rows of the paper table.
Prompt engineering
Figure 2 illustrates the four types of prompt styles in this study. Prompt 1 (Simple style) gives ChatGPT a task without any instruction about information. This prompt only involves the description of the ChatGPT’s task for extracting information and visualizing it in a tabular form. Prompt 2 (Instruction style) provides short instruction that helps ChatGPT perform the task as expected by users. Prompt 3 (Markdown table style) provides an example of an answer table in markdown table format without additional information – markdown table is a way to display data in a tabular format using plain text. Prompt 4 (Markdown table + Chain-of-Thought (CoT) hybrid style) consists of an outline of CoT reasoning complemented by an example table in markdown table format. Chain-of-thought reasoning is a prompting method that improves the quality of ChatGPT response by providing the process of reaching the answer step-by-step37. Note that due to the token limitation of ChatGPT, Prompt 4 was used to extract information on the doping type to see if low scores obtained with Prompt 1–3 could be improved. All text prompts are included in Supplementary Information (Figures S2–S5).

Four prompt designs for information extraction. (a) Simple (zero-shot) style prompt with minimal information provided. (b) Instruction style prompt with extraction instruction. (c) Markdown table style prompt with table format example provided. (d) Markdown table + Chain-of-Thought hybrid style prompt with table format example and Chain-of-Thought reasoning (see the main text for details).
Evaluation
The performance of the different prompts for the information extraction task was evaluated by directly comparing ChatGPT’s response table with the answer key table and quantified by score. For scoring, we used two methods. The first method is an objective scoreboard for evaluating ChatGPT’s ability to perform this task, and the other method further counts how ChatGPT was helpful to the user. Specifically, the first scoring method does not allow partial credit (referred to as the all-or-nothing method) and gives 1 point if the ChatGPT response exactly matches the answer key and 0 points if not. The second method allows for partial credit (referred to as the partial credit method) and gives less than 1 point for useful information, even if the ChatGPT response does not exactly match the answer key. In the same way as the all-or-nothing method, a point score of 1 point is given if the ChatGPT response exactly matches the answer key. If not, the scores are categorized into three levels – 0.7 points, 0.3 points, and 0 points – based on the degree of inaccuracy. We assign 0.7 points for answers that are correct except for minor mistakes, 0.3 points for answers that include some incorrect information, and 0 points for answers that do not match at all. Because we did not observe significant differences between the two scoring methods, we present only the scores obtained using the all-or-nothing scoring method for simplicity and consistency. A representative comparison of the two methods is provided in Supplementary Information (Figure S6), along with the complete scoring tables in Supplementary Table (Tables S2–S4).
Result and discussion

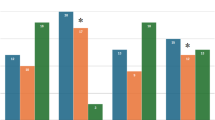
ChatGPT performance for information extraction. (a) Averaged scores of each prompt for extracting the eight types of information. Note that the hybrid style prompt (prompt 4) was applied only for extracting information on doping type due to the token limit of ChatGPT 3.5 (see the main text); it is thus not included in (a). (b) Detailed scores of each prompt for the different types of information (see also Table S4 in Supplementary Tables).
Figure 3a shows the average scores of each prompt for extracting the eight types of information. The scores of Prompts 1 and 2 indicate that providing additional instruction indeed improves ChatGPT’s performance in information extraction. It is worth noting that Prompt 3 achieves higher scores than Prompt 2 despite the absence of instruction, suggesting that providing only an example of the answer key helps ChatGPT perform the information extraction task effectively. The detailed scores for each type of information provide further insight into the strengths and limitations of each prompt (Fig. 3b). The overall scores were approximately 0.9 except for the three types of information: emission wavelength, excitation wavelength, and doping type, for which significant differences can be seen depending on the prompts. For emission wavelength and excitation wavelength, using Prompt 3 improves ChatGPT’s performance to 94.35%. We noticed that ChatGPT extracts an emission color instead of an emission wavelength when using Prompts 1 and 2 – for example, for article no. 39, Prompts 1 and 2 gave “green,” while Prompt 3 yielded “543 nm,” as desired. (see Table S2 in Supplementary Tables for details). This could be attributed to the ambiguity of inquiry. In both Prompts 1 and 2, although we ask ChatGPT to extract “wavelength,” it can be associated with specific colors. If the prompt explicitly requests a “value” of emission wavelength, the model is more likely to return wavelength information in terms of physical length. By simply providing an example of the answer key in nanometers, as given in Prompt 3, such ambiguity can be resolved. The different answers could also be due to errors in attention focus. ChatGPT is built on the transformer model based on the self-attention mechanism, which dynamically assigns importance to input tokens to build dependencies between inputs and outputs38,39,40. In other words, the self-attention mechanism in ChatGPT can align structured queries directly with relevant values, especially when examples are given. While Prompts 1 and 2 brought ChatGPT’s attention focus on the word “emission,” which allows extracting color information as the highest likelihood, Prompt 3, in which the “nm” unit is clearly stated, takes ChatGPT’s attention to the value of wavelength. The relatively high performance of Prompt 3 in extracting these types of information suggests providing an example of answer keys as a very simple but efficient prompting style for extracting and summarizing physical quantities from texts.
However, attention focus does not always work; rather, it leads to incorrect response. In the case of QE, although no information is provided in the abstracts of article no. 46 and 50, ChatGPT using Prompt 3 provides certain percentage values that are not related to QE but are other percentage values. We believe that the answer key provided in percentage in Prompt 3 directed attention to percentage values and led to finding any values given with percentage. We may avoid such an issue by adding and providing more example sets. In contrast, we included brief instructions about QE in Prompt 2, which reads, “Quantum Efficiency (QE) measures the luminescence efficiency of phosphors. It is defined as the ratio of the number of photons emitted by a phosphor to the number of photons absorbed by the phosphor.” This might have directed ChatGPT’s attention to the word “efficiency.” Interestingly, in the abstract of article no. 46, energy transfer “efficiency” is given in percentage, but the PL intensity ratio is given in percentage in the abstract of article no. 50 – Prompt 2 returned the wrong answer only for article no. 46. Such an issue is known as contextual understanding errors. ChatGPT may confuse related fields or misplace extracted values when the prompt does not provide sufficient reasoning guidance. These issues arise because the model lacks an explicit path of inference and instead relies on surface-level pattern matching within a given prompt.
It is noteworthy that Prompt 2 outperforms Prompt 3 by 71.41% in extracting doping-type information, i.e., the number of activator elements. The superior performance of Prompt 2, beyond Prompts 1 and 3, indicates that instruction is effective for certain types of information, which requires an additional reasoning and refinement process of ChatGPT. To improve the lower score and maximize the strengths of Prompt 3, we developed Prompt 4, which combines CoT reasoning and markdown table examples for each step. By incorporating CoT reasoning into the prompt, we provide a step-by-step context that helps guide the model to make more accurate and logically consistent extractions. As shown in Fig. 3b, Prompt 4 outperforms Prompt 2 by approximately 10% in extracting doping-type information. While Prompt 4 is effective for handling such types of information and avoiding contextual understanding errors, it requires additional effort to design and optimize compared to other prompt styles. Therefore, the hybrid prompting style can be selectively used for the information that necessitates a reasoning process. Table 2 summarizes the advantages and limitations of the four prompt styles discussed in this study.
Our study highlights the potential of ChatGPT for information extraction and underscores the importance of optimized prompt preparation considering the types of information. However, there are still issues that need to be addressed. For instance, an article discussed the use of a specific element as a sensitizer to enhance emission efficiency, but ChatGPT incorrectly identified the element as an activator, subsequently misclassifying the study as one on co-doped phosphors. This illustrates the need for prompt optimization when extracting information that requires specialized knowledge. Tailoring the prompt to provide clearer context and relevant details is crucial for guiding ChatGPT towards accurate interpretations. Additionally, conversational exploration – engaging in a step-by-step dialogue with ChatGPT – may further refine the prompt and lead to more precise results.
There may be concerns about the generalizability and applicability of this study since it focuses solely on the abstracts of literature on white phosphors. Although the topic may seem specific, our prompts were tested on various types of information, demonstrating their broader applicability. Notably, the prompt combining a markdown table with CoT reasoning (Prompt 4) indeed demonstrates the potential for effectively extracting information across scientific domains. This approach can also be applied to full-text documents, not just abstracts. While focusing exclusively on abstracts may appear limited, this study provides practical and promising strategies for extracting and organizing information from literature databases where only abstracts are available, such as Google Scholar or Web of Science. It can be applied to database construction, large-scale data analysis, statistical reviews, and machine learning.
Recent studies have shown that while larger and more refined LLMs are more accurate overall, they are also more likely to generate incorrect answers rather than avoid difficult questions21. This is because the models are optimized to produce plausible language, not to assess factual correctness. Users often fail to detect these incorrect responses, which can lead to an overestimation of the model’s capabilities. Our study also highlights the importance of prompt design by systematically evaluating different prompt styles and suggests that prompt engineering – tailored to the characteristics of the information – can help mitigate hallucination.
Although we suggest the markdown table + CoT reasoning prompt style as an effective approach for scientific tasks that require structured reasoning, we also emphasize the importance of having a certain level of prior knowledge for designing the reasoning steps and performing minimal cross-checking. Each individual may develop their own protocol for prompt design and evaluation.
Conclusion
We assessed how well ChatGPT performed when given different types of prompts by comparing its responses with pre-prepared answers. Our results show that using a markdown table format is simple and suitable enough for basic information extraction tasks. For information requiring more complex reasoning, a combination of a markdown table with chain-of-thought reasoning proves more effective. These findings provide valuable insight for creating and improving prompts for specific information extraction, and demonstrate the potential of ChatGPT as a versatile tool for various tasks in science and technology.
Data availability
All data generated or analysed during this study are included in this published article and its supplementary information files.
References
Sha, W. et al. Artificial intelligence to power the future of materials science and engineering. Adv. Intell. Syst. 2, 1900143 (2020).
Gao, C. A. et al. Comparing scientific abstracts generated by ChatGPT to real abstracts with detectors and blinded human reviewers. NPJ Digit. Med. 6, 75 (2023).
Pursnani, V., Sermet, Y., Kurt, M. & Demir, I. Performance of ChatGPT on the US fundamentals of engineering exam: comprehensive assessment of proficiency and potential implications for professional environmental engineering practice. Computers Education: Artif. Intell. 5, 100183 (2023).
Liu, Y. et al. Summary of chatgpt-related research and perspective towards the future of large Language models. Meta-Radiology, 1, 100017 (2023).
Agathokleous, E., Saitanis, C. J., Fang, C. & Yu, Z. Use of ChatGPT: what does it mean for biology and environmental science? Sci. Total Environ. 888, 164154 (2023).
Zheng, Z., Zhang, O., Borgs, C., Chayes, J. T. & Yaghi, O. M. ChatGPT chemistry assistant for text mining and the prediction of MOF synthesis. J. Am. Chem. Soc. 145, 18048–18062 (2023).
Zhang, X., Zhou, Z., Ming, C. & Sun, Y. Y. GPT-Assisted learning of Structure–Property relationships by graph neural networks: application to Rare-Earth-Doped phosphors. J. Phys. Chem. Lett. 14, 11342–11349 (2023).
Wang, S., Scells, H., Koopman, B. & Zuccon, G. in Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1426–1436 (2023)
Roumeliotis, K. I. & Tselikas, N. D. Chatgpt and open-ai models: A preliminary review. Future Internet. 15, 192 (2023).
Cheng, H. W. Challenges and limitations of ChatGPT and artificial intelligence for scientific research: a perspective from organic materials. AI 4, 401–405 (2023).
Herbold, S., Hautli-Janisz, A., Heuer, U., Kikteva, Z. & Trautsch, A. A large-scale comparison of human-written versus ChatGPT-generated essays. Sci. Rep. 13, 18617 (2023).
Wu, T. et al. A brief overview of ChatGPT: the history, status quo and potential future development. IEEE/CAA J. Automatica Sinica. 10, 1122–1136 (2023).
Wittmann, J. Science fact vs science fiction: A ChatGPT immunological review experiment gone awry. Immunol. Lett. 256, 42–47 (2023).
Castillo-González, W. The importance of human supervision in the use of ChatGPT as a support tool in scientific writing. Metaverse Basic. Appl. Res. 2, 29–29 (2023).
Huang, J. & Tan, M. The role of ChatGPT in scientific communication: writing better scientific review articles. Am. J. cancer Res. 13, 1148 (2023).
Alshami, A., Elsayed, M., Ali, E., Eltoukhy, A. E. & Zayed, T. Harnessing the power of ChatGPT for automating systematic review process: methodology, case study, limitations, and future directions. Systems 11, 351 (2023).
Jarrah, A. M., Wardat, Y. & Fidalgo, P. Using ChatGPT in academic writing is (not) a form of plagiarism: what does the literature say. Online J. Communication Media Technol. 13, e202346 (2023).
Chelli, M. et al. Hallucination rates and reference accuracy of ChatGPT and bard for systematic reviews: comparative analysis. J. Med. Internet. Res. 26, e53164 (2024).
Alkaissi, H. & McFarlane, S. I. Artificial hallucinations in ChatGPT: implications in scientific writing. Cureus 15, e35179 (2023).
Hanna, E. & Levic, A. Comparative analysis of language models: hallucinations in ChatGPT: Prompt Study. http://www.diva-portal.org/smash/record.jsf?pid=diva2%3A1764165&dswid=372 (2023).
Jones, N. Bigger AI chatbots more inclined to spew nonsense-and people don’t always realize. Nature. https://www.nature.com/articles/d41586-024-03137-3 (2024)
Polak, M. P. & Morgan, D. Extracting accurate materials data from research papers with conversational Language models and prompt engineering. Nat. Commun. 15, 1569 (2024).
Tang, Y. et al. Large Language model in medical information extraction from titles and abstracts with prompt engineering strategies: A comparative study of GPT-3.5 and GPT-4. MedRxiv 2024, 24304572 (2024)
White, J. et al. A prompt pattern catalog to enhance prompt engineering with chatgpt. arXiv preprint arXiv:2302.11382 (2023).
Ekin, S. Prompt engineering for ChatGPT: a quick guide to techniques, tips, and best practices. Preprint at https://doi.org/10.36227/techrxiv.22683919.v2 (2023).
Ye, Q., Axmed, M., Pryzant, R. & Khani, F. Prompt engineering a prompt engineer. arXiv preprint arXiv:2311.05661 (2023).
Wang, L. et al. Prompt engineering in consistency and reliability with the evidence-based guideline for LLMs. NPJ Digit. Med. 7, 41 (2024).
Velásquez-Henao, J. D., Franco-Cardona, C. J. & Cadavid-Higuita, L. Prompt engineering: a methodology for optimizing interactions with AI-Language models in the field of engineering. Dyna 90, 9–17 (2023).
Siino, M. & Tinnirello, I. in 2024 IEEE International Symposium on Measurements & Networking (M&N). 1–6 (2024).
Siino, M. & Tinnirello, I. GPT hallucination detection through prompt engineering. Proc. of the 25th Working Notes of the Conference and Labs of the Evaluation Forum 3740, 712–721 (2024)
Siino, M. & Tinnirello, I. Prompt engineering for identifying sexism using GPT mistral 7B. Proc. of the 25th Working Notes of the Conference and Labs of the Evaluation Forum 3740, 1228–1236 (2024).
Marvin, G., Hellen, N., Jjingo, D. & Nakatumba-Nabende J. in International conference on data intelligence and cognitive informatics. 387–402 (2024).
Chen, B., Zhang, Z., Langrené, N. & Zhu, S. Unleashing the potential of prompt engineering in large language models: a comprehensive review. arXiv preprint arXiv:2310.14735 (2023).
Arvidsson, S. & Axell, J. Prompt engineering guidelines for LLMs in Requirements Engineering. (2023).
Ye, S., Xiao, F., Pan, Y., Ma, Y. & Zhang, Q. Phosphors in phosphor-converted white light-emitting diodes: recent advances in materials, techniques and properties. Mater. Sci. Engineering: R: Rep. 71, 1–34 (2010).
Parauha, Y. R., Kohale, R., Joshi, M., Swart, H. & Dhoble, S. Review on advancements in white light phosphor matrices for energy-efficient lighting. Mater. Sci. Semiconduct. Process. 184, 108725 (2024).
Wei, J. et al. Chain-of-thought prompting elicits reasoning in large Language models. Adv. Neural. Inf. Process. Syst. 35, 24824–24837 (2022).
Luo, Q. et al. in 2023 IEEE 6th International Conference on Electronic Information and Communication Technology (ICEICT). 401–405 (2023).
Nakada, R., Ji, W., Cai, T., Zou, J. & Zhang, L. A Theoretical Framework for Prompt Engineering: Approximating Smooth Functions with Transformer Prompts. arXiv preprint arXiv:2503.20561 (2025).
Vaswani, A. et al. Attention is all you need. Adv. Neural. Inf. Process. Syst. 30, 5998–6008 (2017).
Acknowledgements
This work was supported by Regional Innovation Strategy (RIS) through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (MOE) (2023RIS-007). This work was also supported by the National Research Foundation of Korea Grant funded by the Korean Government (RS-2024-00358042) and the Ministry of Education (RS-2023-00248068).
Author information
Authors and Affiliations
Contributions
S.L. conceived the idea(s). Y.L. and S.L. designed the experiment(s). Y.L. J.H.O., and D.L. performed the data acquisition. Y.L., M.K., and S.L. wrote the manuscript. All authors revised the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Lee, Y., Oh, J.H., Lee, D. et al. Prompt engineering in ChatGPT for literature review: practical guide exemplified with studies on white phosphors. Sci Rep 15, 15310 (2025). https://doi.org/10.1038/s41598-025-99423-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-99423-9
